

虽然 Python 的Requests模块可以模拟一个完整的 web 浏览器的动作,但可以说最经常被调用的用例是将 web 内容下载到一个 Python 应用程序中。虽然这种功能的一些最有效的使用涉及到将 XML 或 JSON 数据下载到一个应用程序中,但另一种使用可能涉及到更 "老式 "的人类可读网络内容的文本抓取。在我们关于Python网络开发系列教程的续篇中,我们将讨论如何使用Requests模块,与HTTPS合作,以及网络客户端。
Python Requests 模块
有很多网页浏览器所做的事情,最终用户认为是理所当然的,这些事情必须考虑到任何支持网络的 Python 应用程序中。这三件大事是:
- 超时,否则应用程序将永远阻塞。
- 重定向,否则代码将陷入无尽的循环。
- 最新的操作系统和Python安装,因为它们负责确保支持当前的SSL密码。
本Python教程中的例子将使用Requests模块,有一个下载常规内容的例子(尽管这个内容可以是结构化数据的形式),以及一个通过HTTPS连接下载文件的例子。
虽然Requests模块通常包含在大多数 Python 的安装中,但它也有可能不存在。在这种情况下,可以用命令来安装它。
$ pip3 install requests
在 Windows 中,这将得到类似于下面所示的输出:
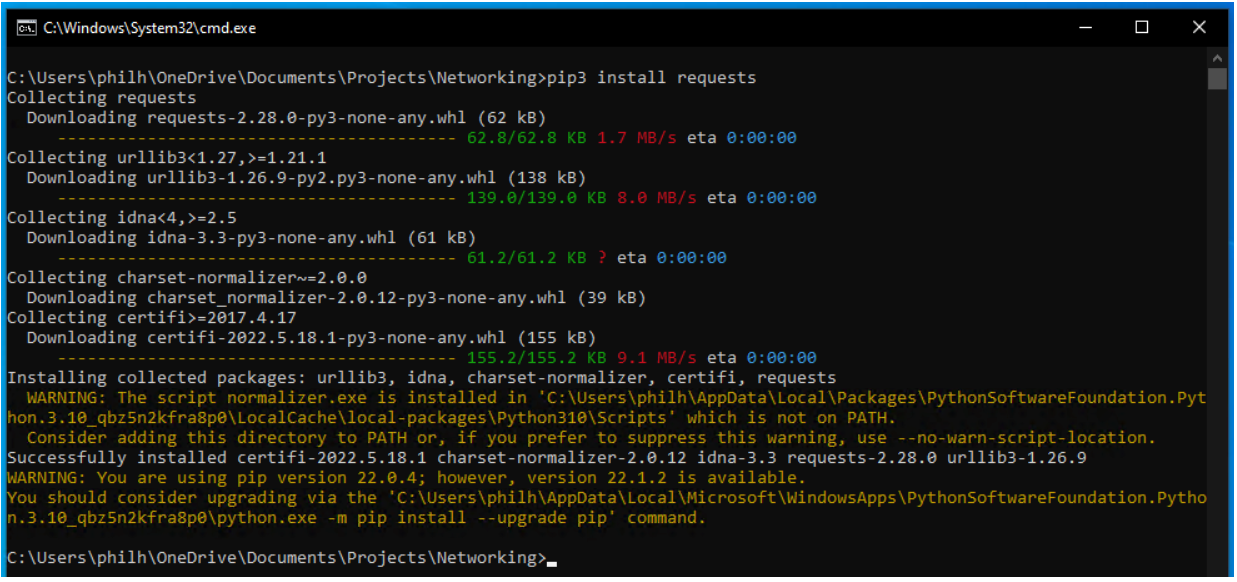
图 1 - 在 Windows 中安装 Requests 模块
使用Python Requests模块下载内容
The Unix Time Now网站显示了当前的Unix时间戳。对于那些(比大多数程序员愿意承认的更常见的)有必要知道当前Unix时间戳是什么的情况,它是一个方便的参考。然而,编程环境并不十分有利于提供它,例如基于.NET的应用开发的情况。这个网站也可以作为一个温和的介绍,从网站的源代码中读取时间作为一个值。
下面的图片显示了上述链接的源代码部分,其中显示了Unix时间戳。请注意,与在传统网络浏览器中浏览网站时显示的动态更新值不同,这将是一个静态值,只有在再次加载页面时才会更新:

图2 - 需要寻找的文本
上面的片段可能看起来像XML,但实际上是HTML 5。虽然HTML 5 "看起来像 "XML,但它不是一回事,而且XML解析器不能解析HTML 5。
下面的Python代码例子将连接到这个网站并解析出Unix时间戳:
# demo-http-1.py
import requests
import sys
def main(argv):
try:
# Specify a half-second timeout and no redirects.
webContent = requests.get ("https://www.unixtimenow.com", timeout=0.5, allow_redirects=False)
# Uncomment below to print the source code of the page.
#print (webContent.text)
# Now do some good old-fashioned text-scraping to get the value.
startIndex = 0
try:
startIndex = webContent.text.index("The Unix Time Now is ")
# Needed because we need the location after the text above.
startIndex = startIndex + len("The Unix Time Now is ")
print ("Found starting Text at [" + str(startIndex) + "]")
except ValueError:
print ("The starting text was not found.")
stringToSearch = webContent.text[startIndex:]
endIndex = 0
try:
endIndex = stringToSearch.index("
") print ("Found ending Text at [" + str(endIndex) + "]") except ValueError: print ("The ending text was not found.") timeStr = stringToSearch[:endIndex] print ("Time String is [" + timeStr + "]") webContent.close() except requests.exceptions.ConnectionError as err: print ("Can't connect due to connection error [" + str(err) + "]") except requests.exceptions.Timeout as err: print ("Can't connect because timeout was exceeded.") except requests.exceptions.RequestException as err: print ("Can't connect due to other Request Error [" + str(err) + "]") if __name__ == "__main__": main(sys.argv[1:])
上面的代码给出了以下输出:

图 3 - 提取 Unix 时间戳
用Python Requests模块下载文件
网站www.httpbin.org,为网络开发提供了大量的测试工具。在这个例子中,Requests模块将被用来从这个网站下载一张图片,地址是httpbin.org/image/jpeg。没有为图片指定文件名;然而,如果指定了文件名,它将出现在内容标题中。
下面的Python代码将显示内容标题并将文件保存在本地:
# demo-http-2.py
import requests
import sys
def main(argv):
try:
# Specify a half-second timeout and no redirects.
webContent = requests.get ("https://httpbin.org/image/jpeg", timeout=0.5, allow_redirects=False)
# This code "knows" that the sample file being downloaded is a JPEG image. If the file
# format is not known, then look at the headers to determine the file type.
print (webContent.headers)
# Even if you use Linux this should be written as a binary file.
fp = open ("image.jpg", "wb")
fp.write(webContent.content)
fp.close()
webContent.close()
except requests.exceptions.ConnectionError as err:
print ("Can't connect due to connection error [" + str(err) + "]")
except requests.exceptions.Timeout as err:
print ("Can't connect because timeout was exceeded.")
except requests.exceptions.RequestException as err:
print ("Can't connect due to other Request Error [" + str(err) + "]")
if __name__ == "__main__":
main(sys.argv[1:])
在你的集成开发环境(IDE)中运行这段代码,会有如下输出。注意目录列表中的变化:
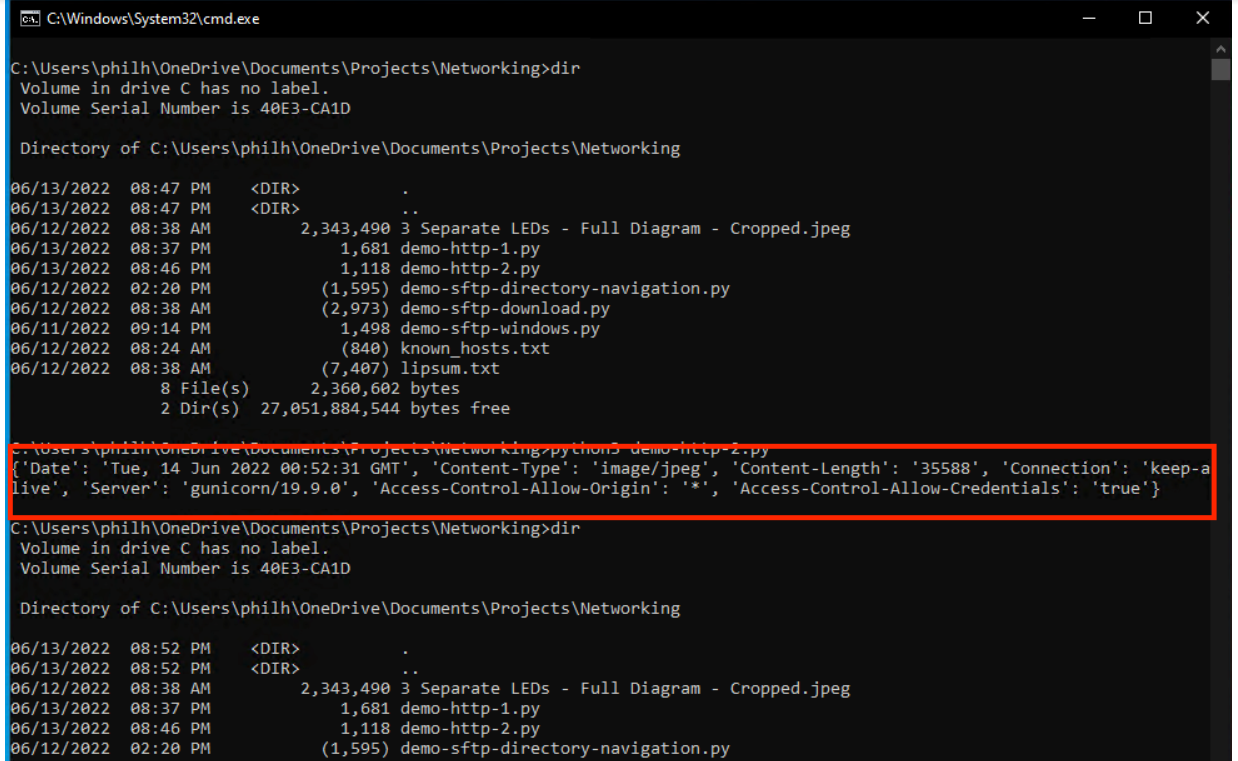
图4--下载并保存的文件数据,HTTP头信息突出显示
与这个例子不同,大多数文件或图像下载通常都有一个附加在内容上的文件名。如果是这种情况,文件名就会出现在上面的标题中,这些标题用红色标出。此外,**"Content-Type "**标头可用于根据所提供的内容推断文件扩展名。
下载并保存的图像与网站上的内容相符:
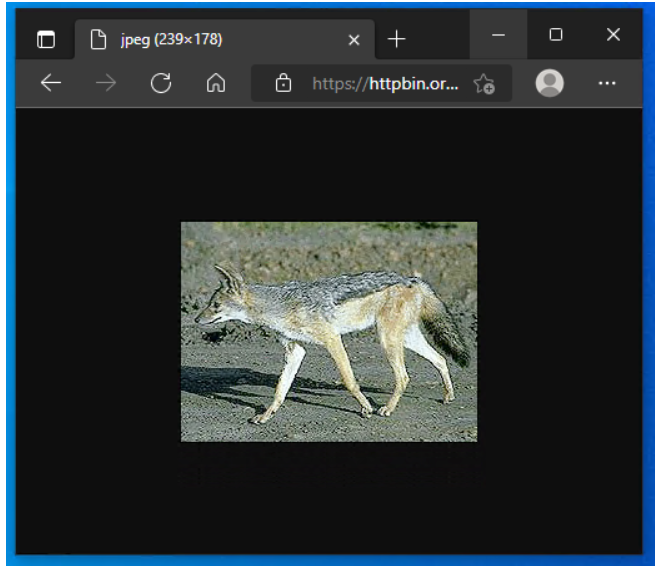
图5 - 原始图像

图6 - 保存的图像
其他HTTPS和Python的考虑
如前所述,这里包括的例子仅仅是对Requests模块所能做的事情的表面描述。Quickstart - Requests 2.28.0 文档中的完整API 参考允许将这段代码扩展到更复杂的 web 客户端应用程序。
最后,HTTPS在很大程度上取决于操作系统和Python安装是否保持最新状态。HTTPS密码,以及内部用来验证网站真实性的证书,都在快速变化。如果本地计算机的操作系统所支持的密码不再被远程网络服务器所支持,那么HTTPS通信将无法实现。
Python Socket模块和网络编程
PythonSocket模块具有一个 "更容易 "的 "创建服务器 "功能,它可以照顾到运行服务器时的大多数典型假设,而且,由于该模块实现了几乎所有相应的 C/C++ Linux 库函数,对于来自该背景的开发者来说,很容易将其转移到 Python。
Python 的服务器功能是如此强大,以至于可以在代码中实现一个完整的 web 服务器,而没有 "传统 "服务器守护程序(如Microsoft Internet Information Server或 Apache**httpd)**所带来的许多配置麻烦和复杂问题。这种功能也可以扩展到强大的网络应用中。
