

这是我参与「第四届青训营」笔记创作活动的的第11天
01LSMT与存储引擎介绍
LSMT的历史
- LSMT是 Log-Structured Merge-Tree的缩写,由Patrick O 'Neil etc.在1996年的论文,The Log-Structured Merge-Tree (LSM-Tree),提出。
- 相较而言,B-Tree出现就早得多了,在1970年由 Bayer, R.; McCreight,E.提出。
- 早期的数据库系统一般都采用 B-Tree家族作为索引,例如MySQL。2000年后诞生的数据库大多采用LSMT索引,例如Google BigTable,HBase,Canssandra等。
LSMT是什么?
存储引擎是什么?
-
以单机数据库MySQL为例,大致可以分为:
- 计算层
- 存储层(存储引擎层)
- 计算层主要负责SQL解析/查询优化/计划执行。
- 数据库著名的ACID特性,在MySQL中全部强依赖于存储引擎。
- ACID
-
除了保障ACID以外,存储引擎还要负责:
- 屏蔽IO细节提供更好的抽象
- 提供统计信息与Predicate Push Down能力
-
存储引擎不掌控IO细节,让操作系统接管,例如使用mmap,会有如下问题:·
- 落盘时机不确定造成的事务不安全
- IO Stall
- 错误处理繁琐
- 无法完全发挥硬件性能
02LSMT 存储引擎的优势与实现
LSMT与B+Tree的异同
- 在B+Tree中,数据插入是原地更新的
- B+Tree在发生不平衡或者节点容量到达阈值后,必须立即进行分裂来平衡
- LSMT与B+Tree可以用统—模型描述
- 从高层次的数据结构角度来看,二者没有本质的不同,可以互相转化
- 工程实践上还是用LSMT来表示一个 Append-only和Lazy Compact 的索引树,B+Tree来表示一个lnplace-Update和Instant Compact的索引树。
- Append-only和Lazy Compact这两个特性更符合现代计算机设备的特性。
为什么要采用LSMT 模型?
All problems in computer science can be solved by another level of indirection
- 在计算机存储乃至整个工程界都在利用Indirection处理资源的不对称性
- 存储引擎面对的资源不对称性在不同时期是不同的
HDD时代
- 顺序与随机操作性能不对称
- 由于机械硬盘需要磁盘旋转和机械臂移动来进行读写,顺序写吞吐是随机读的25倍。
SSD时代
- 顺序写与随机写性能不对称
- 由于SSD随机写会给主控带来GC压力,顺序写吞吐是随机写的6倍。
小结:
- HDD时代,顺序操作远快于随机操作.
- SSD时代,顺序写操作远快于随机写操作
- 这二者的共性是顺序写是一个对设备很友好的操作,LSMT符合这一点,而B+Tree依赖原地更新,导致随机写。
LSMT存储引擎的实现,以 RocksDB为例
- RocksDB是一款十分流行的开源LSMT存储引擎,最早来自Facebook (Meta),应用于MyRocks,TiDB等数据库。
- 在字节内部也有Abase,ByteKV, ByteNDB,Bytable 等用户。
- 因此接下来将会以 RocksDB为例子介绍LSMT存储引擎的经典实现。
LSMT存储引擎的实现- Write
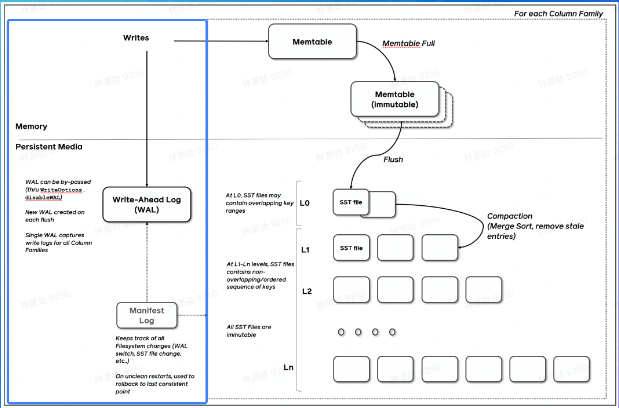
- RocksDB 写入流程主要有两个优化,批量WAL写入(继承自LevelDB)与并发MemTable更新
- RocksDB在真正执行修改之前会先将变更写入WAL,WAL写成功则写入成功。
- 多个写入者会选出一个 Leader,由这个Leader来一次性写入WAL,避免小 lO。
- 不要求WAL强制落盘(Sync)时,批量提交亦有好处,Leader可以同时唤醒其余Writer,降低了系统线程调度开销。
- 没有批量提交的话,只能链式唤醒。
- 链式唤醒加大前台延迟。
- 写完WAL还要写MemTable。
- RocksDB在继承LevelDB的基础上又添加了并发MemTable写入的优化。
- WAL 一次性写入完成后,唤醒所有Writer并行写入 MemTable
- 由最后一个完成 MemTable 写入的Writer执行收尾工作
Snapshot & SuperVision
- RocksDB的数据由3部分组成,MemTable/ lmmemTable / SST。持有这三部分数据并且提供快照功能的组件叫做SuperVersion。
- MemTable和 SST的释放依赖于引用计数。对于读取来说,只要拿着SuperVersion,从MemTable一级一级向下,就能查到记录。拿着SuperVersion不释放,等于是拿到了快照。
- 如果所有读者都给SuperVersion 的计数加1,读完后再减1,那么这个原子引用计数器就会成为热点。CPU在多核之间同步缓存是有开销的,核越多开销越大。
- 为了让读操作更好的scale,RocksDB做了一个优化是Thread Local SuperVersionCache
- 没有Thread Local缓存时,读取操作要频繁Acquire和 Release SuperVersion
- CPU 缓存不友好
- 有Thread Local 缓存,读取只需要检查一下SuperVersion并标记 ThreadLocal缓存正在使用即可
- CPU 缓存友好
Get & BloomFilter
.RocksDB的读取在大框架上和B+ Tree类似,就是层层向下。 ·相对于B+Tree,LSMT点查需要访问的数据块更多。为了加速点查,一般LSMT引擎都会在SST中嵌入BloomFilter。 [1,10]表示这个索引块存储数据的区间在1-10之间。查询2,就是顺着标绿色的块往下。
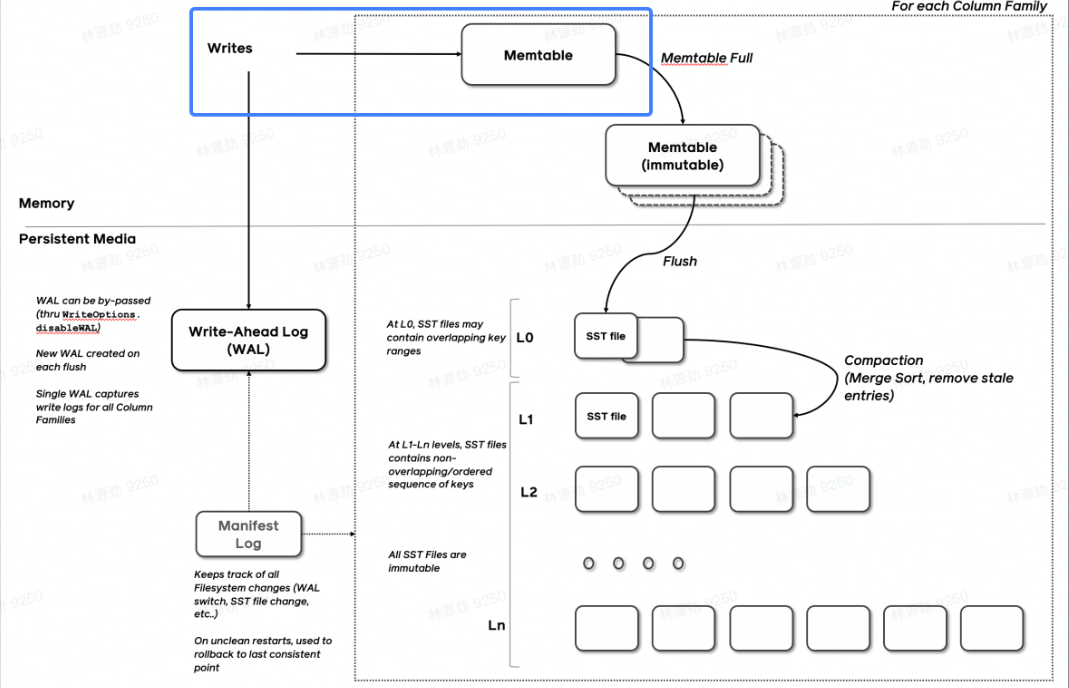
Compact - Level
Compact在 LSMT中是将Key区间有重叠或无效数据较多的SST进行合并,以此来加速读取或者回收空间。Compact策略可以分为两大类,Level和Tier。下图是Level策略
Level策略直接来自于LevelDB,也是 RocksDB的默认策略。每一个层不允许有SST的Key区间重合。
Tier策略允许LSMT每层有多个区间重合的SST
03LSMT模型理论分析
Cloud-Native LSMT Storage Engine - HBase
- RocksDB是单机存储引擎,那么现在都说云原生,HBase 比 RocksDB就更「云」一些,SST直接存储于HDFS上。
- 二者在理论存储模型上都是LSMT。
LSMT模型算法复杂度分析
- T: size ratio,每层LSMT比上一层大多少,LO大小为1,则L1大小为T,L2为T^2,以此类推
- L: level num,LSMT层数
- B:每个最小的IO单位能装载多少条记录
- M:每个 BloomFilter有多少bits
- N:每个 BloomFilter生成时用了多少条KeyS:区间查询的记录数量
Level
-
Write
- 每条记录抵达最底层需要经过L次Compact,每次Compact Ln的一个小SST和Ln+1的一个大SST。
- 设小SST 的大小为1,那么大SST的大小则为T,合并开销是1+T,换言之将1单位的 Ln的SST推到Ln+1要耗费1+T的IO,单次Compact写放大为T。
- 每条记录的写入成本为1/B次最小单位IO。
- o(Write_Level) = L* T * 1/B =T * L/B
-
Point Lookup
- 对于每条Key,最多有L个重叠的区间。
- 每个区间都有BloomFilter,失效率为e^(-M/N),只有当BloomFilter失效时才会访问下一层。
- O(PointLookup_Level) = L* e^(-M/N)
- 注意,这里不乘1/B系数的原因是写入可以批量提交拉低成本,但是读取的时候必须对齐到最小读取单元尺寸。
Tier
-
Write
- 每条记录抵达最底层前同样要经过L次Compact,每次Compact Ln中T个相同尺寸的SST放到Ln+1。
- 设SST大小为1,那么T个SST Compact的合并开销是T,换言之将Ⅰ单位的Ln的SST推到Ln+1要耗费T的IO,单次Compact的写放大为T/T = 1。
- 每条记录的写入成本为1/B次最小单位IO。
- o(Write_Tier)= L* 1 * 1/B = L/B
-
Point Lookup
- 对于每条Key,有L层。
- 每层最多有Ⅰ个重叠区间的SST,对于整个SST来说有T*L个可能命中的SST,乘上BloomFilter的失效率,e个(-M/N),可得结果。
- O(PointLookup_Tier)= L* T* e^(-M/N) = TL e^(-M/N)
- 注意,这里不乘1/B系数的原因是写入可以批量提交拉低成本,但是读取的时候必须对齐到最小读取单元尺寸。
总结,Tier策略降低了写放大,增加了读放大和空间放大,Level策略增加了写放大,降低了读和空间放大。
04LSMT存储引擎调优案例与展望
LSMT存储引擎调优案例- TerarkDB
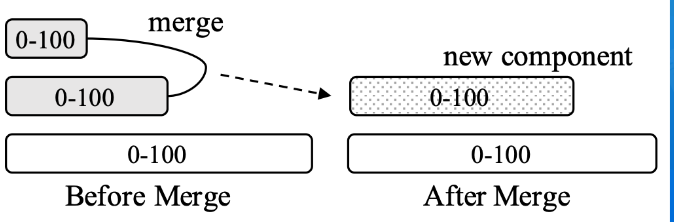
- TerarkDB aka LavaKV是字节跳动内部基于RocksDB深度定制优化的自研LSMT存储引擎,其中完全自研的KV分离功能,上线后取得了巨大的收益。
- KV分离受启发于论文 WiscKey: Separating Keys from Values in SSD-consciousStorage,概括起来就是Value 较长的记录的Value单独存储。
新硬件
- 随着硬件的发展,软件设计也会随着发生改变。近年来,出现了许多新的存储技术,例如SMR HDD,Zoned SSD / OpenChannel SSD,PMem等。如何在这些新硬件上设计/改进存储引擎是一大研究热点。
- e.g.MatrixKV: Reducing Write Stalls and Write Amplification in LSM-tree Based KV Stores withMatrix Container in NVM
- 这篇论文中的设计将L0整个搬进了PMem,降低了写放大。
新模型
- 经典LSMT模型是比较简单的,有时候不能应对所有工况,可以提出新的模型来解决问题。
- e.g. WiscKey: Separating Keys from Values in SSD-conscious Storage通过额外增加一个 Value Store来存储大Value 的记录来降低总体写放大。
- e.g. REMIX:Efficient Range Query for LSM-trees通过额外增加一种 SST的类型来加速范围查询的速度
新参数/新工况
- 已有的模型,在新的或者现有工况下,参数设置的不合理,可以通过更精确的参数设置来提升整体性能。
- e.g. The Log-Structured Merge-Bush & the Wacky Continuum
- 在最后一层使用Level Compaction,之上使用Tier Compaction,通过在除了最后一层以外的SST 加大 BloomFilter的 bits数来规避Tier Compaction带来的点查劣化。
