

JAVA
一·、自动装箱与拆箱
装箱:将基本类型转化为对应的包装类型
【例(手动装箱)】:Integer i = new Integer(12);
拆箱:将包装类型转化为对应的基本类型
【例(手动拆箱)】:int j = i.intValue();
应用:Java采用自动装箱与自动拆箱机制,节省了数值内存开销和创建对象的开销。这个机制由编译器根据语法,决定装箱和拆箱,自行完成。
注意:【八种基本数据类型和包装类型】:byte i Byte
short i Short
char i character
int i Integer
long i Long
float i Float
double i Double
二、范型及范型擦除:
范型:即,参数化类型。创建集合时就指定集合元素类型,只能保存该类型的元素,避免强制类型转换。
类型擦除:范型信息只存在于代码编译阶段,在进入jvm之前范型信息会被擦除掉。
【过程】: 1.将所有的泛型参数用其最左边界(最顶级的父类型)类型替换。
2.移除所有的类型参数
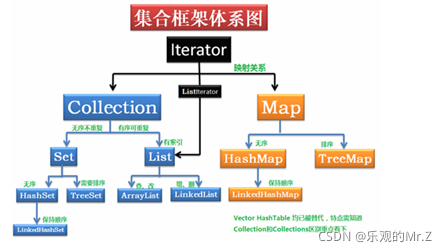
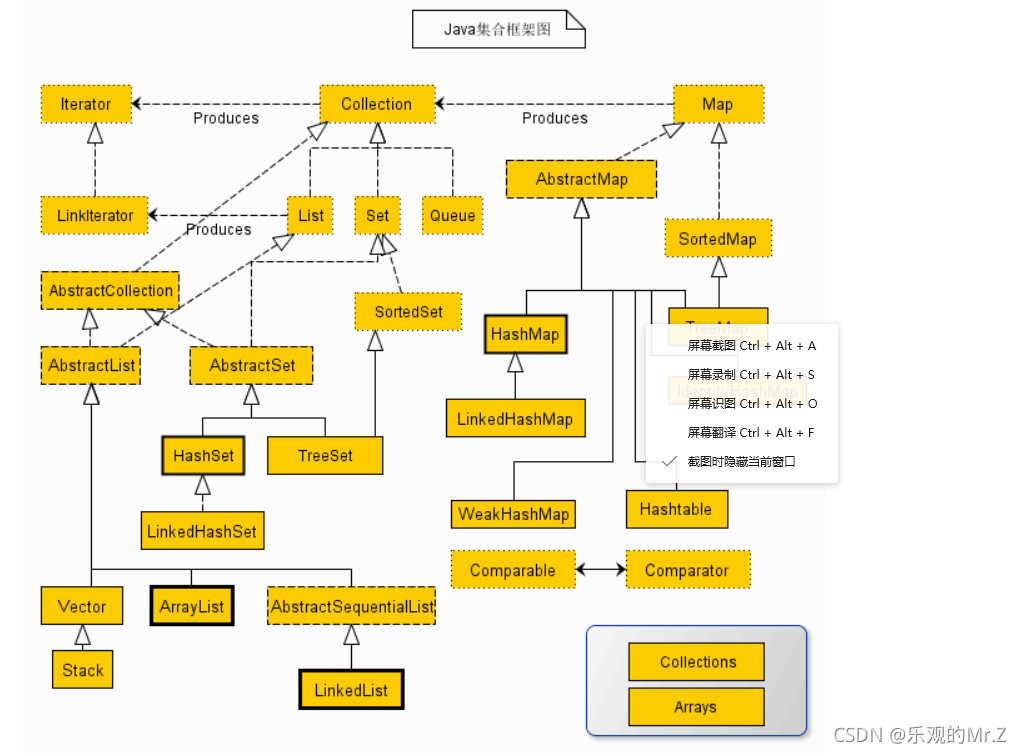
三、Java集合类关系图:
1.List和Set继承自Collection接口
2.List有序且允许元素重复,ArrayList、LinkList、Vector为主要的三个实现类
3.Set无序且不允许元素重复,HashSet和TreeSet为主要的两个实现类
4.Map也属于集合系统,但是跟Collection接口无关。Map是键值对的映射集合 ,键key不能重复,但是值value可以重复。HashMap、TreeMap和HashTable为主要的三个实现类
四、HashTable和HashMap的实现原理:
https://www.iteye.com/blog/zhangshixi-672697
https://www.cnblogs.com/skywang12345/p/3310887.html
五、HashMap和Hashtable的区别:
1.HashTable方法前面都有synchronized同步,所以是线程安全的。而HashMap未经同步,所以是非线程安全的
2.HashTable不允许null(键和值都不可以为null),而HashMap允许null(键和值都可以为null)
3.HashTable使用Enumeration(枚举)进行遍历,而HashMap使用Iterator(迭代器)进行遍历
4.HashTable中hash数组默认大小是11,增长方式old*2+1,而HashMap中数组默认大小16,并且是2的指数
5、哈希值使用不同,HashTable直接使用对象的HashCode,而HashMap重新计算而且用于代替求模。
六、ConcurrentHashMap实现原理:
https://blog.csdn.net/weixin_43185598/article/details/87938882
七、ArrayList和LinkList:
区别:
ArrayList底层使用数组实现,可以认为它是一个可变大小的数组,随着元素的增多,规模动态增多。
LinkList底层使用双向链表实现,所以增删速度比较快,但是查询修改比较慢。
使用场景:
ArrayList适合检索和末尾插入或删除元素【体现数组特性】
LinkList适合从中间插入或者删除元素【体现链表特性】
八、Collection和Collections:
Java.util.Collection是一个集合接口,提供了集合对象进行操作的通用接口方法。
Java.util.Collections是一个包装类,包含有关集合操作的静态方法(集合类的工具类),且不能被实例化【例:Collections.sort();】。
九、Java十大排序:【下面博文中有动态效果图,一目了然】
【推荐博文】blog.csdn.net/u012786993/…
1.冒泡排序:
比较相邻元素,将大元素放到后面,从开始第一组元素到最后一组元素结束,最终最后位置的元素就是最大值MAX,时间复杂度:O(n²)。
2.选择排序:
每次遍历前,假设第一个索引处的元素是最小值,交换第一个索引处和最小值所在的索引处的值,最终得到从小到大排列,时间复杂度:O(n²)。
3.插入排序:
将所有元素分为已排序和未排序两组,拿未排序组中的第一个元素,向已排序组中插入,倒序遍历已排序数组元素,直到找到一个元素小于等于待插入元素时,把待插入元素放到这个位置,其余元素后移一位,时间复杂度:O(n²)。
4.希尔排序(shell):
选定一个增长量h=round(n/2),按增长量作为分组依据,对数据进行分组。对每一小组内部再进行插入排序。不断循环此步骤,直到h=1。
5.归并排序:关键点体现在归并操作上,采用分而治之的思想
6.快速排序:详细阐述见,推荐博文
7.堆排序:详细阐述见,推荐博文
8.计数排序:详细阐述见,推荐博文
9.桶排序:详细阐述见,推荐博文
10.基数排序:详细阐述见,推荐博文
