

在事件驱动的架构中,当我们面对一个单片机应用时,常见的情况之一是如何从单片机数据库中获取大量的数据。当我们必须考虑到数据库的稳定性和正常运行时间时,这项任务变得更加复杂。我们不能在特定的时间内关闭整个数据库来获取数据的快照,即使我们可以,我们如何处理主数据库的变化?
所以,让我们把问题分成两块:
- 从数据库中获取一大组数据(甚至是全部)的内容
- 同步变化
为了找到这些问题的答案,我们需要指定数据的目标。我们希望我们的数据在最后落在哪里!?这个问题的答案并不像它看起来那么简单。下面的答案只是一些小的可能性:
- 一个具有数据库引擎的目标数据库,例如从Postgresql源到Postgresql目标
- 目的地数据库使用不同的引擎,甚至是不同的DBMS,例如从Postgresql到Mysql。
- 一个具有不同范式的目的地数据存储,例如从关系型数据库到Elasticsearch或反之亦然。
- 一个目标云存储
- 一个事件代理
- 一个简单的JSON文件!这个列表可以包含一打的可能性。虽然在一个受控的环境中,我们可以决定提前消除很多可能性,但我们的列表上仍然有很多项目,这意味着我们的解决方案需要支持一个良好的抽象和灵活性。
因此,让我们开始寻找/构建解决方案。
数据读取器和适配器
让我们来解决第一个挑战,获取数据。基本上,如果我们从一个高层次的角度来看,忽略所有的细节,我们就会发现我们所需要的只是一组读取器和适配器
- 读取器:从源头上读取数据
- 适配器:将数据写到目的地
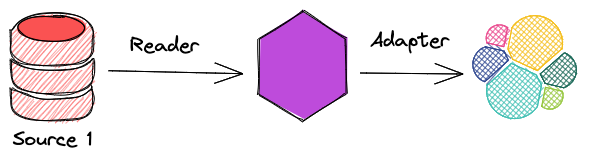
然而,通常情况下,由于有多个来源和目的地,情况会更加复杂
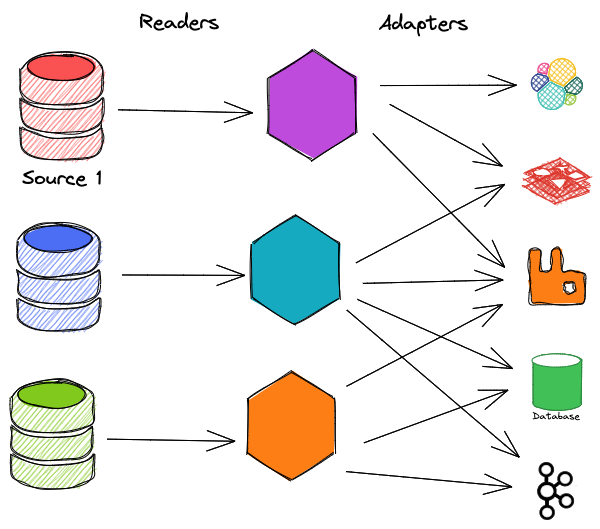
这个解决方案当然是可行的,但有几个注意事项需要考虑。
- 读者或适配器的规模都不容易。例如,我们如何处理一个有数百个表的数据库,每个表有数百万条记录?一个可能的解决方案是为每个表运行一个读者和一个适配器,但我们需要以某种方式解决目的地数据库中的外键。
- 我们可能需要为读取器和适配器提供额外的存储空间来实现这一任务,这很难使这一过程可恢复。
- 尽管在我们的读取器和适配器中不应该有任何复杂的逻辑,但我们仍然要为开发和维护这些应用程序付出很多努力。
除了上述问题外,好消息是我们至少可以解决第一个挑战,不是吗?
使用触发器来同步变化
将数据从源头倾倒到目的地只是我们挑战的第一部分。我们需要确保发生在源数据中的所有变化(创建、更新、删除)都落在目标数据源中,换句话说,源和目标最终必须是一致的。最简单的解决方案是使用触发器。下面是维基百科中对触发器的定义。
数据库触发器是程序性代码,在数据库中的特定表或视图上发生某些事件时自动执行。触发器主要用于维护数据库中信息的完整性。
因此,我们可以在特定类型的事件后以某种方式触发一段代码。太棒了,这正是我们想要的。我们需要做的就是在源数据库中定义触发器,将变化反映到目标数据库中。下面是一个粗略的例子,说明它将是怎样的。
CREATE TRIGGER onProductInsert ON product
FOR INSERT
AS
INSERT INTO product_replica
(productName, quantity, color)
SELECT
(productName, quantity, color)
FROM inserted
这听起来像是一个计划,但触发器的功能是有限的。例如,想想这些情况:向Kafka主题产生一个消息,向MongoDB插入一个文档,或者更新Redis中一个特定的缓存项目的值,即使有可能在一个触发器中完成所有这些,也不是很容易。
使用Kafka和Kafka Connect
到目前为止,我们已经找到了一个解决方案,但它应该是一个更有效的方法来解决这个问题。Apache connect正是我们需要的,我们可以有效地解决这两个难题。
以下是Confluent公司对Kafka connect的定义
Kafka Connect是Apache Kafka®的一个免费的开源组件,它作为一个集中的数据中心,用于数据库、键值存储、搜索索引和文件系统之间的简单数据整合。这里提供的信息是专门针对Confluent平台的Kafka Connect。
Kafka connect包含两个部分:
- 连接器负责从源头读取数据并将其发布到Kafka集群中
- Sinks作为消费者连接到Kafka Cluster,获取数据,并将其放入目标数据存储。
所以连接器就是我们所说的数据读取器,而汇就是我们所说的数据适配器,到目前为止。好消息是,Confluent Hub中已经有了大量的Sinks和Connector,可以让我们的生活更轻松。
所以我们的整体架构几乎变成了这样:
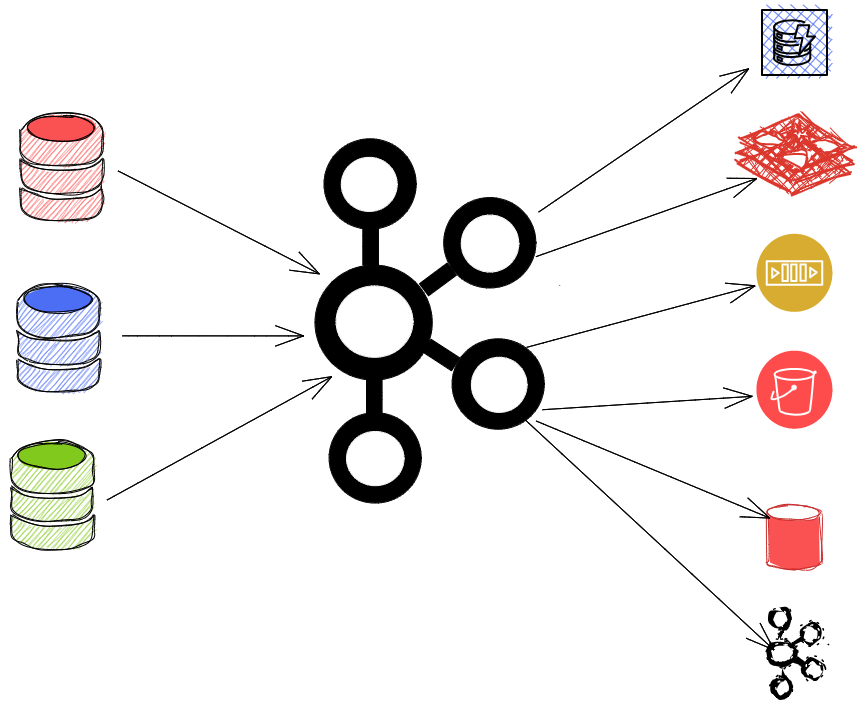
好了,让我们动手吧,使用Kafka connect,看看它的魔力。
我们需要的第一件事是一个Kafka集群。Kafka使用Zookeeper进行配置管理,更重要的是共识。他们正在实施自己的基于KRaft的共识算法,但还没有准备好用于生产。
我使用docker compose来设置整个堆栈,因为它很容易使用,而且在开发者之间被广泛接受:
version: "3.9"
services:
zookeeper:
image: confluentinc/cp-zookeeper:6.2.1
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:6.2.1
container_name: broker
depends_on:
- zookeeper
ports:
- "29092:29092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
配置很简单,你只需要把几个配置和zookeeper地址一起作为环境变量传递给Kafka集群。
那么让我们来谈谈Kafka Connect以及它是如何工作的。"Kafka connect "作为一个worker运行,所以我们可以像其他独立的服务一样在虚拟机、AWS、GCP、Kubernetes中部署它。从技术上讲,它只是一个Java应用程序。它也有一个HTTP API服务器,默认运行在端口8083 。
"Kafka Connect "是可扩展的,你可以(应该)在分布式节点中运行它。这意味着集群中的每个节点必须以某种方式知道其他节点的状态。例如,当一个节点突然被添加到集群中时,它必须找到问题的答案,如:当前的任务是什么? 正在运行的任务的状态是什么? 其他节点现在正在处理的记录是什么? 我应该拿起什么!?
毫不奇怪,"Kafka Connect "使用 "Kafka Cluster "本身来保持任务的状态。
那么,我们可以期望用这些信息来设置 "Kafka connect "呢?让我们想一想,由于它作为一个独立的应用程序,必须与我们的Kafka集群进行连接和对话,所以它肯定需要集群的连接信息。由于它使用Kafka来保持状态,它还需要几个内部主题来管理节点之间的状态。
"Kafka Connect "还可以通过Protobuf、Avro和JSON使用并验证输入和输出数据的模式。我们必须在模式注册表中定义我们的模式,然后Kafka在生产和消费的步骤中只需拥有模式ID就能简单地处理数据的模式。为了简单起见,在本教程中,我们忽略了模式管理和验证。 毕竟,"Kafka Connect "的配置看起来像这样:
schema-registry:
image: confluentinc/cp-schema-registry:6.2.1
container_name: schema-registry
depends_on:
- broker
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'broker:9092'
SCHEMA_REGISTRY_LOG4J_ROOT_LOGLEVEL: WARN
connect:
container_name: connect
build:
context: .
dockerfile: connect.Dockerfile
environment:
CONNECT_BOOTSTRAP_SERVERS: 'broker:9092'
CONNECT_GROUP_ID: 'connect'
CONNECT_CONFIG_STORAGE_TOPIC: 'data-transformer-config'
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_STORAGE_TOPIC: 'data-transformer-offset'
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_TOPIC: 'data-transformer-status'
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE: "false"
CONNECT_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
VALUE_CONVERTER_SCHEMAS_ENABLE: "false"
CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
CONNECT_REST_ADVERTISED_HOST_NAME: "localhost"
depends_on:
- broker
ports:
- "8083:8083"
到目前为止,我们只是旋转了一个 "Kafka connect "实例,我们如何告诉这个实例在源和目的地之间运送数据?正如我们前面所描述的,Kafka Connect通过连接器来完成这个任务。连接器是由社区开发的简单的Java应用程序。其中一个从数据库中获取数据的神奇连接器是debezium
debezium是做什么的,它是如何工作的
你还记得最初的问题吗?我们想为这些问题找到一个解决方案:
- 从数据库中获取大量的数据(甚至是全部的)
- 同步变化
debezium对这两个问题都有惊人的解决方案,而且它的可扩展性和Kafka连接本身的可扩展性一样。
对于获取数据来说,它只是简单地将数据库中的当前数据进行快照,并将其送入Kafka。但在CDC部分,它使用Write-Ahead日志(Mysql的二进制日志)来获取领导节点的变化。使用WAL是触发器的一个很好的选择。它的速度快得惊人,效率高,可扩展性强,而且对领导节点的肩部没有负担。在我们的Kafka Topic中拥有数据的延迟和跟随者节点获得最新的变化一样快。
如果你不知道什么是Write-Ahead Log(WAL),你可以把它想象成一个简单的只读文件,其中有领导者节点中所有的INSERT、UPDATE和DELETE命令。每当有DML命令发送到数据库引擎,它就会把命令写入WAL文件中。所以我们只要按顺序运行文件中的命令,就可以回复所有的变化。值得一提的是,这只是一个超级简化的解释,是为了更好地理解它。数据库引擎使用更优雅的解决方案来使用WAL文件。
为了让Debezium完成它的工作,我们需要稍微改变一下Postgres的配置,并添加一些权限。Debezium有一个特殊的Docker镜像,基于官方的Postgres镜像,并有一些小的改动:
product_db:
image: debezium/postgres:13
container_name: productdb
restart: always
environment:
POSTGRES_PASSWORD: secret
POSTGRES_DB: product_db
ports:
- "5400:5432"
我们最终的docker-compose.yml 文件应该是这样的:
version: "3.9"
services:
product_db:
image: debezium/postgres:13
container_name: productdb
restart: always
environment:
POSTGRES_PASSWORD: secret
POSTGRES_DB: product_db
ports:
- "5400:5432"
zookeeper:
image: confluentinc/cp-zookeeper:6.2.1
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
broker:
image: confluentinc/cp-kafka:6.2.1
container_name: broker
depends_on:
- zookeeper
ports:
- "29092:29092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://broker:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
schema-registry:
image: confluentinc/cp-schema-registry:6.2.1
container_name: schema-registry
depends_on:
- broker
ports:
- "8081:8081"
environment:
SCHEMA_REGISTRY_HOST_NAME: schema-registry
SCHEMA_REGISTRY_KAFKASTORE_BOOTSTRAP_SERVERS: 'broker:9092'
SCHEMA_REGISTRY_LOG4J_ROOT_LOGLEVEL: WARN
connect:
container_name: connect
build:
context: .
dockerfile: connect.Dockerfile
environment:
CONNECT_BOOTSTRAP_SERVERS: 'broker:9092'
CONNECT_GROUP_ID: 'connect'
CONNECT_CONFIG_STORAGE_TOPIC: 'data-transformer-config'
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_STORAGE_TOPIC: 'data-transformer-offset'
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_TOPIC: 'data-transformer-status'
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_KEY_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
CONNECT_KEY_CONVERTER_SCHEMAS_ENABLE: "false"
CONNECT_VALUE_CONVERTER: "org.apache.kafka.connect.json.JsonConverter"
VALUE_CONVERTER_SCHEMAS_ENABLE: "false"
CONNECT_KEY_CONVERTER_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
CONNECT_VALUE_CONVERTER_SCHEMA_REGISTRY_URL: "http://schema-registry:8081"
CONNECT_REST_ADVERTISED_HOST_NAME: "localhost"
depends_on:
- broker
ports:
- "8083:8083"
我们可以通过运行docker-compose up -d 来启动所有的服务。你可以通过运行docker-compose ps 来改变你的设置。你会看到的应该是这样的:

好了,如果你还在看这个教程,你真的很想了解更多关于Kafka Connect的知识。到目前为止,我们所做的只是运行了几个服务,并把它们连在一起。我的意思是,到目前为止,我们真的什么都没做!幸运的是,剩下的事情会更容易,因为我们把大部分的工作交给了经过良好测试的Kafka连接器。
现在,是时候告诉连接器去做它的工作了。如果你看一下配置,我们仍然没有告诉连接器它们应该连接到哪个数据库我们必须通过为我们提供的HTTP APIs将我们的连接器定义为 "Kafka Connect"。每个连接器都有一套配置,对该连接器来说是一种独特的配置。这意味着要获得更多关于配置的细节,你需要参考连接的文档。在本教程中,我们使用的是Debezium连接器。
为了定义配置,我们可以向Kafka Connect API发送一个HTTP PUT请求:/connectors/{meaningful_connector_name}/config
curl --location --request PUT 'http://localhost:8083/connectors/connector-debezium-product-001/config' \
--header 'Content-Type: application/json' \
--data-raw '{
"connector.class": "io.debezium.connector.postgresql.PostgresConnector",
"database.hostname": "product_db",
"database.port": "5432",
"database.user": "postgres",
"database.password": "secret",
"database.dbname" : "product_db",
"database.server.name": "fulfillment"
}'
这也可以用POST请求来完成,但PUT请求的行为就像InsertOrUpdate ,由于这个操作是空闲的,所以我更愿意使用PUT方法。
让我们通过发送一个GET请求到以下地址,来检查到目前为止一切都已经正确地连接起来了http://localhost:8083/connectors
[ "connector-debezium-product-001"]
你可以得到关于每个连接器的更多细节:
// GET: http://localhost:8083/connectors/connector-debezium-product-001/status
{
"name": "connector-debezium-product-001",
"connector": {
"state": "RUNNING",
"worker_id": "localhost:8083"
},
"tasks": [
{
"id": 0,
"state": "RUNNING",
"worker_id": "localhost:8083"
}
],
"type": "source"
}
如果数据库中有可用的数据,那么连接器在旋转起来的时候已经开始运送数据。数据库是空的,所以它只是准备捕捉源数据库中的变化。 让我们创建一个应用程序,简单地每秒钟向我们的数据库插入数据。我在这个应用程序中使用了Kotlin。因为本教程不是关于学习Kotlin的,所以我只是快速提到我所使用的库。 即使在测试中使用有意义的数据也是一个好主意。它有助于调试,特别是当你在一个分布式系统上工作,需要随着不同的系统跟踪数据时。我使用Faker来生成相对有意义的假数据。为了连接和操作数据库,我使用了Jetbrains新开发的名为Exposed的ORM:
// build.gradle.kts
plugins {
kotlin("jvm") version "1.6.10"
}
group = "com.devmarkpro.connector"
version = "1.0-SNAPSHOT"
repositories {
mavenCentral()
}
dependencies {
implementation(kotlin("stdlib"))
implementation("org.jetbrains.exposed", "exposed-core", "0.37.3")
implementation("org.jetbrains.exposed", "exposed-dao", "0.37.3")
implementation("org.jetbrains.exposed", "exposed-jdbc", "0.37.3")
implementation("org.postgresql:postgresql:42.2.2")
implementation("io.github.serpro69:kotlin-faker:1.9.0")
}
fixedRateTimer用于在一段时期内运行一个函数。我把它设置为每1000毫秒(每秒)发射一次:
import io.github.serpro69.kfaker.faker
import org.jetbrains.exposed.dao.id.IntIdTable
import org.jetbrains.exposed.sql.*
import org.jetbrains.exposed.sql.transactions.transaction
import kotlin.concurrent.fixedRateTimer
import kotlin.random.Random
object Product : IntIdTable() {
val name = varchar("name", 500)
val price = double("price").default(0.0)
val color = varchar("color", 50).nullable()
val category = varchar("category", 50)
var quantity = integer("quantity").default(0)
val description = varchar("description", 1000).nullable()
val internalId = varchar("internalId", 50)
}
fun main() {
val db = Database.connect(
"jdbc:postgresql://127.0.0.1:5400/product_db",
driver = "org.postgresql.Driver",
user = "postgres",
password = "secret",
)
val faker = faker{}
fun toss(): Boolean = Random.nextDouble() < 0.5
fixedRateTimer("timer", false, 0L, 1000) {
transaction(db) {
addLogger(StdOutSqlLogger)
SchemaUtils.create(Product)
val productName = faker.commerce.productName()
val productId = Product.insert {
it[name] = productName
it[price] = Random.nextDouble()
it[color] = faker.color.name()
it[category] = faker.commerce.department()
it[quantity] = Random.nextInt(0, 100)
it[description] = if (toss()) faker.lorem.punctuation() else null
it[internalId] = faker.code.asin()
} get Product.id
println("product $productId : $productName inserted")
}
}
}
通过运行应用程序,Kafka Connect开始向Kafka集群推送变化。 让我们看看我们在Kafka中的数据。首先,让我们通过运行docker-compose exec broker kafka-topics --describe --zookeeper zookeeper:2181 来看看我们集群中的Kafka主题。这个命令可能会显示Kafka中的很多主题,但其中大部分都是Kafka集群和Kafka connect的内部使用。我们要找的话题与Product Table ,所以让我们过滤一下输出:
docker-compose exec broker kafka-topics --describe --zookeeper zookeeper:2181 | grep product

你的输出可能和我的有点不同,但一定有一个名称包含该产品的话题!现在让我们来消费这个话题,看看里面有什么数据。 有几种方法可以消费Kafka话题,你可以使用Kafka的GUI,你可以写一个简单的应用程序来消费这个话题,并在文件或控制台中打印收到的数据。在本教程中,我们使用kafka-console-consumer 命令行工具,通过执行docker-compose exec broker kafka-console-consumer --bootstrap-server broker:9092 --topic fulfillment.public.product 。这是一个长期运行的命令,除非发送一个SIGINT 信号,否则会一直消耗该主题。总之,你应该看到数据正在进入Kafka主题。 如果你看一下打印到控制台的数据,你会发现数据里面有几个很酷的东西。Debezium不只是发送数据,它还发送数据的模式,这是因为改变表的命令不会引起单独的消息,所以将数据与模式相匹配总是一个好主意。
在有效载荷字段中,你可以看到before 和after 属性,在我们的例子中before 是空的,因为我们只是插入数据,但如果是一个更新命令,你会得到两个版本的数据。
也有可能在运送到Kafka之前,对数据进行一些修改,或者放弃一个特定的列。也许在未来,我也会为这些情况准备一篇单独的文章。
下面是一个完整的文件例子:
{
"schema": {
"type": "struct",
"fields": [
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"default": 0,
"field": "id"
},
{
"type": "string",
"optional": false,
"field": "name"
},
{
"type": "double",
"optional": false,
"default": 0,
"field": "price"
},
{
"type": "string",
"optional": true,
"field": "color"
},
{
"type": "string",
"optional": false,
"field": "category"
},
{
"type": "int32",
"optional": false,
"default": 0,
"field": "quantity"
},
{
"type": "string",
"optional": true,
"field": "description"
},
{
"type": "string",
"optional": false,
"field": "internalId"
}
],
"optional": true,
"name": "fulfillment.public.product.Value",
"field": "before"
},
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"default": 0,
"field": "id"
},
{
"type": "string",
"optional": false,
"field": "name"
},
{
"type": "double",
"optional": false,
"default": 0,
"field": "price"
},
{
"type": "string",
"optional": true,
"field": "color"
},
{
"type": "string",
"optional": false,
"field": "category"
},
{
"type": "int32",
"optional": false,
"default": 0,
"field": "quantity"
},
{
"type": "string",
"optional": true,
"field": "description"
},
{
"type": "string",
"optional": false,
"field": "internalId"
}
],
"optional": true,
"name": "fulfillment.public.product.Value",
"field": "after"
},
{
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "version"
},
{
"type": "string",
"optional": false,
"field": "connector"
},
{
"type": "string",
"optional": false,
"field": "name"
},
{
"type": "int64",
"optional": false,
"field": "ts_ms"
},
{
"type": "string",
"optional": true,
"name": "io.debezium.data.Enum",
"version": 1,
"parameters": {
"allowed": "true,last,false"
},
"default": "false",
"field": "snapshot"
},
{
"type": "string",
"optional": false,
"field": "db"
},
{
"type": "string",
"optional": true,
"field": "sequence"
},
{
"type": "string",
"optional": false,
"field": "schema"
},
{
"type": "string",
"optional": false,
"field": "table"
},
{
"type": "int64",
"optional": true,
"field": "txId"
},
{
"type": "int64",
"optional": true,
"field": "lsn"
},
{
"type": "int64",
"optional": true,
"field": "xmin"
}
],
"optional": false,
"name": "io.debezium.connector.postgresql.Source",
"field": "source"
},
{
"type": "string",
"optional": false,
"field": "op"
},
{
"type": "int64",
"optional": true,
"field": "ts_ms"
},
{
"type": "struct",
"fields": [
{
"type": "string",
"optional": false,
"field": "id"
},
{
"type": "int64",
"optional": false,
"field": "total_order"
},
{
"type": "int64",
"optional": false,
"field": "data_collection_order"
}
],
"optional": true,
"field": "transaction"
}
],
"optional": false,
"name": "fulfillment.public.product.Envelope"
},
"payload": {
"before": null,
"after": {
"id": 132,
"name": "Incredible Iron Pants",
"price": 0.61987811851418,
"color": "violet",
"category": "Tools",
"quantity": 41,
"description": "?",
"internalId": "B0009PC1XA"
},
"source": {
"version": "1.7.1.Final",
"connector": "postgresql",
"name": "fulfillment",
"ts_ms": 1641025283281,
"snapshot": "false",
"db": "product_db",
"sequence": "[\"23982504\",\"23982504\"]",
"schema": "public",
"table": "product",
"txId": 622,
"lsn": 23982504,
"xmin": null
},
"op": "c",
"ts_ms": 1641025283552,
"transaction": null
}
}
