

从Airbnb到Zendesk,大量真正伟大的应用都是使用Ruby编程语言和Rails网络框架构建的。尽管与React、Angular和Vuejs等其他前端框架相比,Rails是一个不太受欢迎的选择,但它在现代软件开发中仍然具有很大的优势。
Rails上的Ruby(RoR)是开源的,有很好的文档,得到了严格的维护,并不断扩展新的Gems--社区创建的开源库,作为标准化配置和发布Ruby代码的 "捷径"。
Rails可以说是其中最大的RoR宝石--一个全栈式的服务器端网络应用程序框架,易于定制和扩展。
什么是Rails?快速复习一下
Rails是建立在模型-视图-控制器(MVC)架构的前提下。
这意味着每个Rails应用都有三个相互关联的层,负责各自的行动。
- 模型:数据层,容纳应用程序的业务逻辑
- 控制器:"大脑中心",处理应用功能
- 视图:定义图形用户界面(GUI)和UI性能
实质上,模型层建立了所需的数据结构,并包含处理HTML、PDF、XML、RSS和其他格式的传入数据所需的代码。然后,模型层将更新信息传达给视图,后者更新GUI。而控制器则同时与模型和视图进行交互。例如,当收到来自视图的更新时,它通知模型如何处理它。同时,它也可以更新视图,告诉它如何为用户显示结果。
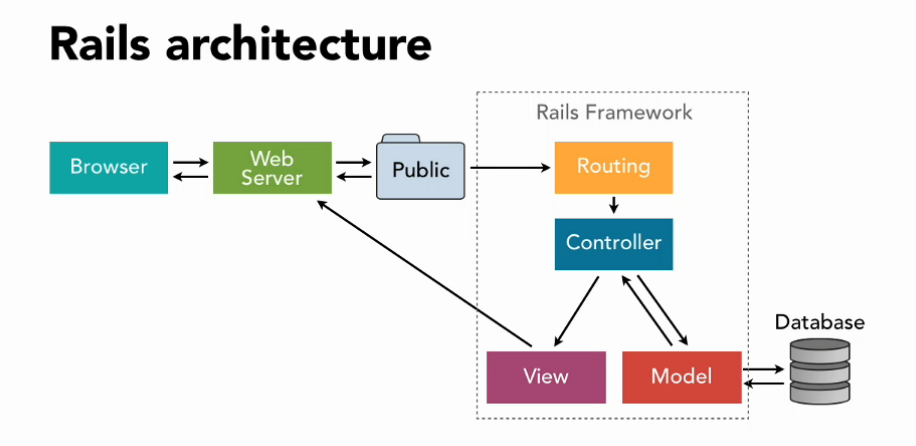
(Rails应用程序的基本架构。图片来源:Medium)
底层的MVC架构为Rails提供了几个重要的优势。
- 平行开发能力--一个开发人员可以在视图上工作,而其他人则处理模型子系统。上述情况也使Ruby on Rails成为快速应用开发(RAD)方法的热门选择。
- 可重用的代码组件--控制器、视图和模型可以被打包,以相对容易地在几个功能中共享和重用。如果做得好,这将导致代码更干净、更可读,以及更快的开发时间。另外,Ruby on Rails是建立在DRY原则之上的(不要重复自己),促使单调功能的代码重用更加频繁。
- 顶级的安全性--该框架有大量以安全为中心的内置功能,如防止SQL注入和XSS攻击,等等。此外,还有大量的社区发送的宝石,解决一系列常见的和新兴的网络安全威胁。
- 强大的可扩展性潜力--GitHub、Twitch和Fiverr等巨型网络应用程序建立在Rails上是有原因的。因为当整个应用架构和部署策略正确时,它的扩展性很好。事实上,最古老的Rails应用之一,Shopify,可以扩展到 每分钟处理数百万个请求(RPM)。
尽管如此,许多Rails指南仍然武断地声称Rails应用难以扩展。 这些是真的吗?不完全是,正如这篇文章将展示的那样。
扩展Rails应用的3个常见问题
传统的传说曾告诉我们,扩展Rails应用程序就像让骆驼穿过针眼一样--令人气愤,令人疲惫。
为了更好地理解这些问题的来源,让我们首先回顾一下什么是Web应用程序的可扩展性。
可扩展性表示应用程序的架构能力,以便在未来每分钟处理更多的用户请求(RPM)。
这里的关键词是 "架构",因为你对基础设施配置、连接和整体布局的选择对整个系统的扩展能力起着决定性作用。你所使用的框架或编程语言对可扩展性只有很小的影响(如果有的话)。
在RoR的情况下,开发人员实际上得到了一点优势,因为该框架提倡干净、模块化的代码,易于与更多的数据库管理系统集成。此外,添加负载均衡器以处理更多的请求也相对容易。
然而,上述情况并不能完全根除Rails的扩展问题。让我们保持现实:当底层基础设施不合格时,任何应用程序都很难扩展。
具体来说,Ruby的扩展问题往往是由于以下原因而出现的。
- 糟糕的数据库查询
- 低效的索引
- 缺乏日志和监控
- 不合格的数据库引擎选择
- 迟缓的缓存
- 过于复杂和混乱的代码
过度工程化的应用程序架构
RoR支持多线程。这意味着Rails框架可以处理代码的不同部分的并发处理。
一方面,多线程是一种进步,因为它使你能够更明智地使用CPU时间,并推出高性能的应用程序。
然而,与此同时,在高度复杂的应用程序中,在不同线程之间进行上下文切换的成本会变得很高。相应地,性能在某些方面开始落后。
如何应对
默认情况下,Ruby on Rails优先考虑干净、可重用的代码。使你的Rails应用架构过于复杂(认为太过定制)确实会导致性能和可扩展性问题。
2007年左右的Twitter就是这样的情况。
该团队在Rails上开发了一个Twitter UI原型,然后决定在Rails上进一步编写后端代码。他们决定从头开始建立一个完全定制的、新颖的后端,而不是修改一些经过测试的组件。不出所料,他们的产品有时表现得很奇怪,而且扩展起来很有挑战性,团队在一次演讲中承认了这一点。由于他们的代码过于复杂和臃肿,他们在划分数据库时最终出现了大量的问题。

图片来源:SlideShare
有趣的是,在同一时间,另一个名为Penny Arcade的高流量Rails网络应用程序却做得很好。为什么呢?因为它没有时髦的过度定制的代码,有明确映射的依赖关系,并且与连接的数据库呼应得很好。
请记住。Ruby支持应用程序中的多进程。在某些情况下,多进程的应用程序可以比多线程的表现更好。但进程的诀窍是它们消耗更多的内存,并且有更复杂的依赖关系。如果你不小心杀死了一个父进程,子进程将不会被告知终止,因此,变成了迟钝的 "僵尸 "进程。这意味着它们会继续运行并消耗资源。所以要注意这些!
次优的数据库设置
在早期,Twitter有密集的写入工作负载和糟糕的读取模式,这与数据库分片是不兼容的。
目前,很多Rails开发者仍在撇开编码适当的数据库索引,并对所有查询的冗余请求进行三重检查。缓慢的数据库查询、缺乏缓存和纠结的数据库索引可以使任何好的Rails应用脱离轨道(双关)。
有时,复杂的数据库设计也是深思熟虑的决定的一部分,我们的一个客户PennyPop就是如此。为了存储应用程序的数据,该团队向Rails应用程序设置了一个API请求。然后,应用程序本身将数据存储在DynamoDB内,并将响应发回给应用程序。该团队没有使用ActiveRecord,而是创建了自己的数据存储层,以实现应用程序和DynamoDB之间的通信。
但他们遇到的问题是,DynamoDB对一个键可以存储多少信息有限制。这是一个技术难题,但开发团队想出了一个有趣的解决方法--将密钥的值压缩成base64编码数据的有效载荷。这样做使该团队能够在应用程序和数据库之间交换更大的记录,而不影响用户体验或应用程序的性能。
当然,上述操作需要更多的CPU。但是,由于他们正在使用Engine Yard来帮助管理和优化其他基础设施,这些成本仍然是可控的。
如何应对
诚然,有许多方法可以提高Rails数据库的性能。随着你的应用程序越来越复杂,故意的缓存和数据库分区(分片)是常见的途径之一。
更棒的是,你有一大堆解决RoR数据库问题的好办法,比如说。
- Redis - 一个用于Rails应用程序的开源内存数据结构存储。
- ActiveRecord - 一个数据库查询工具,规范了对具有内置缓存功能的流行数据库的访问。
- Memcached - 用于Ruby on Rails的分布式内存缓存系统。
上述三个工具可以帮助你充分塑造你的数据库,以容忍超高的负载。
此外,你可以
- 当你的数据库越来越复杂时,在原则键上切换到UUIDs而不是标准IDs。
- 当你的数据库变得特别大的时候,尝试其他的ORM替代ActiveRecord。一些好的方法包括Sequel、DataMapper和ORM Adapter。
- 使用数据库分析工具来诊断和检测早期的速度和性能问题。流行的有 rack-mini-profiler, bullet, rails_panel, 等等。
服务器带宽不足
最后一个问题是基本问题,但仍然普遍存在。如果你缺乏资源,你就无法将你的Rails应用加速到数百万RPM的水平。
当然,有了云计算,配置额外的实例只是几个点击的问题。然而,你仍然需要了解并考虑到。
- 特定应用程序/子系统对额外资源的要求
- 云计算成本(又称速度的货币权衡)。
理想情况下,你需要一些工具来不断扫描你的系统,并确定性能缓慢的情况,资源配置不足(或过度),以及不同应用程序的整体性能基准。
没有这样的工具就像没有速度表的驾驶。你要依靠直觉来确定你是走得太慢还是走得太快了。
如何应对
在Kubernetes上构建和扩展Engine Yard时,我们学到的 一个教训 是,容器平台没有为托管容器设置默认的资源限制。相应地,你的应用程序可以消耗无限的CPU和内存,这可能会产生 "吵闹的邻居 "的情况,即一些应用程序占用了太多的资源,拖累了其他应用程序的性能。
解决方案。从一开始就协调好你的容器。使用Kubernetes Scheduler为吊舱确定合适的节点规模,限制最大的资源分配,并定义吊舱抢占行为。
此外,如果你正在运行容器,一定要设置自己的日志和监控,因为没有开箱即用的解决方案。 在Kubernetes中添加日志聚合,可以为应用程序的行为提供额外的可见性。
在我们的案例中,我们使用。
- Fluent Bit用于分布式日志收集
- Kibana + Elasticsearch用于日志分析
- Prometheus + Grafana用于指标预警和可视化
总结:确保可扩展性的关键是剔除落后的模块,单独优化不同的基础设施和架构元素,以获得更大的累积利益。
扩展Rails应用程序。两种主要方法
与其他应用程序类似,Rails应用程序的扩展有两种方式--纵向和横向。
这两种方法在各自的情况下都有其优点。
垂直扩展
垂直扩展,即为一个应用提供更多的服务器资源,可以增加RPM的数量。基准前提与其他框架相同。你要增加额外的处理器、内存等,直到技术上可行,财务上合理。可以理解的是,垂直扩展是一个临时的 "补丁 "解决方案。
纵向扩展Rails应用程序对适应线性或可预测的增长是有意义的,因为成本控制也会很容易。另外,垂直扩展也是升级数据库服务器的一个好选择。毕竟,缓慢的数据库放在更好的硬件上时,可以得到很大的加速。
硬件是垂直扩展的明显限制。但是,即使你使用的是云资源,垂直扩展Rails应用程序仍然是一个挑战。
例如,如果你打算在Kubernetes上实现垂直吊舱自动缩放(VPA),它就会占到几个限制。
在我们对Ruby应用程序进行扩展的实验中,我们发现。
- VPA是一个相当具有破坏性的方法,因为它破坏了原始的pod,然后重新创建其垂直扩展的版本。这可能会造成很大的混乱。
- 你不能将VPA与Horizontal Pod Autoscaling配对。
因此,只要你能做到,最好优先考虑水平缩放。
水平缩放
水平扩展,即在多个服务器上重新分配你的工作负载,是扩展Rails应用程序的一种更有利于未来的方法。
从本质上讲,你将你的应用程序转换为三层架构,其特点是。
- 连接应用程序的Web服务器和负载平衡器
- Rails应用程序实例(在企业内部或在云中)
- 数据库实例(也是基于本地或云的)。
主要的想法是将负载分布在不同的机器上,以公平地获得最佳性能。
为了有效地在服务器实例之间重新路由Rails进程,你必须选择最佳的Web服务器和负载平衡解决方案。然后根据新解耦的工作负载确定实例的大小。
负载平衡
负载均衡器是扩展架构的关键结构元素。从本质上讲,它们执行路由功能,并帮助在连接的实例之间优化分配进入的流量。
大多数云计算服务都有原生的软件负载平衡解决方案(想想AWS的弹性负载平衡 )。这种解决方案也支持动态主机端口映射。这有助于在注册的网络平衡器和容器实例之间建立无缝配对。
谈到Rails应用程序,两个最常见的选择是使用网络服务器和应用程序服务器的组合(或融合服务),以确保最佳性能。
- 网络服务器将用户请求转移到你的网站,然后将其传递给Rails应用(如果适用)。从本质上讲,它们过滤掉了对CSS、SSL或JavaScript组件的不必要的请求(服务器可以自己处理),从而将对Rails应用程序的请求数量减少到最低限度。
- Rails网络服务器的例子:Ngnix和Apache。
- 应用程序服务器是在内存中维护你的应用程序的程序。这样,当一个来自Web服务器应用程序的传入请求出现时,它就会被直接路由到应用程序进行处理。然后,响应被弹回给网络服务器,并随后弹回给用户。当与生产中的Web服务器配对时,这样的设置可以让你更快地呈现对多个应用程序的请求。
- Rails的应用服务器的例子:Unicorn, Puma, Thin, Rainbows。
最后,还有一些 "融合 "服务,如Passenger App(Phusion Passenger)。这项服务与流行的网络服务器(Ngnix和Apache)集成,并带来了一个应用服务器层--可用于独立的和与网络服务器组合使用。
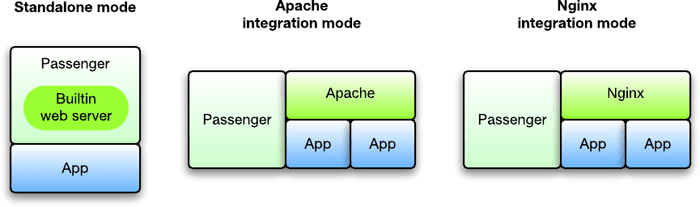
图片来源:Phusion Passenger
如果你想一次性为一堆应用推出统一的应用服务器设置,而不需要为每个应用单独设置应用服务器,那么Passenger是一个很好的选择。
简而言之,使用Web和应用服务器的主要想法是在不同的实例中最佳地跨越不同的rails流程。
专业提示:我们在构建产品时发现,AWS的弹性负载平衡器往往不能满足需要。一个主要的缺点是,ELB不能处理多个vhosts。
在我们的案例中,我们继续配置了一个基于NGINX的负载平衡器,并在其上配置了自动缩放功能,以支持ELB。作为一个替代方案,你也可以尝试HAProxy。
应用程序实例
横向扩展架构的下一步是配置不同应用实例之间的通信,你的Rails工作负载将被分配到这些实例中。
应用服务器(Unicorn、Puma等)有助于确保Web服务器之间的正常通信,并随后增加每秒处理请求的吞吐量。在Rails上,你可以分配一个应用服务器来处理多个应用实例,这些实例又可以有独立的 "工人 "进程或线程(取决于你使用哪种类型的应用服务器服务)。
然而,重要的是,要确保不同的应用服务器能够与网络服务器进行良好的通信。 Rack接口在这里很方便,因为它有助于在独立的应用服务器之间实现同质化通信标准。
当谈到为容器配置正确的实例时,请记住以下几点。
- 你有四个变量来调节最小/最大CPU和最小/最大内存的pod大小
- 使用[最低要求+20%]公式限制资源
- 使用平均CPU利用率和平均内存利用率作为扩展指标
- 注意时间。在Kubernetes上,Pod和集群需要4到12分钟来扩展。
P.S.如果你不想在每次构建新的pod/cluster时做上述的猜测,Engine Yard带有预测集群扩展功能,它可以帮助你及时扩展你的基础设施,而不会使成本膨胀。
数据库的扩展
将数据库转移到一个单独的服务器上,由所有的应用程序实例使用,是你可以用来扩展Rails应用程序的最时尚的举措之一。
首先,这可以成为隔离数据和实施数据库复制以提高业务连续性的一个好办法。其次,这样做可以减少查询时间,因为请求不必通过存储不同数据位的多个数据库实例来处理。相反,它将直接进入一个综合存储库。
因此,考虑为你的关系型数据库建立一个专门的MySQL或PostgreSQL服务器。然后将它们擦洗干净,并确保最佳实例大小,以节省成本。
例如,AWS RDC让你在18种类型的数据库实例中进行选择,并编入细粒度的配置。选择在一个更便宜的云区域托管你的数据可以推动大量的成本节约(有时高达40%!)。
以下是AWS各地区按需小时费用的不同。
美国东部(俄亥俄州)
- db.t3.small - 每小时0.034美元
- db.t3.xlarge - 每小时0.272美元
- db.t3.2xlarge - 每小时0.544美元
美西(洛杉矶)
- db.t3.small - 每小时0.0408美元
- db.t3.xlarge - 每小时0.3264美元
- db.t3.2xlarge - 每小时0.6528美元
欧洲(法兰克福)
- db.t3.small - 每小时0.04美元
- db.t3.large - 每小时0.16美元
- db.t3.2xlarge - 每小时0.64美元
亚太地区 (首尔)
- db.t3.small - 每小时0.052美元
- db.t3.large - 每小时0.208美元
- db.t3.2xlarge - 每小时0.832美元
另一个建议:如果可以的话,选择保留的实例而不是按需的,以进一步削减每小时的费用。
缓存
数据库缓存的实施是加速Rails应用程序的另一个核心步骤,尤其是在涉及到数据库性能时。鉴于RoR具有原生的查询缓存功能,可以缓存每次查询返回的结果集,因此不从中获利是很可惜的。
缓存可以帮助你加快那些缓慢的查询。但是,在实施之前,要进行调查!一旦你找到了 "违法者",就要考虑尝试不同的策略,比如。
- 低级别的缓存--对任何类型的缓存检索数据库查询都是最有效的。
- Redis缓存存储--让你在内存中存储键和值对,最大可达512MB,另外还提供本地数据复制。
- Memcache存储--另一个易于实现的内存数据存储,数值限制在1MB。支持多线程架构,与Redis不同。
最终,缓存提高了数据的可用性,并通过代理提高了你的应用程序的查询速度和性能。
数据库分片
最后,在你的数据库扩展旅程中的某个时刻,你将不可避免地面临着将你的关系型数据库分片的决定。
数据分片意味着将你的数据库记录水平或垂直地切成更小的块(分片),并将它们存储在数据库节点的集群上。确切的好处是,现在的查询应该更快,因为一个大的数据库被一分为二,有两倍的内存、I/O和CPU可以运行。
然而,代价是,分片会大大影响你的应用程序的逻辑。每个查询的范围现在只限于DB 1或DB 2 - 没有混合。因此,在添加新的应用功能时,你需要仔细考虑如何跨分片访问数据,共享与基础设施的关系,以及在不影响应用逻辑的情况下扩展支持性基础设施的最佳方式是什么。
总结一下:是否有更简单的解决方案来扩展Rails应用程序?
扩展Rails应用程序是一种谨慎的平衡行为,要确保最佳的实例分配、及时的资源配置和谨慎的容器协调。在应用程序和子服务的组合中保持对所有相关指标的监控,在手动操作时并不是一件容易的事。而且不应该是这样。
