

在WiredTiger中整合对非易失性存储器的支持
英特尔Optane DC持久性存储器是一种非易失性存储器(NVRAM)产品,它既像存储也像内存,可以作为其中之一使用。像存储一样,Optane NVRAM在崩溃或断电后能保留数据。与内存一样,它位于内存总线上,可由CPU使用加载/存储指令访问。在某些情况下,它的访问延迟甚至接近动态随机存取存储器(DRAM)的延迟。
在MongoDB,我们一直在考虑如何在存储引擎中使用NVRAM。它可以被看作是易失性DRAM的延伸,但密度更大,价格更低。为了追求这个目标,我们用一个易失性NVRAM缓存来扩展我们的存储引擎WiredTiger,该缓存保留了经常使用的文件块。
在这篇文章中,我们分享了我们的经验,描述了学到的教训,并评估了这种方法的成本和效益。
如何在存储栈中使用NVRAM
Optane NVRAM可以同时充当存储和内存。持久性内存结构本身可以被包装成固态驱动器(SSD),如Optane SSD,或者包装成双线内存模块(DIMM),看起来几乎与DRAM的同类产品一样,并住在主板上的同一类型的插槽中。
即使NVRAM被包装成非易失性DIMM(NVDIMM),我们也可以要求操作系统将其作为一个块设备,在上面放一个文件系统,并像普通存储一样使用它。
大体上说,有三种方式可以使用NVRAM:
-
作为常规存储
-
作为持久性存储器
-
作为易失性存储器的扩展
NVRAM作为存储
将NVRAM作为常规存储,可以为以读为主的工作负载提供卓越的吞吐量(与SSD相比),但这种方法阻碍了以写为主的工作负载,因为Optane NVRAM的写吞吐量有限(见 "Optane NVRAM的性能属性 "一节)。在任何情况下,NVRAM的价格和密度都更接近于DRAM,而不是SSD,因此不建议将其用作存储。
NVRAM作为持久性存储器
想象一下,你所有的数据结构都存在于内存中,你永远不必担心将它们保存到文件中。它们就在那里,即使在你退出你的应用程序或它遭遇崩溃后也是如此。尽管这种设置听起来很简单,但在实践中,为这种模式进行编程仍然很有挑战性。
如果你的系统崩溃了,你希望在重启后能够找到你的数据,你需要给它命名。一个变量名是不够的,因为它不是唯一的;因此,你必须重组你的代码,确保你的数据有持久的标识符。持久性内存开发工具包(PMDK)提供了这方面的API。
一个更困难的问题是在崩溃中生存。你的程序可能在对数据结构进行逻辑操作的过程中崩溃。例如,假设你正在向一个链接列表中插入一个项目,你已经设置了源指针,但崩溃发生在设置目标指针之前。重新启动后,你会得到损坏的数据。更糟的是,即使逻辑操作在崩溃前已经完成,数据也可能只被写入CPU缓存,而没有被持久化到内存本身。
一种解决方案是将内存操作包裹在事务中;然而,对事务性内存进行编程是众所周知的困难。另一个解决方案是使用预包装的数据结构和API,但如果你想创建自己的高度优化的数据结构,你必须实现自己的日志和恢复或其他机制,以保护你的数据类似于事务。
NVRAM作为易失性存储器的扩展
有点反直觉的是,这个选项涉及到无视NVRAM的持久性,将其作为DRAM的易失性扩展。你为什么要这样做呢?假设你有一个固定的预算来为你的系统购买额外的内存。你要么买得起NGB的DRAM,要么买得起大约M*NGB的NVRAM--这是因为NVRAM密度大,每字节的价格比DRAM便宜(在撰写本文时,大约便宜三倍)。根据你的应用,如果你购买额外的NVRAM,而不是DRAM,你可能会在性能/美元方面更有优势。
为了支持这种使用情况,英特尔提供了一种硬件机制,称为内存模式,它将NVRAM视为 "常规 "系统内存,并将DRAM作为其缓存。换句话说,硬件将尽力把经常使用的数据结构放在DRAM中,其余的放在NVRAM中。这种机制的好处是,它完全不需要对应用程序进行修改。缺点是,对于某些工作负载,它的性能可能比定制的解决方案要差(见 "NVCache如何影响性能 "一节)。
我们的解决方案是一个自定义的、驻留在NVRAM中的易失性缓冲区。
我们的架构
我们的NVRAM缓存(或NVCache)是MongoDB存储引擎WiredTiger的一个组件。对于持久性存储,WiredTiger将数据组织成块,其中的键和值被有效地编码并(可选择)压缩和加密。为了快速查询其B+树数据结构,WiredTiger将块转化为页,其中的键/值被解码和索引。它在其DRAM页面缓存中保存页面。

**图1.**NVCache的结构。
图1显示了NVCache的结构。NVCache是一个新的组件,其余的都是WiredTiger的一部分。NVCache位于块管理器旁边,块管理器是负责从持久性存储中读/写数据的代码。让我们依次看一下每个路径。
**读取路径。**如果页面缓存不能找到搜索到的数据,它就会向块管理器发出读取指令(1)。区块管理器检查该区块是否存在于NVCache中(2),如果存在则从NVCache中访问它(3),如果不存在则从磁盘中读取它(4)。然后,区块管理器将区块转换成一个页面,如果需要的话,对其进行解密和解压,然后将其交给页面缓存(5)。它还通知NVCache它已经读取了一个新的区块,然后NVCache可以自行决定是否接受它(6)。NVCache以与存储在磁盘上相同的格式来存储这些块(例如,如果选择了这些配置选项,则压缩或加密)。
**写入路径。**写入路径与读取路径不同,WiredTiger不在原地修改磁盘块。它将更新写入内存中的数据结构,然后将其转换为新的页面,这些页面将在从页面缓存中驱逐或在检查点期间被发送到磁盘(7)。当区块管理器收到一个新的页面时,它将其转换为一个新的区块,将该区块写入存储区(8),并通知NVCache(9)。然后,NVCache有权决定是否接受它。过时的块最终会被释放,这时块管理器会指示NVCache使缓存的副本失效(10)。为了避免空间耗尽,NVCache会定期驱逐不常用的块。驱逐线程每秒钟运行一次。
总的来说,这种设计是简单明了的,但要使其具有高性能是一个挑战。正如对全新的存储或内存设备所预期的那样,软件必须迎合其独特的性能属性。在下一节中,我们将重点讨论这些性能特性,并解释我们是如何调整我们的缓存以适应这些特性的。
Optane NVRAM的性能特性
在低带宽情况下,Optane NVRAM的访问延迟接近DRAM的访问延迟。小规模的读取需要大约160至300纳秒,这取决于它是顺序访问模式的一部分还是随机访问模式1;从DRAM读取需要大约90纳秒。
在高带宽的情况下,我们通常看的是吞吐量。单个NVDIMM1,2的连续读取吞吐量约为6GB/s,并且随着你添加更多的内存模块而线性扩展。(一个第二代英特尔至强可扩展处理器可以支持多达六个NVDIMMs)。写入吞吐量比较有限。我们观察到单个NVDIMM2的速度高达0.6GB/s,而其他人观察到的速度高达2.3GB/s。3同样,如果你的工作负载写入不同的NVDIMM,吞吐量将随着系统中的模块数量而扩展。
关于写吞吐量的一个有点麻烦的观察是,当你添加更多的线程时,它的扩展是负面的。写入吞吐量在一个或两个并发线程时达到峰值,然后随着线程的增加而下降。2,3更重要的是,我们惊讶地发现,在Optane NVRAM上,写入器的存在会不成比例地影响读取器的吞吐量。
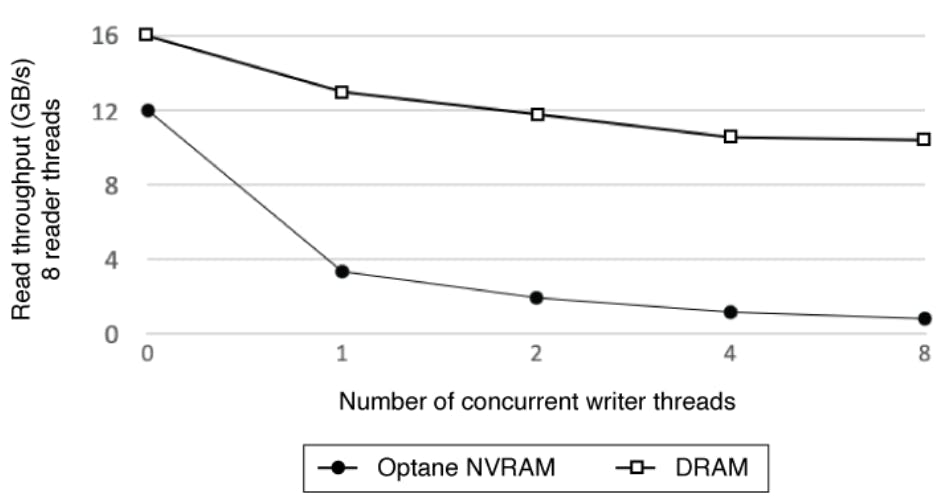
**图2.**在有并发写入器线程的情况下的读取吞吐量。
图2显示了八个读者线程的吞吐量是如何随着更多并发写者的加入而下降的。虽然这种影响在DRAM和NVRAM上都存在(当然在其他存储设备上也存在),但在Optane NVRAM上,这种影响要明显得多。在有写的情况下,读的性能会受到影响。这一重要的观察结果推动了我们对NVCache的设计。
在Optane NVRam的缓存中节制写操作
为了使缓存发挥作用,它必须包含受欢迎的数据。吸收新数据和清除旧数据的职责分别落在缓存的接纳和驱逐政策上。接纳和驱逐都会产生写入,由于写入会损害Optane上的读取性能,接纳和驱逐会干扰缓存检索的性能(涉及读取)。
因此,我们有一个权衡:一方面,接纳和驱逐是使缓冲区有用的关键。另一方面,它们产生的写操作会妨碍数据检索的性能,从而使缓存的性能降低。
为了解决这一矛盾,我们引入了开销旁路(OBP)指标,它是应用于缓存的读和写的比率。把这个比率保持在一个阈值之下,我们就可以限制写的开销。
OBP = (block_inserted + blocks_deleted) / blocks_looked_up
直观地说,block_looked_up与使用缓存的好处相关,而block_inserted和block_deleted之和与成本相关。NVCache通过节流来保持这个比例在10%以下。(我们的源代码可以在WiredTiger的公共GitHub仓库中找到)。
如果没有OBP,数据接纳和驱逐的开销是相当大的。为了测量这种最纯粹的开销,我们用那些不能从任何额外的缓存中受益的工作负载进行了实验,比如那些适合操作系统缓冲区缓存(在DRAM中)的小数据集,或者那些执行大量写入操作以至于很快使任何缓存数据失效的工作负载。我们发现,在没有OBP功能的情况下,使用NVCache会使这些工作负载的运行速度比没有缓存时慢两倍。
引入OBP后,完全消除了开销,使那些能从额外的缓存中受益的工作负载享受到更好的性能。
NVCache是如何影响性能的
在这一节中,我们将详细研究具有大型数据集的工作负载的性能,这些工作负载可以从额外的缓存中受益。
实验系统:下面的实验是在联想ThinkSystem SR360上进行的,它有两个Intel Xeon Gold 5218 CPU。每个CPU有16个超线程核心。该系统有两个英特尔Optane持久性内存模块,每个126GB。对于存储,我们使用了英特尔Optane P4800X SSD。我们的系统只配置了32GB的DRAM,以确保NVRAM形式的额外内存会被要求使用。
我们用广泛使用的YCSB基准4,5来展示数据(表1),尽管我们也用我们的内部基准进行分析并得出类似的结论。
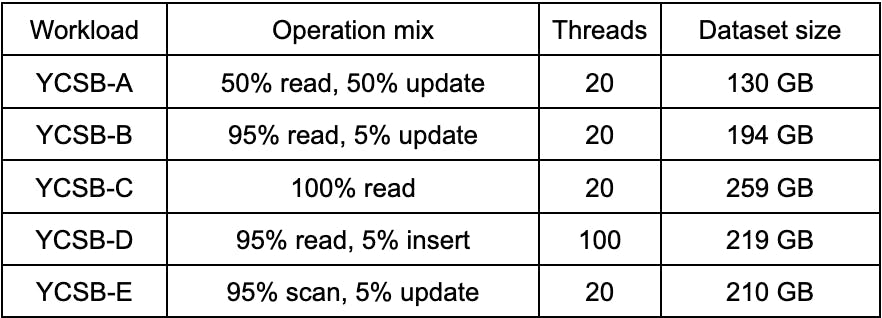
表1. YCSB基准的特点
下面的图表比较了YCSB与NVCache、英特尔内存模式(MM)和OpenCAS6--英特尔的NVRAM驻留缓存的内核实现的吞吐量。OpenCAS被配置为绕写模式,这是限制写的有害影响的最佳选择。
图3a-c显示了分别使用63GB、126GB和252GB的NVRAM配置的数据。
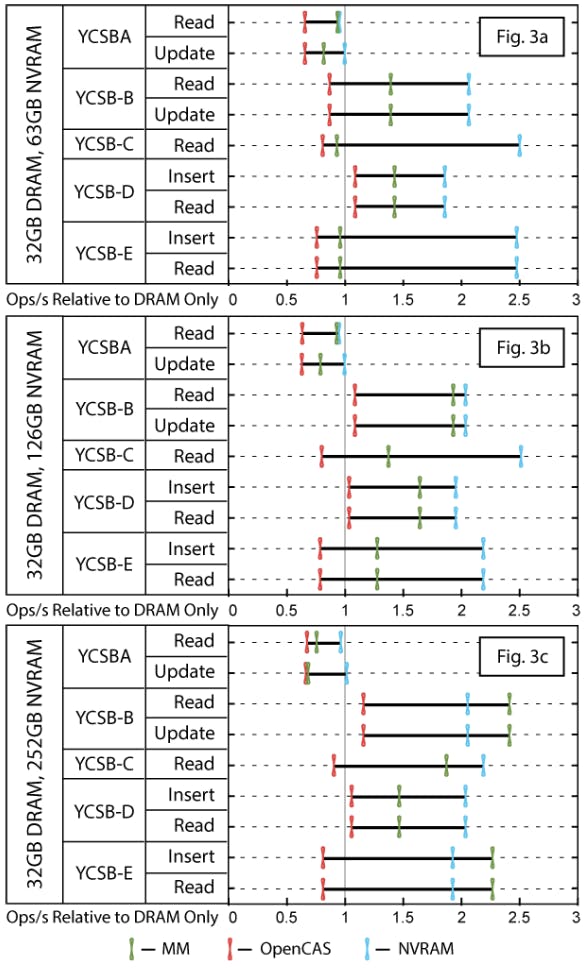
图3. YCSB在内存模式(MM)、OpenCAS和NVCache下的吞吐量与只使用DRAM的运行情况相比。
我们提出以下三点意见。
OpenCAS缓存没有从额外的NVRAM中获得性能优势。它实现了与NVCache相似或更好的读取命中率,但同时也向NVRAM进行了两个数量级的写入,这可能是因为它没有节制接纳的速度。写入干扰了读取的性能,这可能就是为什么这个缓存没有带来性能上的好处。
当数据集的大小超过NVRAM的容量时,NVCache提供的性能大大优于Memory Mode。如图3a所示,NVCache比内存模式好30%(对于YCSB-B)到169%(对于YCSB-C)。此外,相对于纯DRAM基线,内存模式使YCSB-A的更新吞吐量减少了18%,而NVCache则没有。
在NVRAM充足的情况下,内存模式的表现与NVCache相当。在252GB的NVRAM中,所有的数据集都可以轻松地放入NVRAM中。有两个因素可以解释为什么在NVRAM充足的情况下,NVCache失去了对MM的优势:(1)对于NVCache来说,在126GB之后,额外的NVRAM的边际效用很小;当我们把NVRAM的大小从63GB增加到126GB时,NVCache的命中率增长了大约20%,但如果我们把它从126GB增加到252GB,则只增长了另外5%。(2) MM允许内核缓冲区缓存扩展到NVRAM中,而NVCache将其限制在DRAM中,这也被WiredTiger的页面缓存所使用。对DRAM的争夺限制了性能。
总的来说,定制的NVRAM缓存解决方案的好处是,它为大型工作负载提供了比内存模式更好的性能。缺点是它需要新的软件,而MM可以在不改变应用程序的情况下使用。
性能和成本
在本节中,我们探讨了使用Optane NVRAM作为DRAM的易失性扩展与仅仅使用更多的DRAM之间的权衡。为此,我们采用了96GB的固定内存预算,并改变了由DRAM和NVRAM满足的部分,如表2所示。
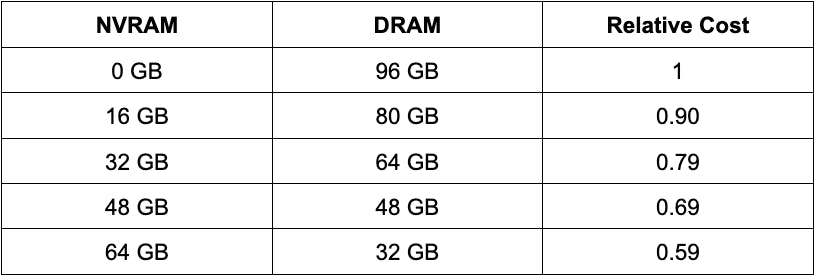
表2. 包含DRAM和NVRAM的内存配置相对于只使用DRAM的预算。我们使用NVRAM与DRAM的价格比率为0.38。
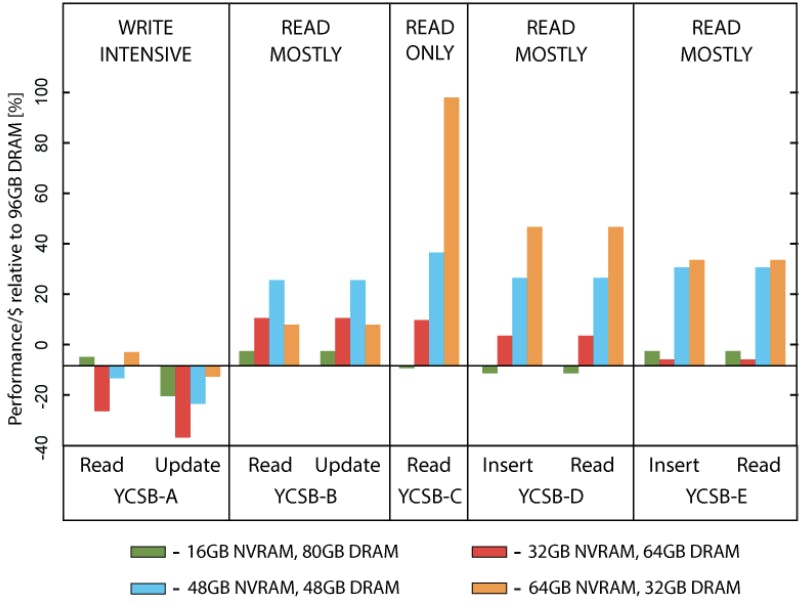
图4. 随着NVRAM数量的增加和DRAM数量的减少(在YCSB工作负载中),每美元的性能。
图4显示了在这些配置下YCSB的性能,归一化为使用96GB DRAM,并除以第3列的成本比率。换句话说,这些是相对于纯DRAM配置的性能/美元的数字。在这些实验中,我们只使用了NVCache来管理NVRAM,因为它的性能与其他选项相当或更好。
正数意味着性能的下降小于内存的成本。受益于NVCache的只读或主要读的工作负载经历了一个正的收益,正如预期的那样。
尽管在大多数情况下,随着DRAM数量的减少,性能可以预测地下降,但配置64GB NVRAM和32GB DRAM的YCSB-C比配置96GB DRAM的性能更好--所以我们降低了系统成本,并提高了绝对性能。这是因为超过32GB的DRAM,额外的内存(和更大的页面缓存)的效用远远小于较小的NVCache带来的性能损失。
YCSB-A,它的写入强度使它无法从任何额外的缓存中得到好处,在性能/美元方面遭受了总体损失。当我们减少DRAM的数量时,其性能的下降速度比内存成本的下降速度更快。
我们的结论是,NVRAM是一种具有成本效益的方法,可以降低内存成本,同时平衡对以读为主的工作负载的性能影响。同时,与DRAM相比,即使有少量的写入也会使NVRAM无利可图。
