

如何为数据湖构建Spark脉络图
当数据管道破裂时,数据工程师需要立即了解破裂发生的位置和受到的影响。数据停机的代价很高。
如果没有数据线--即资产如何连接和数据在其生命周期中如何移动的地图--数据工程师可能会蒙着眼睛进行事件分流和根本原因分析。
Monte Carlo的数据可观察性平台为基于SQL的转换做了很好的表线映射工作,但一些最流行的、基于Spark的系统对我们和整个行业来说仍然是一个盲点。
这就是我们如何着手为这一挑战设计解决方案,并将Spark整合到我们的世系功能的故事。
我们如何自动化SQL血统
开发SQL的数据线是一个与开发Spark线有很大不同的过程。
为了使用SQL检索数据,用户会编写并执行一个查询,然后将其存储在日志中。这些SQL查询包含了所有必要的面包屑,以追踪特定表的哪些列或字段正在向下游的其他表提供数据。
例如,我们可以看一下这个SQL查询,它将显示一个棒球队的球员的击球结果......
SELECT player.first_name, player.last_name, bat.date, bat_outcome.outcome_text
FROM player
INNER JOIN bat ON bat.player_id = player.id
INNER JOIN bat_outcome ON bat.bat_outcome_id = bat_outcome.id
...我们可以理解上述球员、球棒和球棒结果表之间的联系。
你可以看到从SELECT语句产生的 "击球结果 "表中的下游字段到字段的关系,以及非SELECT语句中的表到字段的依赖关系。
来自数据仓库/湖泊和BI工具的元数据可以被用来映射表和仪表盘之间的依赖关系。
手动解析所有这些来开发端到端的脉络是可能的,但它是乏味的。
当你的环境继续摄入更多的数据,你继续增加额外的解决方案时,它实际上就已经过时了。
我们实现自动化的方法是使用一个自制的数据收集器,从客户的数据仓库或湖泊中抓取他们的SQL日志,将数据流向我们数据管道的不同组件。我们利用开源的ANTLR解析器,在一个基于Java的lambda函数中为各种SQL方言进行了大量的定制,以梳理查询日志并生成线状数据。
我们的字段级SQL世系解决方案的后端架构看起来像这样:
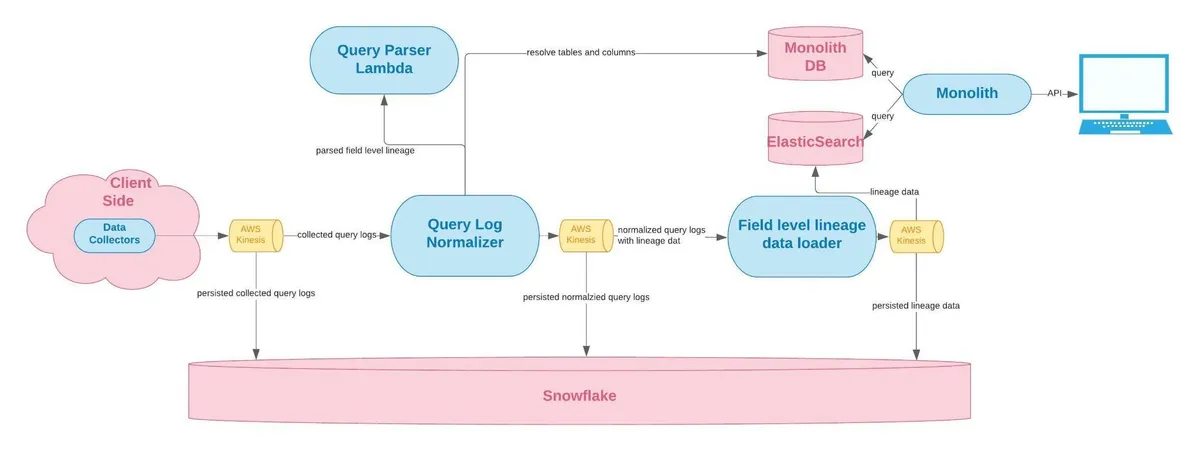 图片由Monte Carlo提供。
图片由Monte Carlo提供。
容易吗?不。与Spark lineage相比,容易吗?绝对的。
我们如何解决端到端的Spark世系问题
Apache Spark的工作方式并不完全一样。Spark支持几种不同的编程接口,可以创建作业,如Scala、Python或R。
无论使用哪种编程接口,它都会被解释并编译成Spark命令。在幕后,没有所谓的简明查询,也没有这些查询的日志。
以下是来自Python、Scala和R的Databricks笔记本的例子,它们都做了同样的事情:将CSV文件加载到Spark DataFrame中。
Python
%python
data = spark.read.format('csv') \
.option('header', 'true') \
.option('inferSchema', 'true') \
.load('/data/input.csv')
Scala
%scala
val data = spark.read.format("csv")
.option("header", "true")
.option("inferSchema", "true")
.load("/cfritz/input.csv")
R
%r
data <- read.df("/data/input.csv",
source = "csv",
header="true",
inferSchema = "true")
在Spark解释程序代码和编译命令之后,它创建了一个执行图(DAG或有向无环图),包括所有的顺序步骤,从源头读取数据,执行一系列的转换,并将其写入输出位置。
这使得DAG相当于一个SQL执行计划。与它的整合是Spark产品线的圣杯,因为它包含了数据如何在数据湖中移动以及一切如何连接所需的所有信息。
Spark有一个叫做QueryExecutionListeners的内部框架,你可以在Spark中配置它来监听命令被执行的事件,然后将该命令传递给监听器。
package za.co.absa.spline.harvester.listener
import org.apache.spark.sql.SparkSessionimport org.apache.spark.sql.execution.QueryExecutionimport org.apache.spark.sql.util.QueryExecutionListenerimport za.co.absa.spline.harvester.SparkLineageInitializer
class SplineQueryExecutionListener extends QueryExecutionListener {
private val maybeListener: Option[QueryExecutionListener] = {
val sparkSession = SparkSession.getActiveSession
.orElse(SparkSession.getDefaultSession)
.getOrElse(throw new IllegalStateException(“Session is unexpectedly missing. Spline cannot be initialized.”))
new SparkLineageInitializer(sparkSession).createListener(isCodelessInit = true)
}
override def onSuccess(funcName: String, qe: QueryExecution, durationNs: Long): Unit = {
maybeListener.foreach(_.onSuccess(funcName, qe, durationNs))
}
override def onFailure(funcName: String, qe: QueryExecution, exception: Exception): Unit = {
maybeListener.foreach(_.onFailure(funcName, qe, exception))
}
}
我们决定利用Spline 这一开源技术,而不是从头开始建立一系列的监听器。
聪明的开发者已经投入了数年时间来构建一个Spark代理,以监听这些事件,捕获行文元数据,并将其转化为图形格式,然后我们可以通过REST API接收这些数据(也有其他接收这些数据的选项)。
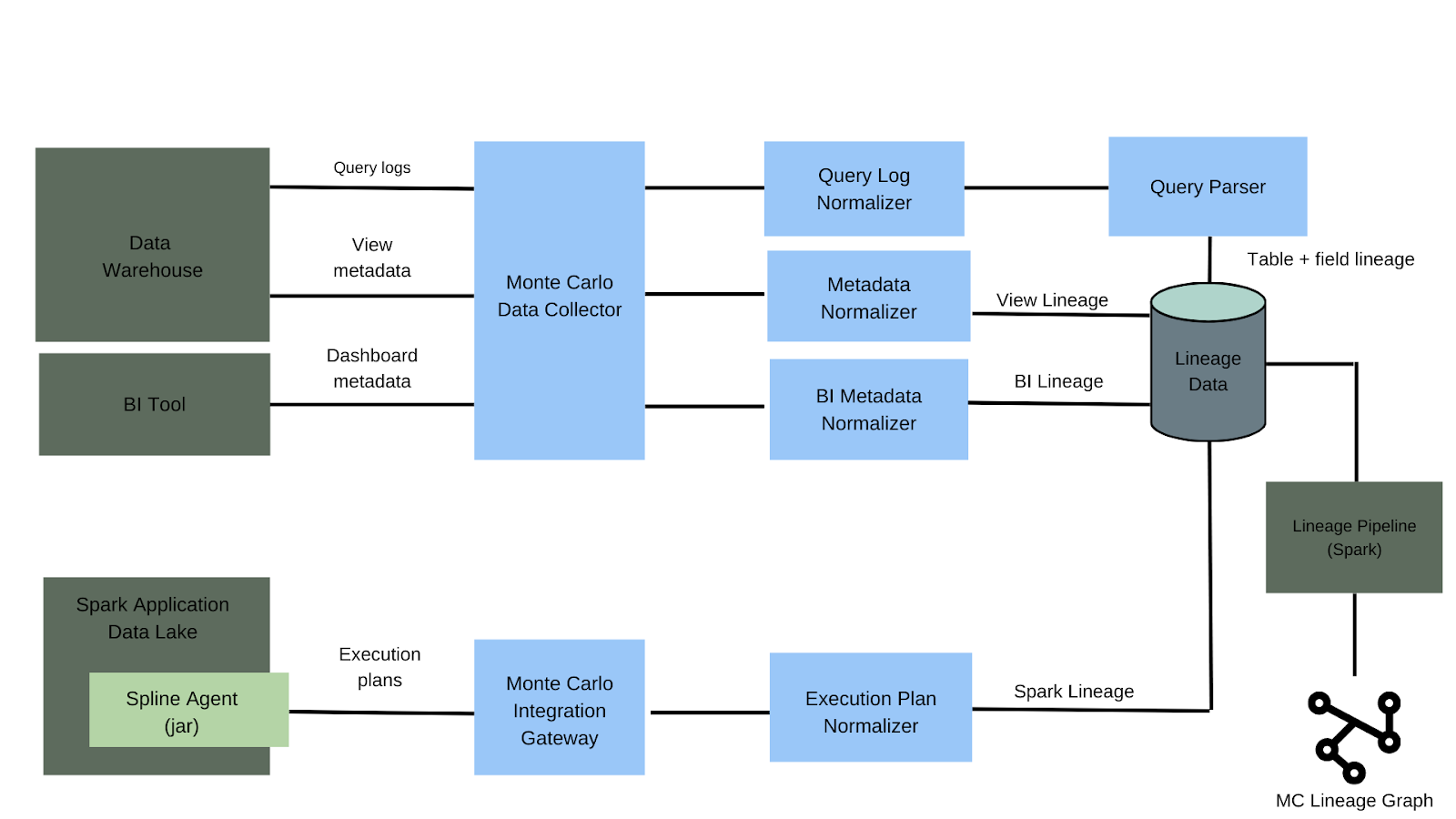 蒙特卡洛如何收集信息来构建我们的线代图。Spark线程是详细描述数据在其生命周期中的旅程的元数据,包括来源、创建者、转换和相关数据集。
蒙特卡洛如何收集信息来构建我们的线代图。Spark线程是详细描述数据在其生命周期中的旅程的元数据,包括来源、创建者、转换和相关数据集。
一旦我们有了执行计划的表示,我们就把它送到集成网关,然后由规范化器把它转换成Monte Carlo内部的行进事件表示。
从那里,它与其他来源的线程和元数据集成,为每个客户提供一个单一的端到端视图。
这是一个非常优雅的解决方案....,这就是为什么它不能工作。
Spark世系的挑战
是什么让Spark从线性角度变得困难,是什么让它成为处理大量非结构化数据的伟大框架。也就是说,它的可扩展性很强。
你可以在AWS Glue、EMR和Databricks等解决方案中运行Spark作业。事实上,仅在Databricks中就有多种方式可以运行Spark作业。
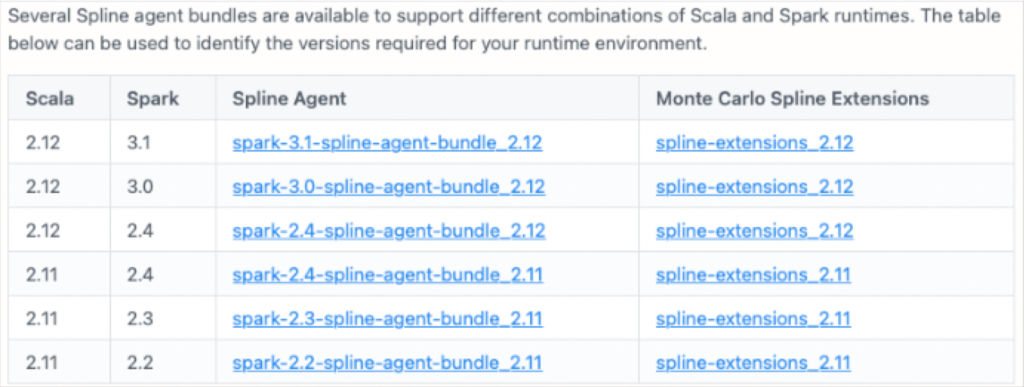
配置我们的Spark血统解决方案--特别是如何将JAR文件添加到Spark的运行时classpath--将取决于我们的客户如何在这些解决方案中运行他们的Spark作业以及这些解决方案所利用的Scala和Spark版本的组合。
在Monte Carlo,我们非常强调易用性和时间价值。当你发现自己在文件草稿中插入这样的表格时,这可能是一个重新评估解决方案的信号。
 第二个挑战是,像SQL语句一样,Spark命令的词汇量在不断扩大。但是,由于它是一个比SQL更新的框架,它的增长速度略快。
第二个挑战是,像SQL语句一样,Spark命令的词汇量在不断扩大。但是,由于它是一个比SQL更新的框架,它的增长速度略快。
每当一个新的命令被引入,就必须编写代码来从该命令中提取行元数据。因此,Spline的解析能力中存在着尚未支持的命令的空白。
不幸的是,许多这些差距需要为我们客户的用例而填补。例如,一家大型生物技术公司需要覆盖它利用Spark MERGE命令的情况,就像SQL语句和表格一样,通过插入传入数据框中的新内容和更新它发现的任何现有记录,将两个数据框结合在一起。
例如,以我们之前的简单棒球表为例,新的Spark MERGE命令可以用来添加新的安打,用修正后的数据更新以前存在的安打,或者甚至删除那些我们不再关心的旧安打。
MERGE into bat
using bat_stage
on bat.player_id = bat_stage.player_id
and bat.opponent_id = bat_stage.opponent_id
and bat.date = bat_stage.date
and bat.at_bat_number = bat_stage.at_bat_number
when matched then
update set
bat.bat_outcome_id = bat_stage.bat_outcome_id
when not matched then
insert (
player_id,
opponent_id,
date,
at_bat_number,
bat_outcome_id
) values (
bat_stage.player_id,
bat_stage.opponent_id,
bat_stage.date,
bat_stage.at_bat_number,
bat_stage.bat_outcome_id
)
这是一个相对较新的命令,Spline并不支持它。此外,Databricks已经开发了他们自己的MERGE语句的实现,但公众对其并不了解。
这些当然是很大的挑战,但他们也有解决方案。
我们可以确保有更多的客户牵着Spark血统配置的手。我们可以雇佣和部署一支Scala忍者军队,为Spline代理的新命令提供支持。我们甚至可以厚着脸皮,逆向工程如何从Databricks的MERGE命令实现中推导出世系。
一个好的工程师可以为困难的问题建立解决方案。一个伟大的工程师会退一步问:"这些汁液值得榨取吗?是否有更好的方法可以做到这一点?"
很多时候,购买或整合现成的解决方案不仅更省时,而且可以防止你的团队累积技术债务。因此,我们选择了另一个方向。
