携手创作,共同成长!这是我参与「掘金日新计划 · 8 月更文挑战」的第16天,点击查看活动详情
我们 loss 函数曲面是崎岖不平,有相对平缓的区域,也有陡峭的区域,那么如果在整个梯度下降过程中如果都采用一个步长(学习率)都会有问题的。

如果学习率设置过大那么就很容出现下图左图现象,当接近极值点,因为学习率过大会始终在极值点附近震荡无法抵达到极值点。
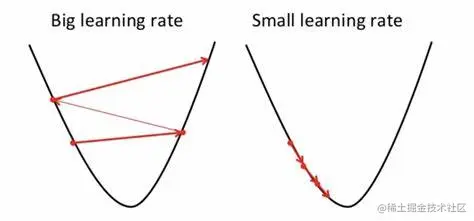
那么如果设置过小,就会导致训练起来时间比较长。甚至难以接受,所以我们就需要根据不同 loss 曲面来调整学习率

AdaGrad
翻译过来是自适应梯度,听起来很酷名字,那么 AdaGrad 出现又是来解决什么样问题呢? 有的时候我们loss 不再下降,但是梯度 norm 并不是 0,这是有可能梯度在距离极值点有段距离的山谷处震荡。
θt+1=θt−∑i=0t(gi)2ηgt
AdaGrad 适合处理稀疏数据,那么什么是稀疏数据呢? 我们知道数据维度就是数据特征,通过特征是否存在来进行分类,那么通常这样数据集就是稀疏数据集。而如果通过数据某一个特征量多少来进行判断通常这样特征就是稠密特征。
不同参数具有不同梯度,
Adagrad 适合稀疏数据,那么什么样数据算是稀疏数据呢?通过特征不同,而不是通过特征量来区分,
RMSProp
这里 RMSProp 与 Adagrad 不同之处,就是计算累积梯度平方方式不同,在 RMSProp 中并没有采用 Adagrad 那样直接累加梯度平方,而是通过一个衰减系数来控制历史梯度信息对当前影响程度
σ0=g0θ1=θ0−σ0ηg0
σ1=ασ0+(1−α)g1θ2=θ1−σ1ηg1
σt=ασt−1+(1−α)gtθt=θt−1−σtηgt
简单总结一下,就是在设置了全局学习率后,每次通过全局学习率除以一个经过衰减系数控制历史梯度平方和平方根,来不断调整每个参数的梯度。起到的效果是在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小),并且能够使得陡峭的方向变得平缓,从而加快训练速度。
Adam(adaptive moment estimation)
在 BERT 和 Transformer 中才采用 Adam 作为优化器。这是因为 adam 优先器实现比较容易,并且占用内存比较少,对于梯度对角缩放具有不变性,而且参数直观具有可解释性。适用于非常嘈杂或稀疏梯度的问题,适合非平稳和非凸优化问题。
Adam 适合高维空间随机优化目标的问题,高维数据给优化问题来带了一定程度上复杂性。对于 Adam 算法来说,仅用一阶梯度占用比较少内存就可以取得不错的效果。其实把 RMSProp 和 SGDM 这两种方法结合的产物。
- t 表示时间,更新步数
- α 学习率,也就是步幅,也就是每一次移动距离
- θ 参数
- f(θ) 目标函数
- gt 参数对于目标函数求导 ∂f/∂θ
- β1 表示一阶矩衰减,指数级衰减
- β2 表示二阶矩衰减
- mt 一阶矩 gt 均值
- vt 二阶矩 gt 方差
- mt^: mt 偏置矫正
- vt^: vt 偏置矫正
矩(momentum)
数学中矩概念和物理中矩的概念是相通的,rnQ 某一个量到参考点 n 次方,物理力就是一阶矩。二阶矩也是惯性是旋转方向的惯性,那么一阶矩是物体保持直线运动的动量,而二阶矩是保持静止或圆周运动的动量。
gt2=gtgt
关于 Adam 实现步骤,从 t-1 时刻或者步骤到 t 时刻,求解参数 θ 的梯度
gt=∇θft(θt−1)
然后更新一阶矩 mt 和二阶矩 vt
mt=β1mt−1+(1−β1)gtvt=β2vt−1+(1−β2)gt2
接下里是对 mt 和 vt 的一个校正,这是对初期平滑偏差较大的一个修正,叫做 bias correction,当 t 越来越大,1−β1t 和 1−β2t 就越趋近于 1
m^t=mt/(1−β1t)v^t=vt/(1−β2t)
θt=θt−1−αv^t+ϵm^t
主要用来一阶矩和二阶矩,更新参数过,一阶矩控制动量,二阶矩左右旋转,指数衰减,开始快后来逐渐减速。Adam 对步长,步长的有界性
gt=∇L^(θt)mt=β1mt−1+(1−β1)gtvt=β2vt−1+(1−β2)gt2
m^t=1−β1tmtv^t=1−β2tvtθt+1=θt−
v^t+ϵηm^t
并且这个优化器具有可解释性。在机器学习许多问题都可以转为求标量的优化问题,也就是我们用标量做优化指标,也就是转换为求最大化或者最小化的问题。
在求解全局最大或最小值过程会遇到许多问题例如,局部最小值、鞍点、平坦区域和悬崖等给梯度下降造成困难的区域。
SGD vs adam
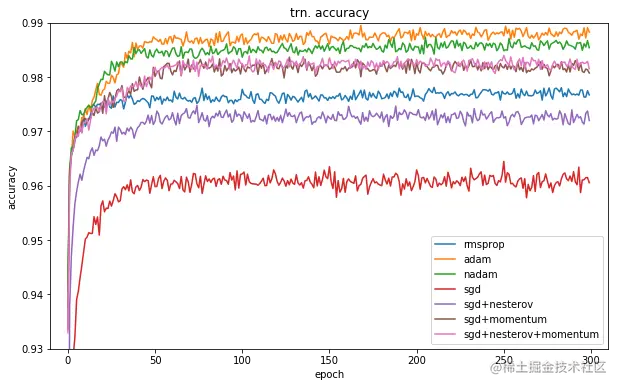
我们注意看这张图,通过一个分类训练通过使用不同分类器对比试验,不难发现 adam 在训练集很快就冲到了前面,而 sgdm 之中位于中上游的位置。
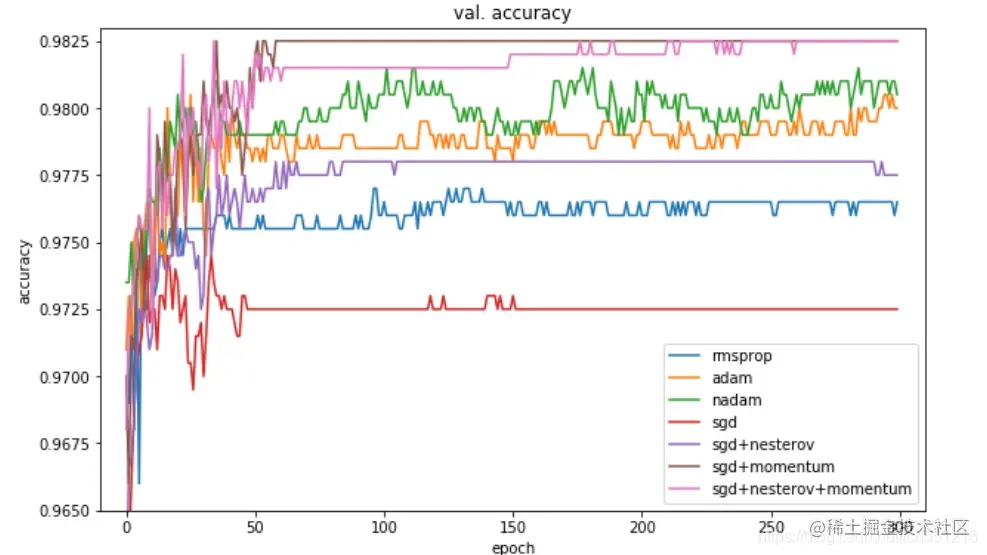
这张图是一个验证阶段,从这张图来看,在验证集上,SGDM 很快就冲到前面,而 adam 在验证集上表现并不是很稳定,一直上下起伏。


