

Go中的软件架构。缓存旁,云设计模式的可扩展性
欢迎来到涵盖质量属性/非功能要求的系列的另一个帖子,这次我说的是一种提高可扩展性的云设计模式,叫做。Cache-Aside。
什么是缓存?
缓存是指在Go的微服务中存储并使用预先计算的值来进行昂贵的计算。在这篇文章中,我假设你在投入时间实现缓存之前已经熟悉了这些方法。
Cache-Aside模式是如何工作的?
Cache-Aside模式是在只读API和要返回给客户的数据之间进行的。这个想法包括当数据在缓存中可用时立即返回,而在那些数值不存在的情况下,例如在第一次请求中,它们被设置在缓存中,首先从持久性数据存储中检索信息,在缓存中设置数值,最后用缓存中的数值返回。
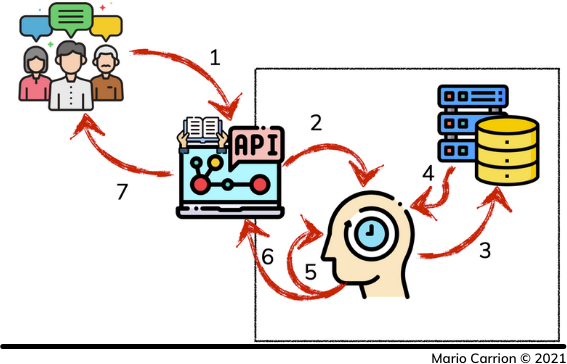
在第一次请求发生时,会发生Cache-Miss,并发生以下步骤。
- 客户请求只读API。
- API从缓存中请求数据。
- 缓存数据没有找到,因此从持久性数据存储中获取。
- 数据存储返回请求的值。
- 值在缓存层中被设置。
- 缓存的值被返回到我们的只读API,最后
- 信息被提供给我们的客户。
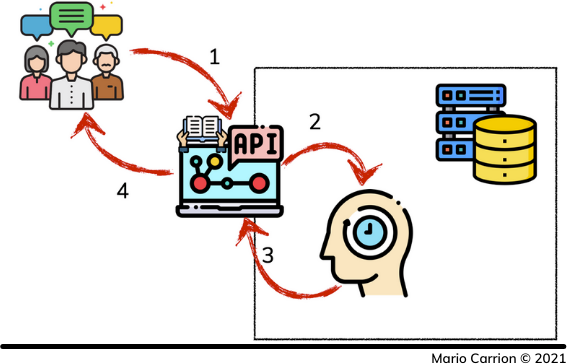
因为数据已经在缓存中了,所以后续请求检索相同的值时,直接访问缓存,步骤就简化了。
- 客户请求只读API。
- API从缓存中请求数据,缓存数据被找到。
- 缓存的值被返回到我们的只读API,最后
- 信息被提供给我们的客户。
如何在Go中实现Cache-Aside模式?
我喜欢用Decorator模式在Go中实现Cache-Aside模式,这样数据存储类型中定义的API保持不变,只需要建立必要的Cache-Aside逻辑。
使用To-Do微服务的例子,我正在实现这个Cache-Aside模式以加快搜索结果,有一个新的包叫做 memcached定义了一个新的类型,叫做Task ,它实现了由其对应的 elasticsearch.Task类型所定义的方法。
memcached.Task 类型定义了memcached客户端,以及使用接口类型与原始数据存储的链接。
// Task ...
type Task struct {
client *memcache.Client
orig Datastore
}
type Datastore interface {
Delete(ctx context.Context, id string) error
Index(ctx context.Context, task internal.Task) error
Search(ctx context.Context, args internal.SearchArgs) (internal.SearchResults, error)
}
因为我只对缓存搜索结果感兴趣,其他两个方法委托给原始数据源的调用。
func (t *Task) Index(ctx context.Context, task internal.Task) error {
return t.orig.Index(ctx, task)
}
func (t *Task) Delete(ctx context.Context, id string) error {
return t.orig.Delete(ctx, id)
}
这个模式的真正实现发生在 Search方法中,我在上面提到的步骤被定义。
func (t *Task) Search(ctx context.Context, args internal.SearchArgs) (internal.SearchResults, error) {
key := newKey(args)
item, err := t.client.Get(key)
if err != nil {
if err == memcache.ErrCacheMiss { // 3. Cache data is not found, therefore it’s fetched from persistent data store,
res, err := t.orig.Search(ctx, args) // 4. Data store returns requested values,
if err != nil {
return internal.SearchResults{}, internal.WrapErrorf(err, internal.ErrorCodeUnknown, "orig.Search")
}
var b bytes.Buffer
if err := gob.NewEncoder(&b).Encode(&res); err == nil { // 5. Values are set in the caching layer,
t.client.Set(&memcache.Item{
Key: key,
Value: b.Bytes(),
Expiration: int32(time.Now().Add(25 * time.Second).Unix()),
})
}
return res, err // 6. Cached values are returned back to our Read-Only API, and finally
}
return internal.SearchResults{}, internal.WrapErrorf(err, internal.ErrorCodeUnknown, "client.Get")
}
// 3. Cache data is found
var res internal.SearchResults
if err := gob.NewDecoder(bytes.NewReader(item.Value)).Decode(&res); err != nil {
return internal.SearchResults{}, internal.WrapErrorf(err, internal.ErrorCodeUnknown, "gob.NewDecoder")
}
return res, nil
}
结论
Cache-Aside 模式的目的是通过减少返回值给客户的时间来提高我们服务的可扩展性,确保你定义了自动驱逐时间,以避免出现陈旧的数据,在未来的文章中,我将介绍其他的缓存模式,这些模式采取了不同的方法,但最终目标是相同的。
