

在本教程中,我们将解释如何在Python中监控内存消耗。
由于其简单性和稳健性,Python在数据科学界很受欢迎。数据科学家使用Python来处理大量的数据,往往容易出现内存管理问题。如果代码的执行超过了内存的限制,就会出现内存错误并终止执行。
为了克服内存问题,人们可以增加内存分配。但这并不总是可行的。通常情况下,编码者不会释放未使用的内存,并不断分配新的变量,这可能会增加内存消耗。当代码执行时,会消耗更多的内存。Python自动管理内存消耗,但在执行长程序时,它不能返回内存消耗。
因此,需要有工具来监控内存消耗,以优化内存。在本教程中,我们将使用Python的Memory Profiler 模块来监控Python程序的内存消耗。Memory Profiler 内部使用psutil 模块来监控Python程序的逐行内存消耗。
安装模块
Memory Profiler 模块可以通过以下命令安装:
pip install -U memory_profiler
内存分析器的使用
安装Memory Profiler 模块后,我们可以很容易地使用这个模块来跟踪程序的内存消耗。
首先,我们将导入Memory Profiler 模块:
from memory_profiler import profile
@profile 装饰器将在每个要跟踪的函数之前使用。它将以与line-profiler相同的方式逐行追踪内存消耗。
现在我们将在我们的Python脚本中使用@profile 装饰器来跟踪它:
from memory_profiler import profile
@profile
def calculate():
num1 = 50
num2 = 30
sum = num1 + num2
return sum
if __name__=='__main__':
calculate()
上述Python脚本在运行脚本时将绕过-m memory profiler 。它将逐行追踪内存消耗并打印出来。
我们将像下面这样运行该脚本:
python -m memory_profiler <filename>.py
脚本执行后打印出以下逐行的内存消耗报告:
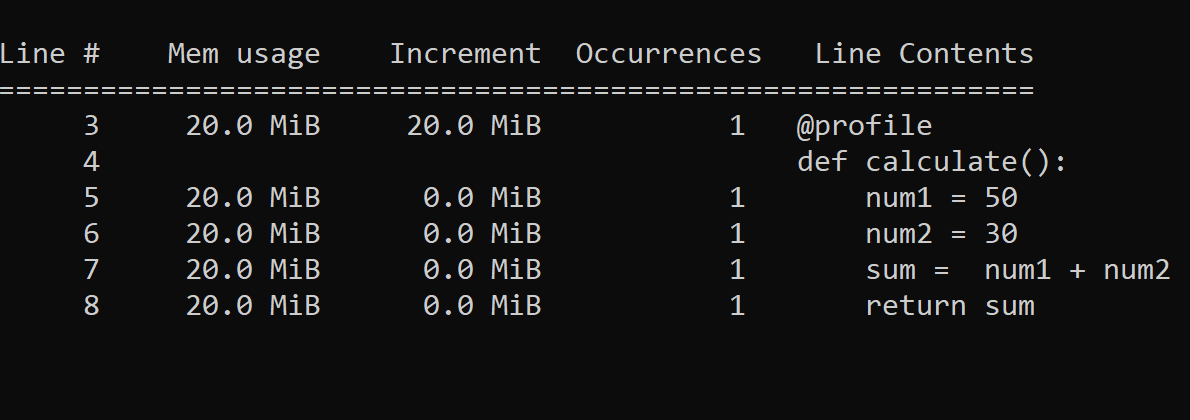
上述报告显示如下:
- 行 #: 打印行号
- 行内容: 打印每个行号的代码
- 内存用量: 打印每一行执行后Python解释器的内存用量。
- 增量: 执行每一行后的内存消耗量之和。
- Occurrences: 打印某一行代码被执行的次数。
