用Databricks进行单元测试
第2部分--将PySpark单元测试集成到Azure Pipelines CI管道中
这是探讨Databricks的PySpark单元测试的2篇博文的第2部分。在这一部分中,我们将探讨如何使用Azure Pipelines将我们在第一部分中定义的单元测试整合到持续集成(CI)管道中。
关于第一部分,我们探讨单元测试本身,请看这里。
关于建立这类管道的更多信息,请看我以前的博客文章《在Azure管道中建立CI管道》。
这次你需要把git仓库分叉到你自己的Azure DevOps项目。所以在这里导航到git仓库,然后点击省略号,选择 "分叉"。
快速免责声明:在写作时,我目前是一名微软员工。
定义一个管道库
首先,我们将定义我们的管道在运行时将使用的一些变量,我们将把这些变量存储在Azure管道中的变量组中,它们将在管道中使用。在Azure DevOps中选择库。
然后点击按钮,添加一个变量组。

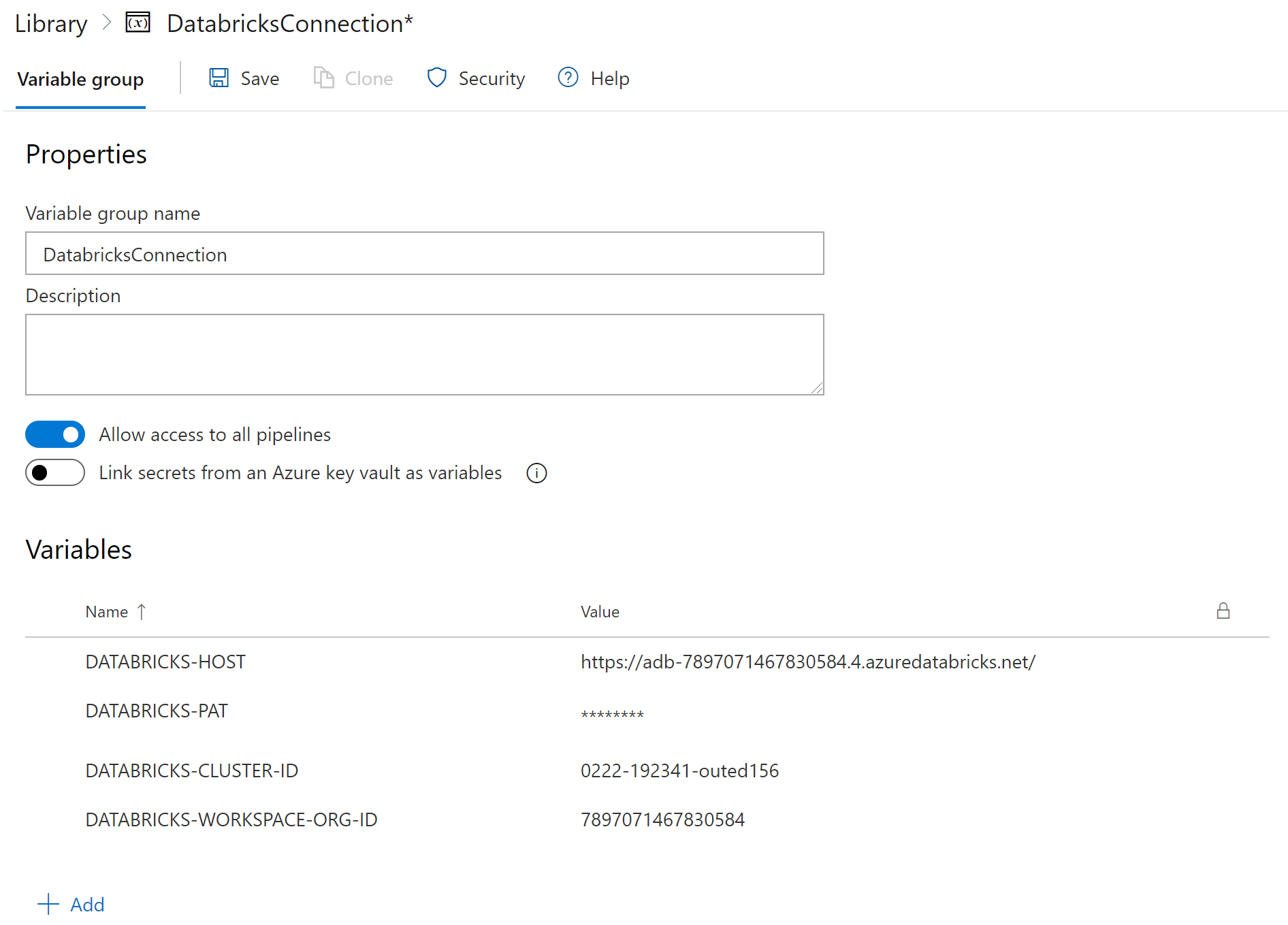
将你的变量组命名为 "DatabricksConnection "并添加以下变量。
DATABRICKS-HOST- 你的Databricks主机(开始是https://)
DATABRICKS-PAT- 你的Databricks个人访问令牌
DATABRICKS-CLUSTER-ID- 你的Databricks集群的集群ID
DATABRICKS-WORKSPACE-ORG-ID- 您的Databricks集群的组织ID,在您的Databricks工作空间URL中为?o=。
并单击 "保存"。
Azure管线定义
在我们的资源库中,我们定义了一个azure-pipelines.yml yaml配置文件来运行我们的持续集成管道。我将首先展示它的全部内容,然后再逐一说明。
trigger:
branches:
include:
- 'main'
pr:
branches:
include:
- '*'
variables:
- group: 'DatabricksConnection'
name: 'Project CI Pipeline'
pool:
vmImage: 'ubuntu-20.04'
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.7'
architecture: 'x64'
- script: |
python -m pip install --upgrade pip
pip install -r requirements.txt
displayName: 'Install requirements'
- script: |
echo "y
$(DATABRICKS-HOST)
$(DATABRICKS-PAT)
$(DATABRICKS-CLUSTER-ID)
$(DATABRICKS-WORKSPACE-ORG-ID)
15001" | databricks-connect configure
displayName: "Configure DBConnect"
- script: |
pytest -v databricks_pkg/test --doctest-modules --junitxml=unit-testresults.xml --cov=deployment/pkg/ --cov-append --cov-report=xml:coverage.xml --cov-report=html:htmlcov
displayName: 'Run databricks_pkg package unit tests'
- task: PublishTestResults@2
inputs:
testResultsFormat: 'JUnit'
testResultsFiles: '**/*-testresults.xml'
testRunTitle: '$(Agent.OS) - $(Build.BuildNumber)[$(Agent.JobName)] - Python $(python.version) - Unit Test results'
condition: succeededOrFailed()
displayName: 'Publish unit test and linting results'
- task: PublishCodeCoverageResults@1
inputs:
codeCoverageTool: Cobertura
summaryFileLocation: 'coverage.xml'
reportDirectory: 'htmlcov'
displayName: 'Publish Coverage Results'
管线触发
该管道被设置为在任何代码合并到 "主 "分支以及任何拉动请求到任何分支时触发。
trigger:
branches:
include:
- 'main'
pr:
branches:
include:
- '*'
变量组
这将获得我们在Azure管道的库部分中设置的变量组中定义的变量。
variables:
- group: 'DatabricksConnection'
名称
这将命名我们的CI管线。
name: 'Project CI Pipeline'
池子
我们在Ubuntu 20.04 VM上运行我们的CI管道。
pool:
vmImage: 'ubuntu-20.04'
步骤
这将设置运行的python版本为python 3.7
- task: UsePythonVersion@0
inputs:
versionSpec: '3.7'
architecture: 'x64'
安装需求
然后我们在虚拟机上安装我们的项目需求。
- script: |
python -m pip install --upgrade pip
pip install -r requirements.txt
displayName: 'Install requirements'
配置Databricks Connect
这将使用我们在变量组中定义的变量来配置Databricks Connect(并将端口设置为默认的15001--与你在第一部分中在本地机器上做的一样。
- script: |
echo "y
$(DATABRICKS-HOST)
$(DATABRICKS-PAT)
$(DATABRICKS-CLUSTER-ID)
$(DATABRICKS-WORKSPACE-ORG-ID)
15001" | databricks-connect configure
displayName: "Configure DBConnect"
运行单元测试,发布测试结果和代码覆盖率结果
这将运行单元测试,创建一个测试结果文件和XML格式的代码覆盖率文件。
- script: |
pytest -v databricks_pkg/ --doctest-modules --junitxml=unit-testresults.xml --cov=databricks_pkg/ --cov-append --cov-report=xml:coverage.xml --cov-report=html:htmlcov
displayName: 'Run databricks_pkg package unit tests'
然后我们可以发布测试结果和代码覆盖率结果。
- task: PublishTestResults@2
inputs:
testResultsFormat: 'JUnit'
testResultsFiles: '**/*-testresults.xml'
testRunTitle: '$(Agent.OS) - $(Build.BuildNumber)[$(Agent.JobName)] - Python $(python.version) - Unit Test results'
condition: succeededOrFailed()
displayName: 'Publish unit test and linting results'
- task: PublishCodeCoverageResults@1
inputs:
codeCoverageTool: Cobertura
summaryFileLocation: 'coverage.xml'
reportDirectory: 'htmlcov'
displayName: 'Publish Coverage Results'
运行Azure管线
在Azure Pipelines中选择管线
然后选择Azure Repos Git。
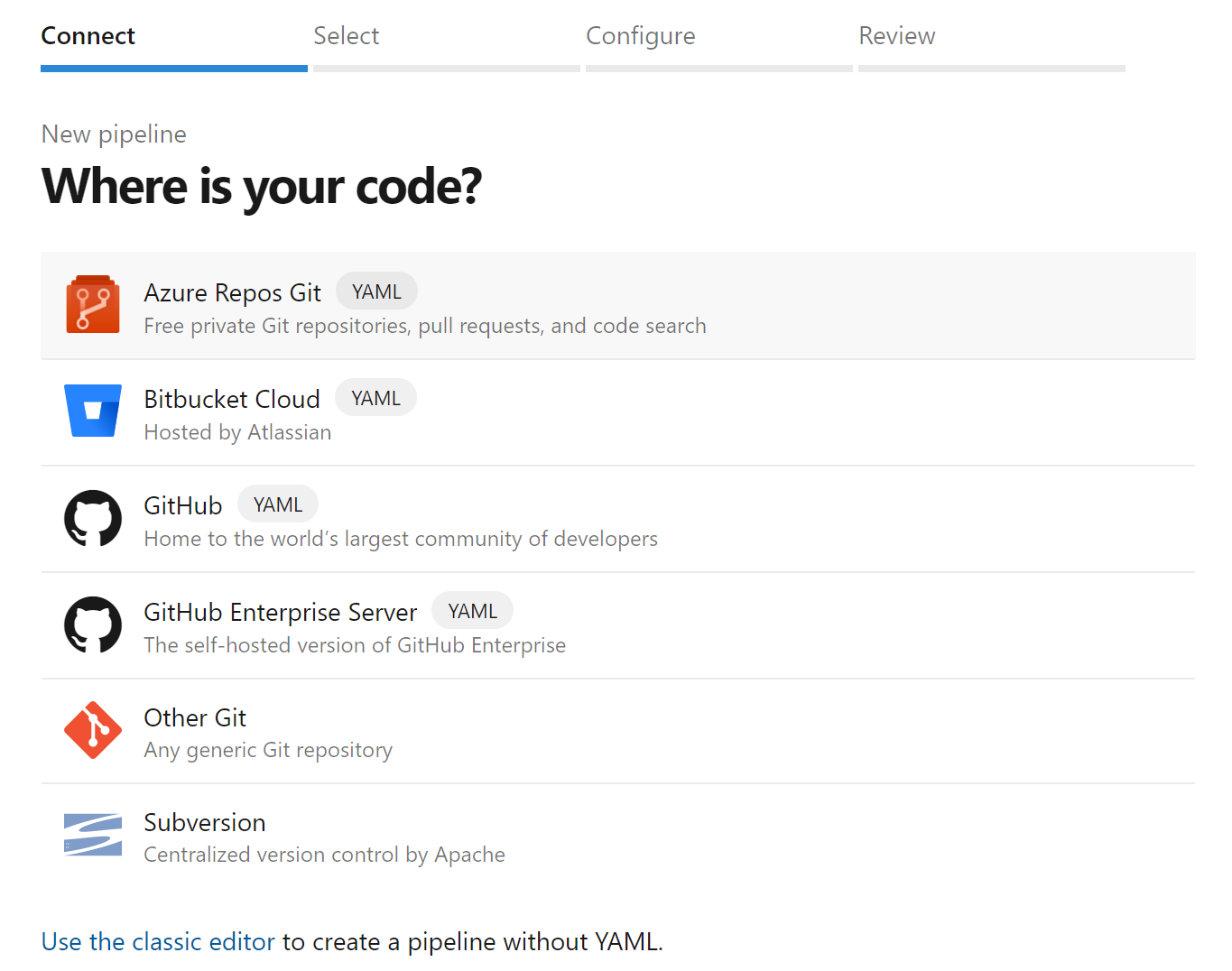
选择你的存储库,然后点击运行按钮。

你会来到一个页面,显示你的作业正在运行。

你可以点击这个作业,查看更多信息。
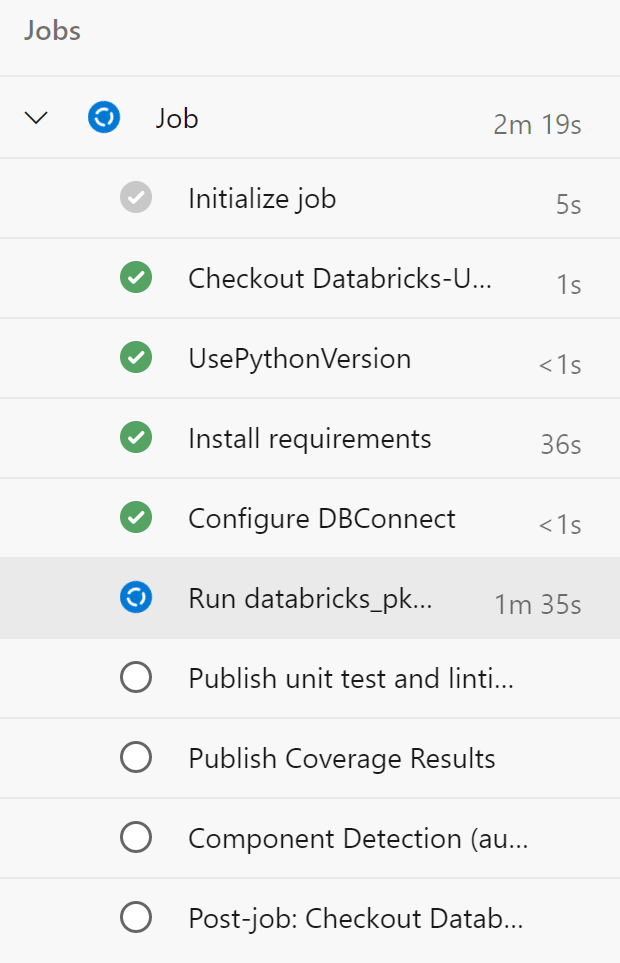
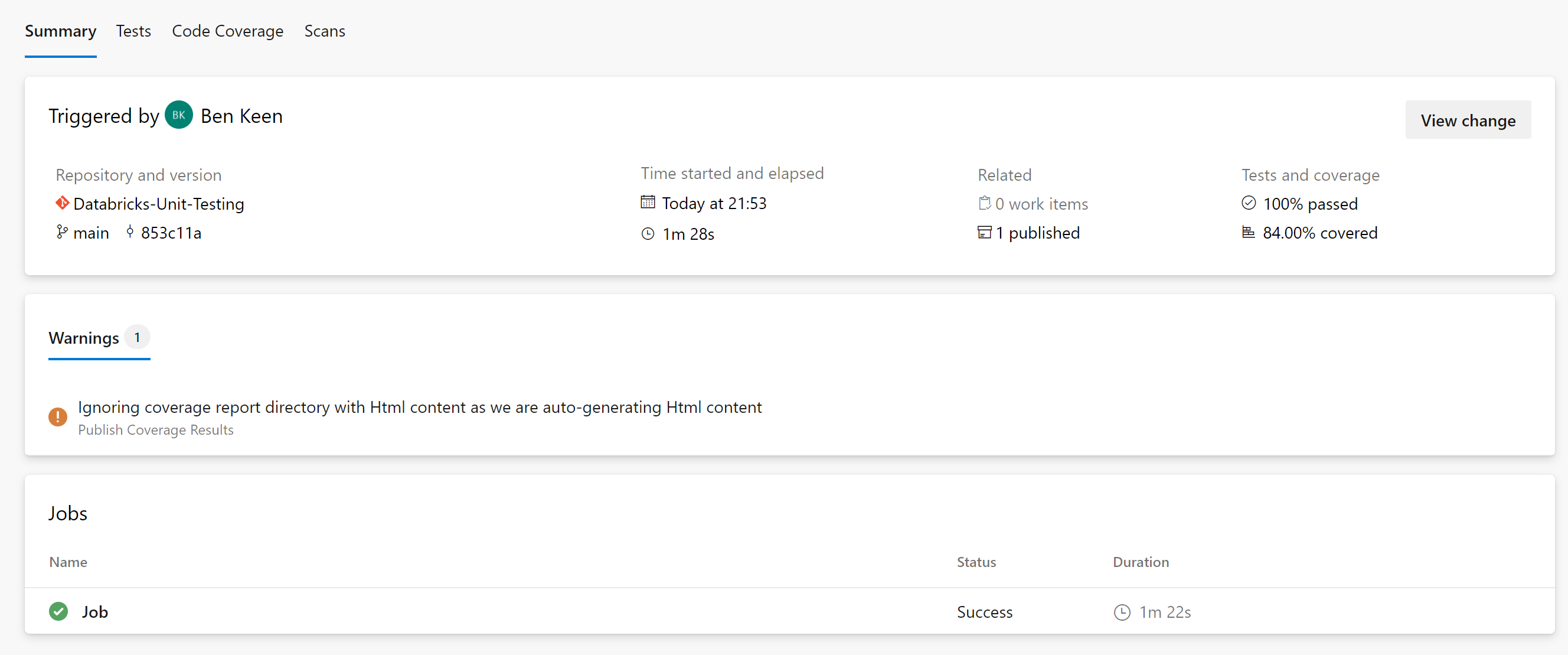
当管道完成后,你会看到与此类似的东西。
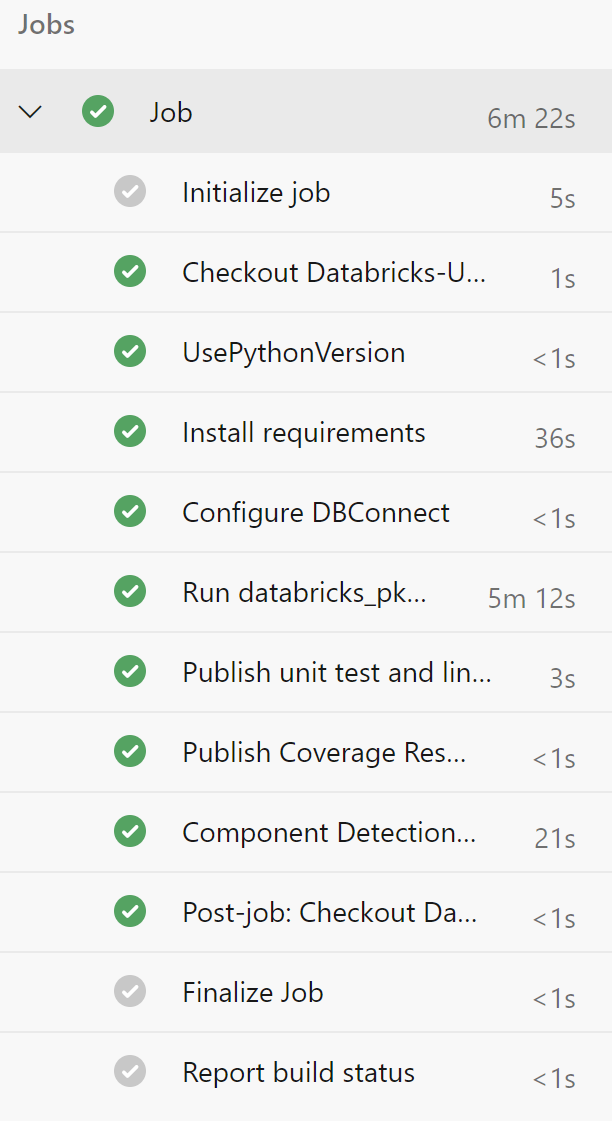
现在,你的管道将在任何合并到主分支或任何拉动请求上运行。
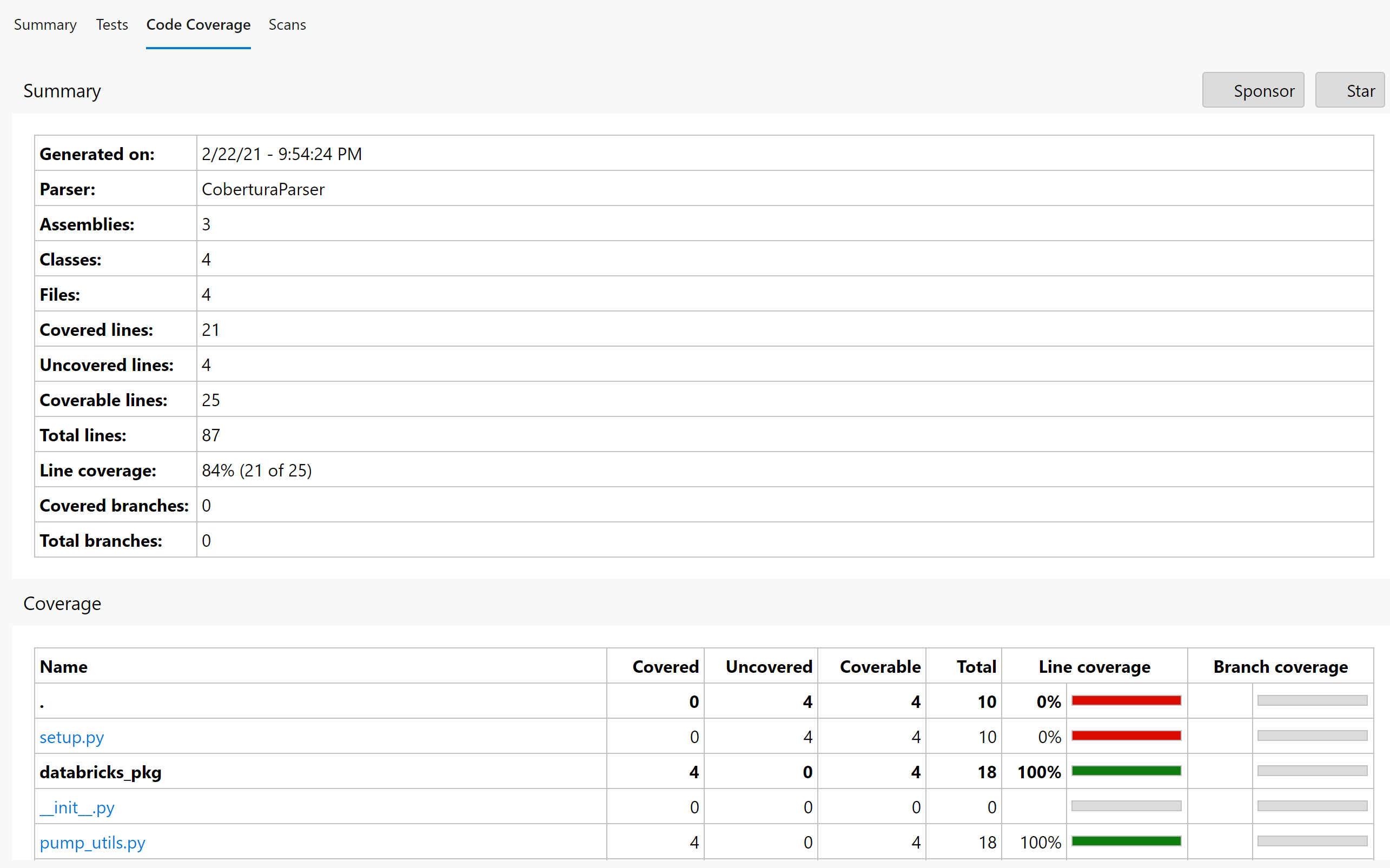
如果你回到你的管道运行状态页面,你会看到你有测试报告和测试覆盖率的标签。
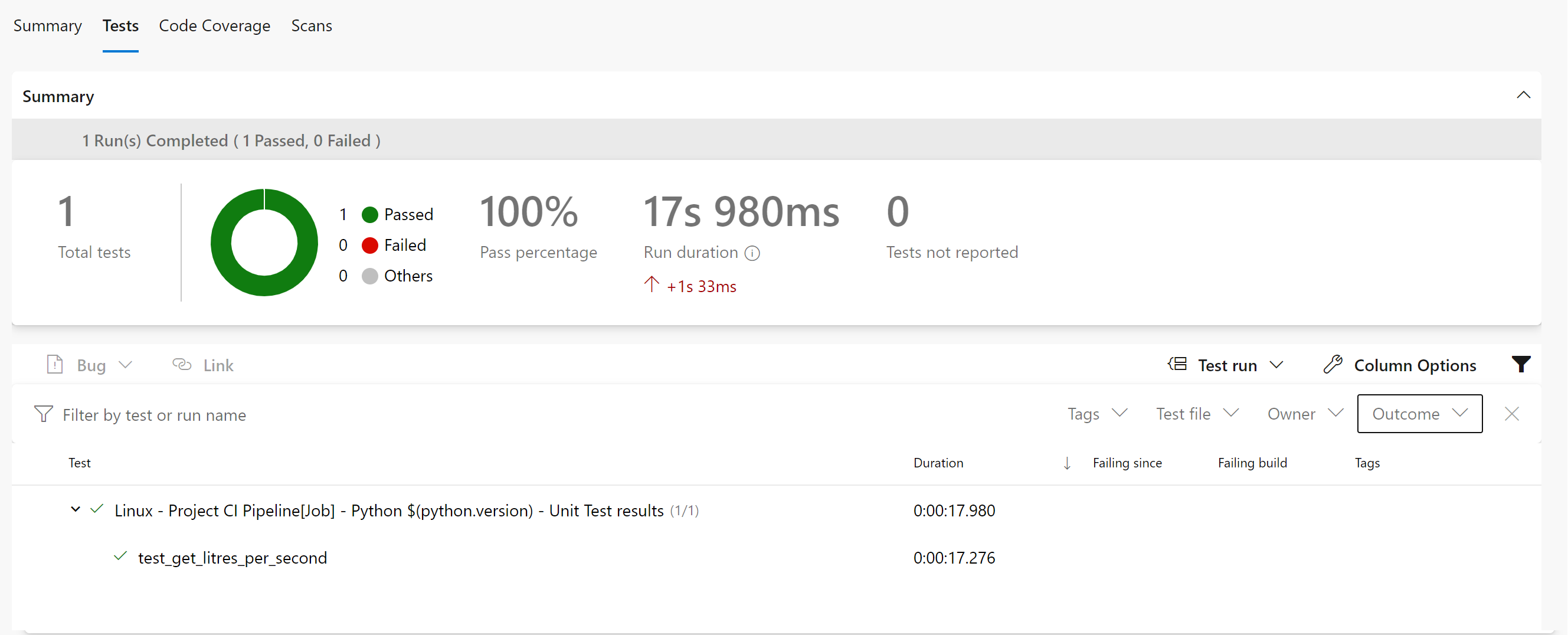
你的测试报告应该看起来像这样。
而你的代码覆盖率页面应该是这样的。