

用Apollo GraphQL和MongoDB Atlas构建现代应用栈
用传统架构提供新的应用体验是缓慢而痛苦的。许多组织投入大量资源,使他们的基础设施更具弹性和灵活性,但发现他们仍然无法以他们寻求的速度交付产品。API的复杂性意味着,前端和后端团队必须浏览分散的微服务、版本化的REST端点和复杂的数据库管理,而不是交付新的体验。本文解释了团队如何通过使用Apollo GraphQL和MongoDB Atlas降低复杂性。
GraphQL可以帮助团队将这些分散的REST API和微服务整合到一个统一的模式中,前端开发人员可以查询,只获取为体验提供动力所需的数据,同时对数据的来源不了解。
然而,通过一个单一的GraphQL服务器(读作:单体)来运行所有的东西,而多个团队快速地做出改变,这就造成了一个瓶颈。随着客户端设备、应用程序和开发人员数量的增加,API层的复杂性成倍增长--后端团队不能再自主地工作或按自己的发布时间表推送变化。
为了高效使用GraphQL,开发者需要:
-
统一的API,以便应用开发者能够快速创建新的体验
-
一个模块化的API层,因此每个团队都可以独立拥有自己的图块
-
一个无缝的、高性能的数据层,与API消费一起扩展
一个能够提供的应用栈
超级图是一个GraphQL API,旨在让前端和后端团队同时受益。它是一个统一的API层,由Apollo Federation构建,它是一个声明式、模块化的GraphQL架构。
与单一的模式不同,超级图由更小的图组成,称为子图,每个图都有自己的模式。团队可以独立地发展他们的子图,他们的变化将被自动卷进整个超级图中,使他们能够自主地、渐进地交付。
然而,超级图谱的效率取决于底层数据层的能力和可靠性。MongoDB Atlas--MongoDB的完全管理的开发者数据平台--带有这种承诺。它提供了一个灵活的文档模型,为开发者提供了一个直观的方式来处理GraphQL的嵌套数据结构,同时提供了一个可靠的数据层,可以在任何地方运行,在多个地区和云提供商之间部署,并且由于其分布式性质,可以水平扩展。
超级图谱和MongoDB Atlas共同创造了一个可组合的应用堆栈,消除了复杂性,使团队能够比以前更快地进行创新。
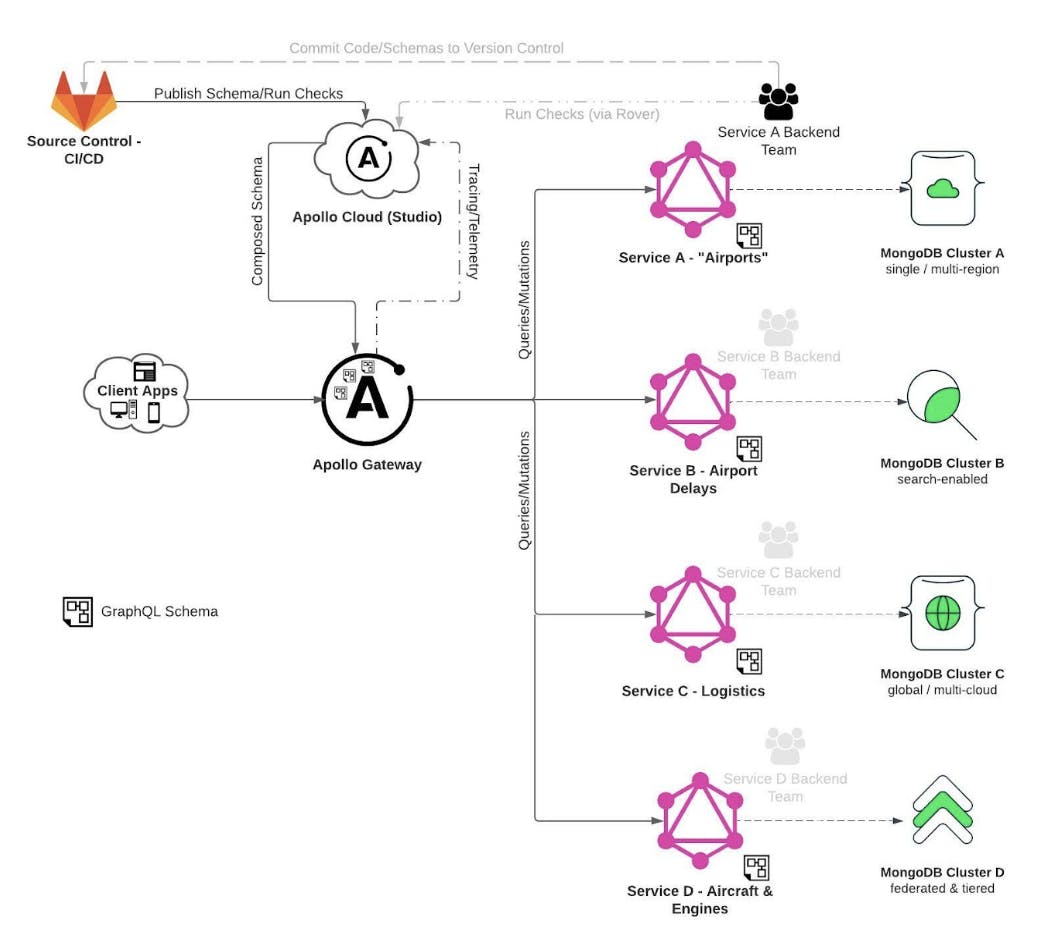
图1:使用Apollo Federation和MongoDB Atlas,通过可组合的超图和统一的数据访问层简化应用架构
应用开发体验
在打造新的应用体验时,开发人员希望浏览一个统一的模式,创建能够准确获取所需数据的查询,测量API性能,并在数分钟内使用API,而不是花费数天或数周时间,试图找到合适的API,单独缝合到每个Web、Android、iOS、平板电脑和手表应用中。然而,当应用程序不得不直接使用大量的REST API时,开发人员的体验和终端用户的性能就会受到影响。根据PayPal的数据,UI开发人员实际花费在构建UI上的时间不到三分之一。其余的时间都花在了如何获取数据、过滤/映射这些数据以及协调API调用上。
有了超级图谱,开发人员可以查询一个单一的GraphQL端点,以获取他们需要的所有数据,并发现、消费和优化,而不必浏览REST API和微服务的海洋。
有原则的GraphQL API的一个关键特征是一个抽象的、面向需求的模式,它提供了为客户体验提供动力所需的数据,并抽象了下面的微服务和数据层。
最强大的图作为现有微服务之上的门面,将低级别的后台领域模型抽象成一个精心策划的客户体验模型,提供用户界面中显示的高级信息。这种体验模型允许在网络、移动和可穿戴应用中实现一致的用户体验。
API开发体验
后台开发人员希望能够自由地自主构建和发展服务和能力。但当客户同时在消费服务时,这是一个很高的要求。在不引入破坏性变化的情况下进行重构几乎是不可能的,而要了解这些破坏性变化的影响则更难。其结果是,几乎任何对API的改变都需要与所有客户团队协调。
有了超级图谱和背后灵活的数据层,各团队可以独立地对模块化的子图进行修改,这些子图组成了整个超级图谱。Apollo Federation的声明式架构和强大的指令使团队在不破坏客户的情况下自主地工作。
选择正确的图原生数据层
构建一个可扩展的超级图,首先要选择正确的数据层来支持后端服务。在过去,关系型数据库需要ORM或手动将底层关系型格式映射到应用程序可以使用的对象/文档结构,如JSON。数据库提供的东西和客户应用程序需要的东西之间的阻抗不匹配导致了性能和维护问题,拖慢了应用程序的开发和应用程序的性能。
与关系型数据库相比,MongoDB的文档模型和GraphQL共享一个简单的嵌套数据结构,这意味着开发人员可以轻松地将它们结合起来使用,而不必将GraphQL映射到关系型数据并定义关系。Apollo Federation增加的可组合性让开发者可以在多个集合或数据库之间、在不同地区运行的单云和多云Atlas集群之间、甚至在Atlas和企业内部集群之间轻松实现联合。
通过这种方式,开发者获得了MongoDB文档模型的灵活性,以及在GraphQL模式上进行迭代的自由,其安全性和信心由自动模式检查来保证。
选择正确的子图架构
当涉及到选择如何将子图连接到数据层时,有几种选择。
传统的子图(微服务加数据库)
在许多环境中,现有的微服务、REST API和SOA服务已经在生产中存在多年了。子图(用20多种语言和框架中的任何一种编写)可以作为一个新的层添加到这些现有的微服务之上,并组成一个体验驱动的超级图,作为ViewModel后端,为Web、移动和可穿戴设备提供新的应用体验。这是一个非常有效和成熟的模式。
图形原生子图(直接到MongoDB)
当在绿地环境中添加新的子图或增加新的功能时,子图可以被设计成直接与数据库对话,中间没有微服务或REST APIs。这种方法并不总是正确的答案,特别是对于那些在后端已经标准化的REST或gRPC的公司。然而,这是一个更简单的设置,可以通过移除一个层来提高性能。
传统子图(微服务加MongoDB Atlas)
MongoDB Atlas是一个完全可管理的、多云、多区域的数据层,适用于传统微服务。通过16种语言的MongoDB官方驱动程序、完全管理的基于HTTPS的数据API或社区管理的ODM(如Mongoose)等选项,开发者有一系列选择,可以用Atlas构建其超图的数据层。开发人员可以灵活地选择一种路径,为他们提供一种习惯性的、熟悉的方式,以他们最熟悉的语言和开发风格与数据库进行合作。
MongoDB Atlas GraphQL API(托管子图API)
MongoDB Atlas的GraphQL API是基于底层数据库文档模式自动生成的,可以直接组成超图的一部分。选择这种方法的开发者可以减少编写自定义GraphQL解析器的时间,因为这些解析器是由MongoDB Atlas自动生成的。
当Mongo文档模型与查询形状密切匹配时--这是MongoDB等文档数据库中常见的范式--查询可以在没有转换或映射的情况下提供。这种设置也适用于不同集合中不同类型的文档之间的关系;因此,生成的GraphQL模式也将允许开发人员查询同一图中其他团队可能拥有的集合。
如果开发人员所需的查询形状与底层文档模型不同,例如在服务器驱动的用户界面(SDUI)模式中塑造模式时,他们可以利用@requires 模式指令,将多个文档字段拉入并转化为面向体验的属性,并由前端应用程序进行渲染。通过这种方式,开发人员可以在需要时从高效的数据访问和自定义模型映射中获益。
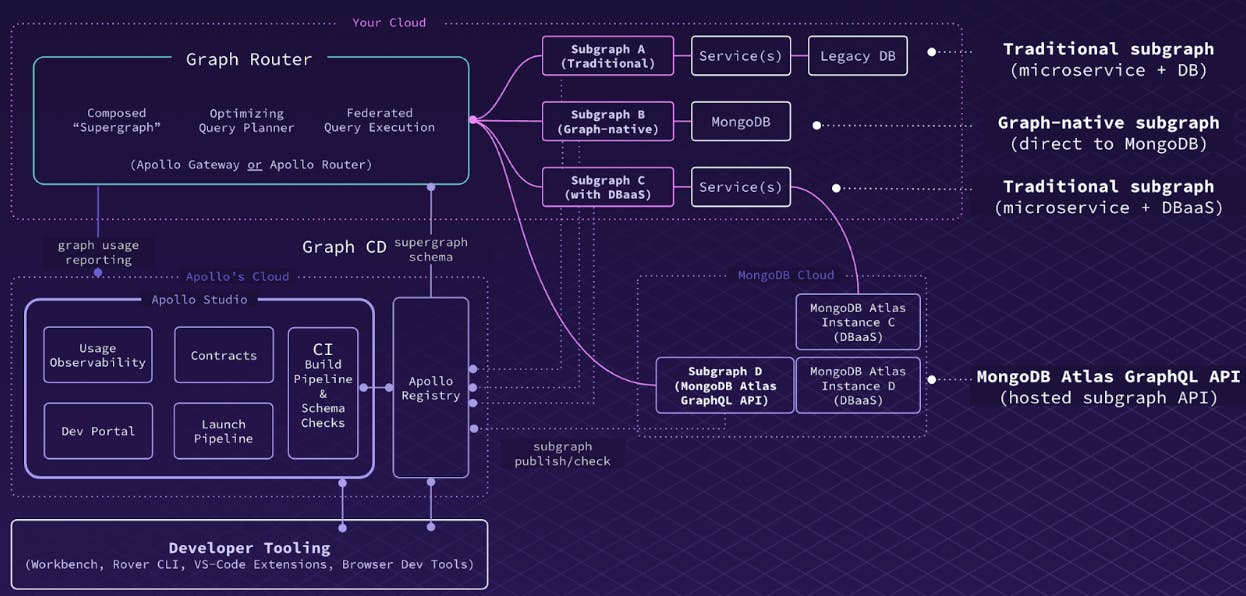
图2:用Apollo Federation、MongoDB的定制解析器和托管的MongoDB Atlas GraphQL API端点组成一个超级图谱。
用子图扩展业务用例
超图可以轻松地组成微服务,但当涉及到托管、管理和存储执行业务逻辑的数据时,MongoDB Atlas应用数据平台可以帮助团队更快地构建其应用需求。
需要一个搜索栏吗?存储在Atlas集群中的相同数据可以被搜索索引,并使用Atlas搜索来执行全文搜索操作,无需额外设置或将数据同步到另一个搜索技术。
想嵌入图形和图表?一个时间序列集合可以很容易地按时间戳查询大块数据,而MongoDB Atlas Charts让开发者使用相同的MongoDB数据库在应用程序内部构建这些数据。其他服务,如自定义数据API和数据联盟,有助于确保数据能够以最适合团队需求的方式被查询和存储。
专注于规模
工程团队需要能够预测当前和未来的需求。MongoDB Atlas提供了一个跨越多个地区、云和部署类型的应用数据平台,以解决事务性工作负载、现代应用程序和微服务的数据挑战。自愈集群确保开发人员不会争先恐后地诊断其数据节点的问题,而多区域和多云部署分别为两种模式提供自动故障转移。
Apollo和MongoDB共同致力于为开发者提供他们所需的有效工具,以简化他们的架构,提高应用性能,更快地出货,并发展他们的业务。
