

这是我参与「第四届青训营」笔记创作活动的的第10天
01.列存vs.行存
数据格式层概述
- 计算层:各种计算引擎
- 存储层:承载数据的持久化存储
- 数据格式层:定义了存储层文件内部的组织格式,计算引擎通过格式层的支持来读写文件
分层视角下的数据形态
- 存储层: File,Blocks
- 格式层: File 内部的数据布局(Layout + Schema)
- 计算引擎:Rows + Columns
两种数据查询分析场景: OLTP vs. OLAP
OLTP:行式存储格式(行存)
-
每行的数据在文件上是连续存储的
-
读取整行数据效率高,单次10顺序读即可
-
典型系统
- 关系型数据库: MySQL, Oracle
- Key-Value数据库
OLAP:列式存储格式(列存)
-
每列的数据在文件上是连续存储的
-
读取整列的效率较高
-
同列的数据类型一致, 压缩编码的效率更好
-
典型系统
- 大数据分析系统: SQL-on Hadoop,数据湖分析
- 数据仓库: ClickHouse, Greenplum, 阿里云MaxCompute
02.Parquet原理详解
- parquet.apache.org
- 大数据分析领域使用最广的列存格式
- Spark 推荐存储格式
Parquet in Action
DDL
Spark
Parquet Vs. Text Format
Dremel数据模型
- Protocol Buffer定义
- 支持可选和重复字段
- 支持嵌套类型
Continued
- 嵌套类型只保存叶子节点数据
- 问题:由于列可能是Optional和Repeated,如何把列内的数据对应到逻辑视图里的Record呢?
数据布局
-
RowGroup:每一个行组包含定数量 或者固定大小的行的集合
-
ColumnChunk: RowGroup中按照列切分成多个ColumnChunk
-
Page: ColumnChunk内部继续切分成Page,一般建议8KB大小。压缩和编码的基本单元
- 根据保存的数据类型分为: Data,Page, Dictionary Page, Index Page
-
Footer保存文件的元信息
-
Schema
-
Config
-
Metadata
-
RowGroup Meta
- Column Meta
-
-
编码Encoding
-
Plain直接存储原始数据
-
Run Length Encoding (RLE): 适用于列基数不大,
-
重复值较多的场景,例如: Boolean、 枚举、固定的选项等
- Bit-Pack Encoding:配合RLE编码使用,让整形数字存储的更加紧凑
-
字典编码Dictionary Encoding:适用于列基数不大的场景,构造字典表,写入到Dictionary Page;把数据用字典Index替换,然后用RLE编码
- 默认场景下parquet-mr会自动根据数据特征选择
- 业务自定义: org.apache.parquet.column.values factory.ValuesWriterFactory
压缩Compression
- Page完成Encoding以后,进行压缩
- 支持多种压缩算法
- snappy:压缩速度快,压缩比不高,适用于热数据
- gzip:压缩速度慢,压缩比高,适于冷数据
- zstd:新引入的压缩算法,压缩比和gzip差不多,而且压缩速度比肩Snappy
- 建议选择snappy或者zstd,根据业务数据类型充分测试压缩效果,以及对查询性能的影响
索引 Index
-
和传统的数据库相比,索引支持非常简陋
-
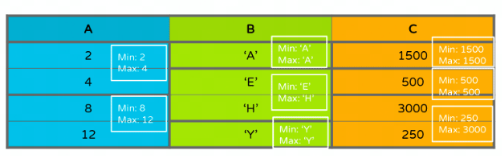
Min-Max Index:记录Page内部Column的min value和max value
-
Column Index:
- Footer里的Column Metadata包含ColumnChunk的全部Page的Minax Value
-
Offset Index:记录Page在文件中的Offset和Page的Row Range
Bloom Filter
- parquet.bloom.filter.enabled
- 对于列基数比较大的场景,或者非排序列的过滤,Min-Max Index很难发挥作用
- 引入Bloom Filter 加速过滤匹配判定
- 每个ColumnChunk的头部保存Bloom Filter 数据
- Footer记录Bloom Filter的page offset
排序Ordering
-
类似于聚集索引的概念
-
排序帮助更好的过滤掉无关的RowGroup或者Page
- 对于少量数据Seek很有帮助
-
Parquet Format支持SortingColumns
-
Parquet Library目前没有支持
-
依赖业务侧根据查询特征去保证顺序
过滤下推 Predicate PushDown
- parquet-mr库实现,实现高效的过滤机制
- 引擎侧传入Filter Expression
- parquet-mr转换成具体Column的条件匹配
- 查询Footer里的Column Index, 定位到具体的行号
- 返回有效的数据给引擎侧
Spark集成-向量化读
- ParquetFileFormat类
- 向量化读开关:spark.sql.parquet.enableVectorizedReader
- 向量化读是主流大数据分析引|擎的标准实践,可以极大的提升查询性能
- Spark以Batch的方式从Parquet读取数据,下推的逻辑也会适配Batch的方式
深入Dremel数据模型- Repetition Level
- Repetition Level:该字段在Field Path上第几个重复字段上出现
- 0:标识新的Record
- Name.Language.Code为例,Name是第1个重复字段,Language 是第2个重复字段
深入Dremel数据模型- Definition Level
- Definition Level: 用来记录在fieldpath中,有多少个字段是可以不存在(optional/repeated)而实际出现的
- Name.Language.Code为例,Name和Language都是可以不存在的
- 第一个NULL字段,D是1,说明Name是存在的,但是Language是不存在的,保留原有的信息
Re-Assembly
- 根据全部或者部分列数据,重新构造Record
- 构造FSM状态机
- 根据同一个Column下一个记录的RepetionLevel决定继续读的列
03.ORC详解和对比
- orc.apache.org
- 大数据分析领域使用最广的列存格式之一
- 出自于Hive项目
数据模型
-
ORC会给包括根节点在内的中间节点都创建一个Column
- 左图中,会创建8个Column
-
嵌套类型或者集合类型支持和Parquet差别较大
-
optional和repeated字段依赖父节点记录额信息来重新Assembly数据
数据布局
- 类似Parquet
- Rooter + Stripe + Column + Page (Row Group)结构
- Encoding / Compression / Index支持上和Parquet几乎一致
ACID特性简介
- 支持Hive Transactions实现,目前只有Hive本身集成
- 类似Delta Lake / Hudi / lceberg
- 基于Base + Delta + Compaction的设计
AliORC
- ORC在阿里云计算平台被广泛应用,主流产品MaxCompute +交互式分析Hologres的
- 最新版本都支持ORC格式
- AliORC是对ORC的深度定制版
索引增强
- 支持Clusterd Index,更快的主键查找
- 支持Bitmap Index,更快的过滤
- Roaring Bitmap
小列聚合
小列聚合,减少小IO 重排Chunk
异步预取
- 异步预取数据
- 计算逻辑和数据读取并行化
Parquet vs. ORC对比
- 从原理层面,最大的差别就是对于NestedType和复杂类型处理上
- Parquet的算法上要复杂很多,带来的CPU的开销比ORC要略大
- ORC的算法上相对简单,但是要读取更多的数据
- 因此,这个差异的对业务效果的影响,很难做一个定性的判定,更多的时候还是要取决于实际的业务场景
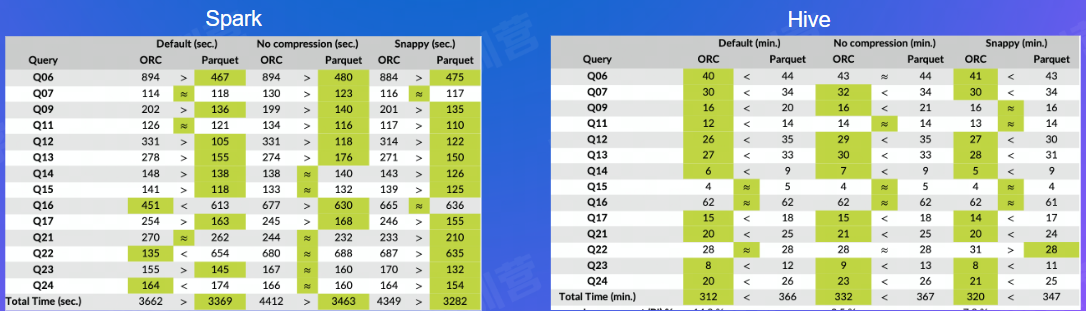
Parquet vs. ORC对比-性能
- 场景: Full Table Scan 平台:推测Hive 时间: 2016
- 左边:简单Schema 右边:复杂Schema
- Parquet 在复杂Schema场景下的算法开销影响较大
Parquet vs. ORC对比-选择
- 最新的版本来看,Parquet和ORC在性能上没有非常明显的差距和短板
- 性能上很多情况下依赖于数据集和测试环境,不能迷信Benchmark结果
- 根据实际业务做充分的测试调优
- Spark 生态下Parquet比较普遍
- Hive 生态下ORC有原生支持
整体上,Spark比Hive更加有优势,所以大部分情况下,Parquet 可能是个更好的选择。
- V支持Hive Transactions实现,目前只有Hive本身集成
- V类似Delta Lake / Hudi / lceberg
- V基于Base + Delta + Compaction的设计
04.列存演进
数仓中的列存
- ClickHouse的MergeTree引擎也是基于列存构建的
- 默认情况下列按照Column拆分的
- 支持更加丰富的索引
- 湖仓一体的大趋势
存储侧下推
-
更多的下推工作下沉到存储服务侧
-
越接近数据,下推过滤的效率越高
-
例如AWS S3 Select功能
-
挑战:
- 存储侧感知Schema
- 计算生态的兼容和集成
Column Family支持
- 背景: Hudi数据湖场景下,支持部分列的快速更新
- 在Parquet格式里引入Column Family概念,把需要更新的列拆成独立的Column Family
- 深度改造Hudi的Update和Query逻辑,根据Column Family选择覆盖对应的Column Family
- Update操作实际效果有10+倍的提升
