

MLOps - 使用Power BI跟踪模型指标
在MLOps时代,你可能已经设置了自动再训练(甚至可能是自动再部署),能够监测训练过的模型的性能是非常重要的,这样你就知道它是如何随时间变化的。
另外,只是在你的数据概览上拥有指标,就可以隐藏偏见。例如,如果你想知道一个销售预测模型在某些国家的表现如何,或者一个肿瘤预测模型相对于整个样本在黑人女性身上的表现如何?因此,我们还将展示我们如何对数据进行切片,以确定模型在不同的数据子集上的表现是否更好/更差,并让我们的指标自动更新。
模型跟踪仪表板.pbix文件和相关数据可以在本博文的资料库中找到。
在这篇文章中,我们将创建一个非常简单的仪表盘,使用Power BI报告回归模型的指标,并使用一点DAX。
下面是我们将要创建的几个截图。
![]()
快速免责声明:在写作时,我目前是一名微软员工。
数据集
我们将在这里使用的数据集是著名的波士顿住房数据集。波士顿住房数据集是一个经常用于测试简单回归技术的数据集,用于预测波士顿住房区的房价。
这个数据是1978年的,所以你会注意到,房价远远低于人们对波士顿住宅区的预期。
原始数据集有以下几列。
- CRIM:各镇的人均犯罪率
- ZN:划定为25,000平方英尺以上的住宅用地的比例
- INDUS:每个镇的非零售商业亩数比例
- CHAS: 查尔斯河虚拟变量(=1,如果区块与河流相连;否则为0)。
- NOX: 氮氧化物的浓度(每1000万份)。
- RM: 每个住宅的平均房间数
- 年龄:1940年以前建造的业主自用单元的比例
- DIS:到波士顿五个就业中心的加权距离
- RAD: 辐射状高速公路的可达性指数
- 税率:每10000美元的全额财产税税率
- PTRATIO:各镇的学生-教师比率
- B:1000(Bk-0.63)^2,其中Bk是各镇黑人的比例
- LSTAT:人口中地位较低的百分比
在我们的数据集中,目标列被赋予 "PRICE",即住房区的房屋中位价,单位为1000美元。
然后,我们在这些数据上模拟训练两个模型--"随机森林回归者 "和 "线性回归者",就像我们在某一周(8月10日)有较少的训练样本,然后在之后的一周(8月17日)有更多的训练样本--就像你在生产系统中随着时间的推移积累训练数据那样。
训练完这些模型后,我们在数据集上附加了更多的列。
- PRICE_PREDICTION:模型对地区价格的预测,单位是1000美元。
- is_train。如果数据被用作训练数据(1)或测试数据(0)的布尔值
- model_name: 训练过的模型的名称
- model_version。被训练的模型的版本号
- date: 训练日期
根据数据集的大小,我们可能会将训练历史保留3-12个月,我们会将这些信息存储在我们的数据仓库或数据湖中,并将我们的仪表盘连接到它上面。当你将一个仪表盘发布到Power BI并与一个数据集相连时--这可以被设置为一个刷新计时器,以获得最新的数据,例如,在你的重新训练管道之后的每一周。
如果你想用一个新的报告来连接我们的数据集,点击 "获取数据",然后选择 "文本/CSV "并按 "连接"。

然后导航到你保存model_metric_tracking.csv文件的地方。在出现的弹出窗口中,点击 "加载 "按钮,你应该有如下的数据加载:

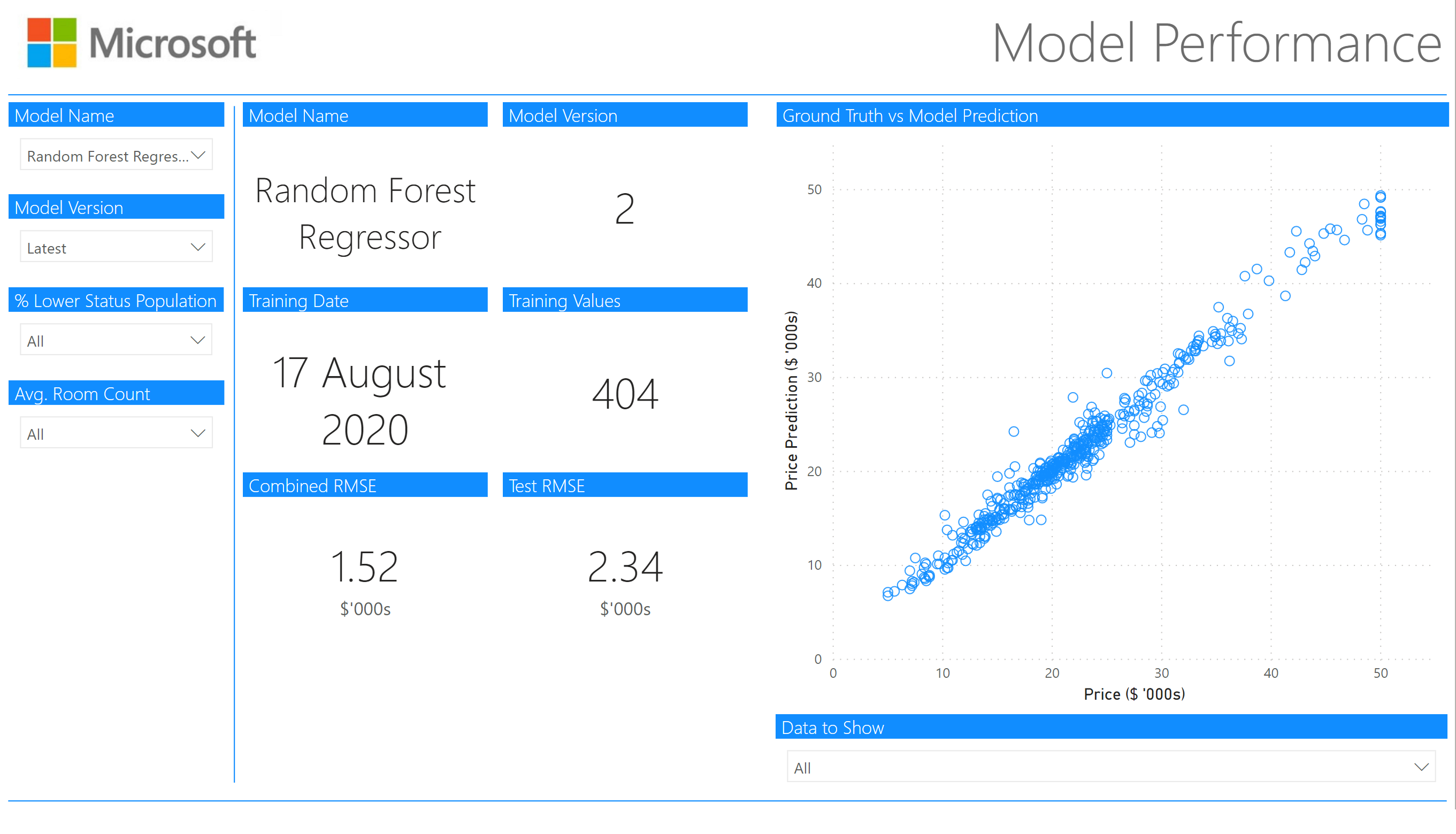
模型指标跟踪页面
现在我们已经加载了数据,我们将开始创建跟踪页面。这是用于跟踪模型指标的时间,这个折线图会随着时间的推移而建立起来,我们也可以看到当前部署的是哪个模型。
![]()
这是一个相当简单的仪表盘,但我们需要一点DAX来实现它。
首先,我们要创建一个新的列,所以在我们的数据选项卡中,点击 "新列",并输入以下DAX来计算每行的平方误差。
squared_error = POWER(model_metric_tracking[PRICE] - model_metric_tracking[PRICE_PREDICTION], 2)
然后,我们将创建2个均方根误差(RMSE)的度量,我们将有一个给出测试和训练数据的综合RMSE (rmse),一个只给出测试数据的RMSE (test_rmse),我们将把它用于我们的线形图,所以点击 "新度量 "按钮并输入以下DAX语句。
rmse = SQRT(AVERAGE(model_metric_tracking[squared_error]))
和。
test_rmse = SQRT(
CALCULATE(
AVERAGE(model_metric_tracking[squared_error]),
FILTER(
model_metric_tracking,
model_metric_tracking[is_train] = 0
)
)
)
现在我们可以在报告页面的折线图中使用这个test_rmse 值。所以点击可视化窗格中的折线图选择:

然后选择适当的字段(date 为 "轴",model_name 为 "图例",test_rmse 为 "值"):
然后,你可以适当地重命名这些字段,并在格式上做文章,直到你得到你喜欢的、适合你公司品牌的东西。
我已经重新命名了X和Y轴的标签,并更新了上面例子中标题的格式。
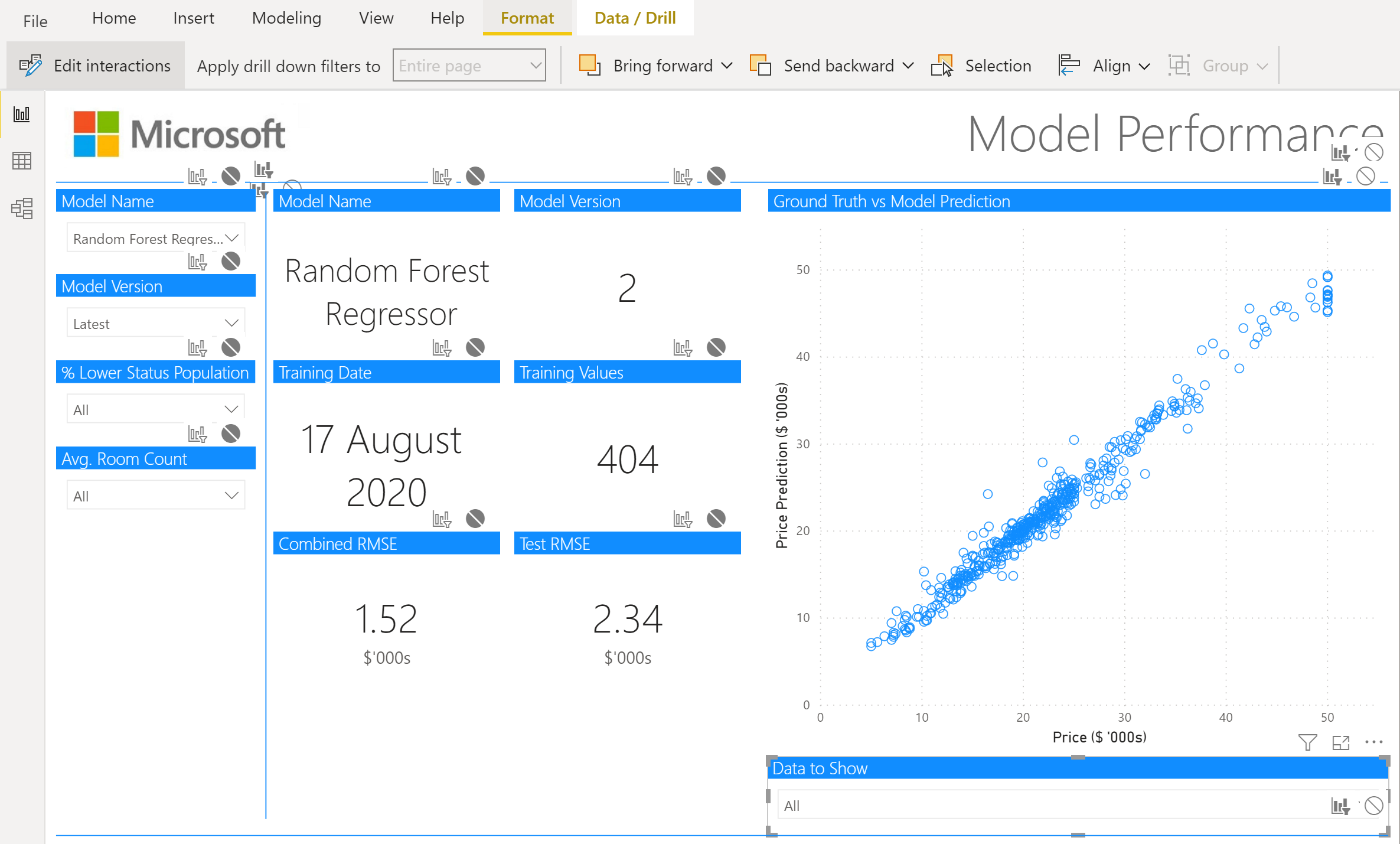
在这个折线图下面有3个文本框,显示当前部署的模型、模型版本号和模型培训日期--在一个生产系统中,这些值可能会从数据库或配置文件中获取。
模型性能
模型性能页面用于深入了解每个单独模型的性能,并对数据进行切片,以确定模型在不同的数据子集上是否有更好/更差的表现。
我们希望这个页面显示单个模型的单一版本,所以我们将通知用户,如果他们没有选择模型和版本号,他们需要选择一个模型。因此,我们使用DAX再创建两个 "新措施"。
selected_model = IF(
DISTINCTCOUNT(model_metric_tracking[model_name]) > 1,
"Select A Model",
MIN(model_metric_tracking[model_name])
)
selected_version = IF(
DISTINCTCOUNT(model_metric_tracking[model_version]) > 1,
"Select A Version",
MIN(model_metric_tracking[model_version])
)
现在我们已经有了这些,我们可以插入我们的卡片和切片机。
分片器
我们将从切片器开始。
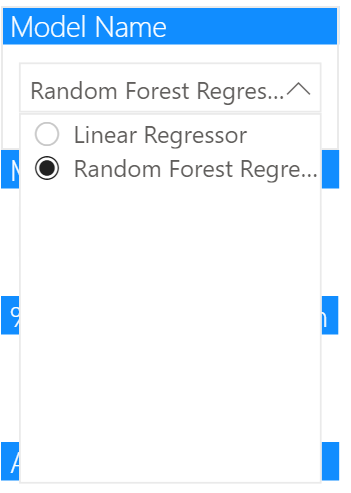
模型名称
左边的第一个切片器是我们的模型名称切片器,所以我们插入一个切片器并提供model_name 作为字段。在 "选择控制 "下,我们要确保 "单次选择 "是打开的。我们也可以使这个切片器成为一个 "下拉 "而不是 "列表"。然后我们可以选择一个单一的模型,如图所示。
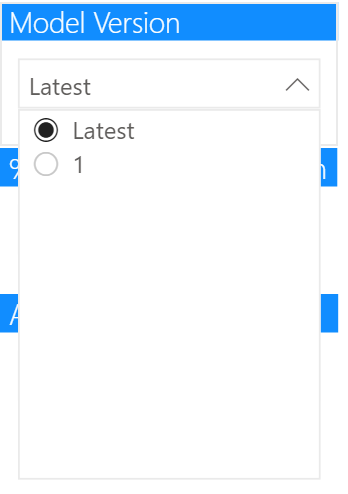
模型版本
左边的第二个切片器是我们的模型版本切片器,我们将让用户选择 "最新 "的模型。这样做的原因是,我们可以确保这个页面永远显示最新的模型,即使是在重新训练之后。
这将作为一个 "新列 "给出,如下所示,如果模型版本与该模型名称的最大模型版本相同,我们将返回 "最新",否则我们将返回数字作为一个字符串。
latest_version_number = IF(
CALCULATE(
MAX(
model_metric_tracking[model_version]
),
ALLEXCEPT(
model_metric_tracking,
model_metric_tracking[model_name]
)
) = model_metric_tracking[model_version],
"Latest",
CONVERT(model_metric_tracking[model_version], STRING)
)
由于现在是一个字符串,在排序时你会遇到奇怪的问题,比如有 "1"、"10"、"2"...而不是 "1"、"2"... "10",我们想通过我们的model_version 列来排序。我们可以通过点击该字段,然后在 "列工具 "中选择 "按列排序 "按钮并点击 "model_version "来实现。
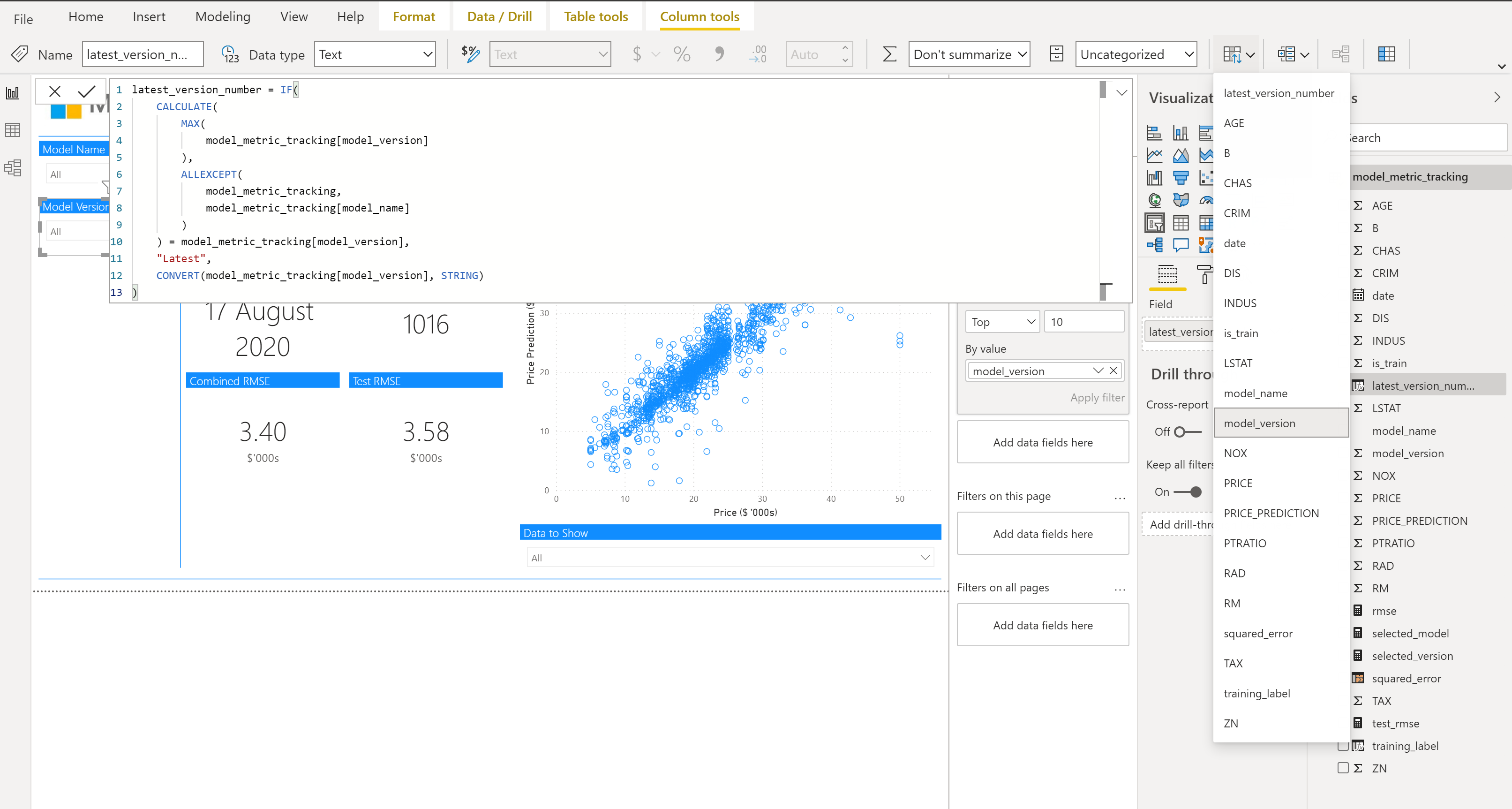
然后,我们需要确保选择 "降序排序",以确保最新的显示在前面,最新的训练模型在后面。
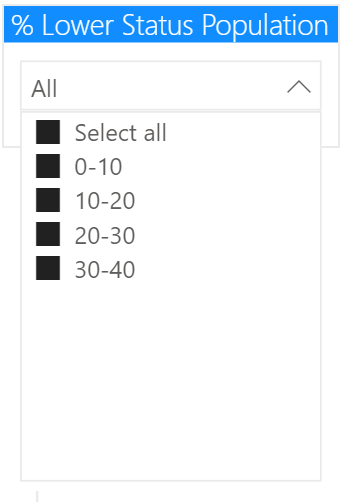
低地位人口百分比
预测地区平均房价的两个最重要的特征是 "LSTAT "和 "RM",所以我们为这些特征创建了切片机,以查看我们的模型在这里的不同数据子集上的表现。
"LSTAT "是 "地位较低的人口百分比",我们想把它作为我们的切片机。这在DAX中已经完成,使用SWITCH 语句来创建一个 "新列",没有高于40的百分比值。
LSTAT_BINNED = SWITCH(
TRUE(),
model_metric_tracking[LSTAT] < 10,
"0-10",
model_metric_tracking[LSTAT] < 20,
"10-20",
model_metric_tracking[LSTAT] < 30,
"20-30",
"30-40"
)
我们用这个计算出来的列来做切片器。对于这里的下拉菜单,我们提供了 "全部选择 "的选项:
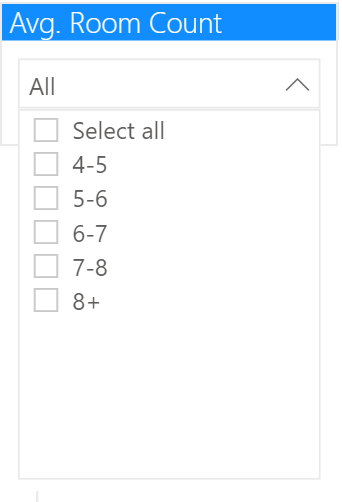
房间数平均值
如上所述,预测地区平均房价的另一个重要特征是 "RM",即房间的平均数量。我们再次使用DAX将这一数据归入 "新列"。
RM_BINNED = SWITCH(
TRUE(),
model_metric_tracking[RM] < 5,
"4-5",
model_metric_tracking[RM] < 6,
"5-6",
model_metric_tracking[RM] < 7,
"6-7",
model_metric_tracking[RM] < 8,
"7-8",
"8+"
)
同样,我们使用这个计算出来的列来进行切片。
卡片
在切片器旁边,我们有我们的卡片,这些卡片将根据切片器中的选择而更新。
对于每张卡片,我们已经打开了标题,更新了标题的格式,并关闭了类别(除了最后两张,我们用它来表示RMSE的$'000s )。
这是为所有显示的6张卡片复制的。
- 模型名称 (selected_model)
- 模型版本 (selected_version)
- 训练日期(日期--选择 "最新 "进行汇总)
- 训练值 (is_train - 选择 "Sum "进行聚合)
- 综合RMSE (rmse)
- 测试RMSE (test_rmse)
散点图
我们创建一个散点图来显示模型在每个数据点上的表现与地面实况的对比,所以首先要选择一个散点图。
然后选择适当的字段(X轴为"PRICE" ,Y轴为"PRICE_PREDICTION" ):
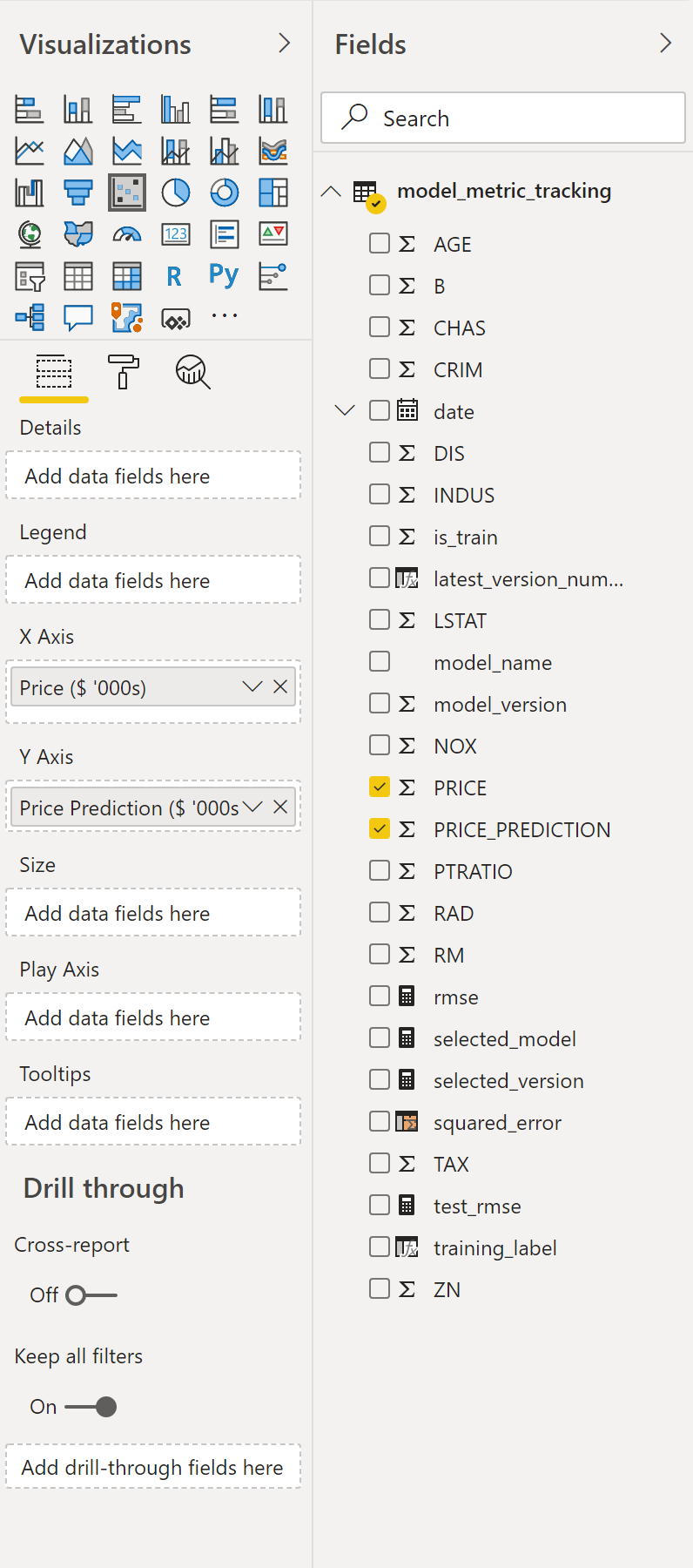
我们需要对这个散点图做一些改变。
- 点击Y轴的下拉菜单,然后点击不要汇总
- 如果你有大量的数据需要显示,增加数据点的限制
- 我选择不填充点,因为默认的透明度水平很低,所以很难确定点的密度。
选择要显示的数据
在散点图下面有一个切片器,你可以从中选择你想在散点图中看到的数据。
- 选择全部
- 测试
- 训练
这可以通过在DAX中创建一个新的计算列来完成。
training_label = IF(model_metric_tracking[is_train] = 0, "Training", "Test")
并从这个新的计算列中创建一个切片器。然而,由于我们只想让这个切片器选择散点图上的数据,而不是我们的卡片上的数据,我们需要关闭这些交互。我们可以通过选择我们的切片器,然后在 "格式 "功能区中,选择 "编辑交互",关闭所有与其他可视化的交互,而不是散点图。
发布报告
要把报告发布到powerbi.com工作区,点击 "文件"、"发布 "和 "发布到Power BI"。
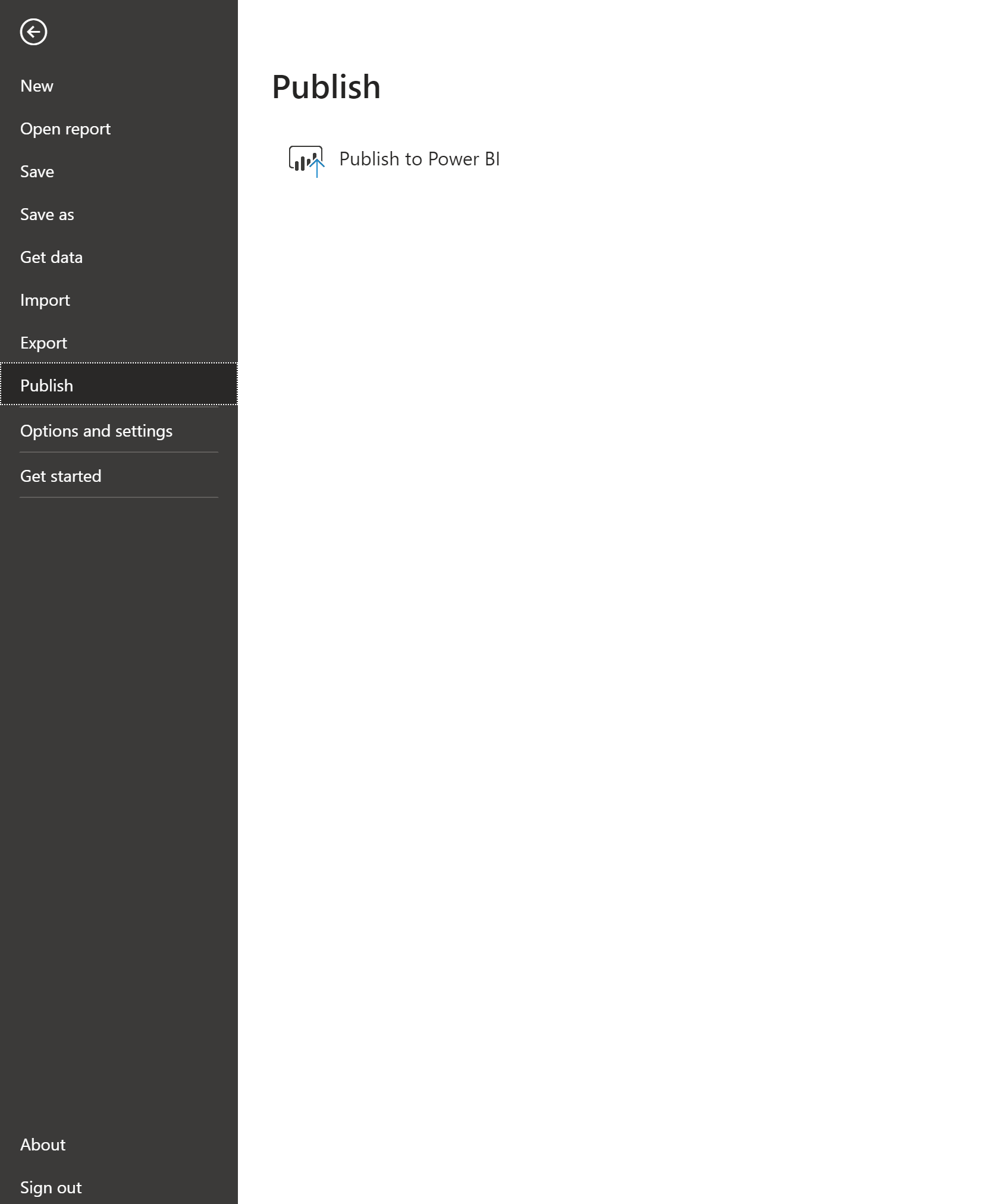
然后,如上所述,我们可以将我们的数据集设置为定时刷新,在我们的模型重新训练管道之后刷新。
这样我们就有了简单的模型度量报告。你可以为分类模型做一个尝试,并根据你自己的需要进行定制。
