

js 的数据类型
基本类型
- Boolean
- String
- Null
- BigInt
- Number
- Symbol
- Undefined
引用类型
-
Object 对象
- 数组 函数 叫做 对象 类型
ES 和 js 区别
JS
- 包括了 es 和 webApi
- 两个组成了 js
ES
- 语法规范
- 标准库
webAPI
- DOM
- BOM
[] + {} 和 {} + []
案例
console.log([] + {}) // object Object
console.log({} + []) // 0
结论
- 引用类型 作运算的时候 都会先调用他的 valueOf() 方法
- 如果返回的还是一个引用类型 在调用他的 toString() 方法
- 如果返回还是引用类型 就进行运算
- 为什 上面 {} + [] = 0 因为 浏览器会把 {} 解析成 代码块 [] 解析成 +'' 所以变成了 0 如果在 node中 还是 object Object
函数的执行上下文
案例
function methods (a, b, c) {
console.log(a, b, c) // 1 2 [Function: c]
var a = 'a'
var b = function b () { };
(function a () { }); // 不是函数 只是表达式
(function b () { });
function c () {
}
console.log(a, b, c)// a [Function: b] [Function: c]
}
methods(1, 2, 3)
结论
- 在调用函数 运行函数之前 会先对 函数进行填充
- 第一步 确认形参 解析参数 如果传递了 先把形参的值确认下来
- 第二步 确认函数声明 把函数 提取到最上面 如果有同名的 声明 会覆盖
- 第三步 确认声明变量 提取到最上面 如果有同名的声明 会忽略
赋值运算的细节
案例
var a = {n:1}
var b = a
a.x = a
a = {n:2}
console.log(a.x) undefined
console.log(b.x) {n:2}
b
{
n: 1
x: {n:2}
}
a
{
n: 2
}
赋值的步骤
- 找到变量 的内存地址 准备赋值
- 运算右侧代码 得到要赋值的值
- 将右侧运算的结果放到之前的地址中
- 返回整个表达式的结果为 右侧表达式 运算的值
parseInt() 参数
const nums = ['1','2','3']
const newnums = nums.map(parseInt)
// 1 NAN NAN
结论
- parseInt 第二个参数是 进制转换
- 非 0 的无效进制 都会转换成 NaN 有效进制是 2-36
- 3 为什么是 NaN 因为 2进制中 只有 0 1 没有 3 所以也是 NaN
script async defer 区别
正常
- 浏览器 碰到 script 标签 就会暂停解析 dom 元素 去加载 js 解析 js 执行js
- 等 js 执行完毕 才会继续解析 dom
defer
- 浏览器 碰到 script 标签 不会暂停解析 dom 元素
- 同时会去加载 js 文件
- 等 dom 全部解析完毕 即将 触发 DOMContentLoaded 事件等时候
- 才会去 解析 js 执行js
async
- 浏览器 碰到 script 标签 不会暂停解析 dom 元素
- 同时会去加载 js 文件
- 当 加载到 js 文件 暂停 解析 dom 开始解析 js 执行 js
- 等 js 解析 完毕 执行完毕 继续 加载 dom
Javascript 中的数字在计算机中占 多少个 Byte
8byte
结论
- 8个 2进制数字 标识一个字节
- js 使用 双精度浮点数
- 双精度 占 64 位
- 64 / 8 所以 得到 8 byte
短路规则
案例
console.log(2 && 4) // 4
console.log(2 || 4) // 2
短路运算的步骤
- 依次判定 布尔判定
- 返回结果: 能确认结果的最后一个值
- && 一假则假
- || 一真则真
画一个边框宽度为0.5px的正方形叭
解决方法
1.直接写0.5px,不兼容。
2.transform的scale。
3.linear-gradient,渐变。
4.SVG。
5.box-shadow。
6.meta中的viewport。
实现
使用伪元素给box2添加边框。注意这里要添加transform-origin: left top;不然盒子会偏移中心。
.box1 {
background: none;
margin-top: 10px;
margin-left: 200px;
height: 100px;
width: 100px;
border: 0.5px solid #000;
}
.box2 {
position: relative;
margin: 10px 0 0 200px;
border: none;
background: none;
height: 100px;
width: 100px;
}
.box2::after {
content: '';
position: absolute;
border: 1px solid #000;
top: 0;
left: 0;
box-sizing: border-box;
width: 200%;
height: 200%;
transform: scale(0.5);
transform-origin: left top;
}
<div class="box"></div>
<div class="box1"></div>
<div class='box2'></div>
这是在pc端的效果,是不是感觉直接设置为0.5px,反而会更细呢。但是我们再看看移动端的情况。
在移动端只有缩放0.5的方案才符合效果。
如何让localStorage支持过期时间设置?
问题描述
在实际的应用场景中, 我们往往需要让 localStorage 设置的某个 「key」 能在指定时间内自动失效, 所以基于这种场景, 我们如何去解决呢?
1. 初级解法
缺点
「维护成本极高, 且不利于工程化复用」。
实现
localStorage.setItem('dooring', '1.0.0')
// 设置一小时的有效期
const expire = 1000 * 60 * 60;
setTimeout(() => {
localStorage.setItem('dooring', '')
}, expire)
2. 中级解法
- 用**「localStorage」**存一份{key(键): expire(过期时间)}的映射表
- 重写**「localStorage API」**, 对方法进行二次封装
缺点
- 对 store 操作时需要维护2份数据, 并且占用缓存空间
- 如果 EXPIRE_MAP 误删除将会导致所有过期时间失效
- 对操作过程缺少更灵活的控制(比如操作状态, 操作回调等)
实现
const store = {
// 存储过期时间映射
setExpireMap: (key, expire) => {
const expireMap = localStorage.getItem('EXPIRE_MAP') || "{}"
localStorage.setItem(
'EXPIRE_MAP',
JSON.stringify({
...JSON.parse(expireMap),
key: expire
}))
},
setItem: (key, value, expire) => {
store.setExpireMap(key, expire)
localStorage.setItem(key, value)
},
getItem: (key) => {
// 在取值之前先判断是否过期
const expireMap = JSON.parse(
localStorage.getItem('EXPIRE_MAP') || "{}"
)
if(expireMap[key] && expireMap[key] < Date.now()) {
return localStorage.getItem(key)
}else {
localStorage.removeItem(key)
return null
}
}
// ...
}
3. 高级解法
- 将过期时间存到 key 中, 如 dooring|6000, 每次取值时通过分隔符“|”来将 key 和 expire 取出, 进行判断
- 将过期时间存到 value 中, 如 1.0.0|6000, 剩下的同1
实现
const store = {
preId: 'xi-',
timeSign: '|-door-|',
status: {
SUCCESS: 0,
FAILURE: 1,
OVERFLOW: 2,
TIMEOUT: 3,
},
storage: localStorage || window.localStorage,
getKey: function (key: string) {
return this.preId + key;
},
set: function (
key: string,
value: string | number,
time?: Date & number,
cb?: (status: number, key: string, value: string | number) => void,
) {
let _status = this.status.SUCCESS,
_key = this.getKey(key),
_time;
// 设置失效时间,未设置时间默认为一个月
try {
_time = time
? new Date(time).getTime() || time.getTime()
: new Date().getTime() + 1000 * 60 * 60 * 24 * 31;
} catch (e) {
_time = new Date().getTime() + 1000 * 60 * 60 * 24 * 31;
}
try {
this.storage.setItem(_key, _time + this.timeSign + value);
} catch (e) {
_status = this.status.OVERFLOW;
}
cb && cb.call(this, _status, _key, value);
},
get: function (
key: string,
cb?: (status: number, value: string | number | null) => void,
) {
let status = this.status.SUCCESS,
_key = this.getKey(key),
value = null,
timeSignLen = this.timeSign.length,
that = this,
index,
time,
result;
try {
value = that.storage.getItem(_key);
} catch (e) {
result = {
status: that.status.FAILURE,
value: null,
};
cb && cb.call(this, result.status, result.value);
return result;
}
if (value) {
index = value.indexOf(that.timeSign);
time = +value.slice(0, index);
if (time > new Date().getTime() || time == 0) {
value = value.slice(index + timeSignLen);
} else {
(value = null), (status = that.status.TIMEOUT);
that.remove(_key);
}
} else {
status = that.status.FAILURE;
}
result = {
status: status,
value: value,
};
cb && cb.call(this, result.status, result.value);
return result;
},
// ...
};
export default store;
4. 骨灰级解法
骨灰级解法是直接使用 xijs 这个 javascript 工具库
实现
// 先安装 yarn add xijs
import { store } from 'xijs';
// 设置带有过期时间的key
store.set('name', 'dooring', Date.now() + 1000);
console.log(store.get('name'));
setTimeout(() => {
console.log(store.get('name'));
}, 1000);
// 设置成功后的回调
store.set('dooring', 'xuxiaoxi', Date.now() + 1000, (status, key, value) => {
console.log('success');
});
Virtual DOM的优势在哪里
- 操作真实DOM 性能会差一点
- 虚拟DOM不会立马进行排版与重绘操作
- 虚拟DOM进行频繁修改,然后一次性比较并修改真实DOM中需要改的部分,最后在真实DOM中进行排版与重绘,减少过多DOM节点排版与重绘损耗
- 虚拟DOM有效降低大面积真实DOM的重绘与排版,因为最终与真实DOM比较差异,可以只渲染局部
- 当热最大的一个优点 解决了 跨平台的能力
简易版 vdom 的diff 算法的简易实现
vdom转化为真实dom
const createElement = (vnode) => {
let tag = vnode.tag;
let attrs = vnode.attrs || {};
let children = vnode.children || [];
if(!tag) {
return null;
}
//创建元素
let elem = document.createElement(tag);
//属性
let attrName;
for (attrName in attrs) {
if(attrs.hasOwnProperty(attrName)) {
elem.setAttribute(attrName, attrs[attrName]);
}
}
//子元素
children.forEach(childVnode => {
//给elem添加子元素
elem.appendChild(createElement(childVnode));
})
//返回真实的dom元素
return elem;
}
简易diff算法做更新操作
function updateChildren(vnode, newVnode) {
let children = vnode.children || [];
let newChildren = newVnode.children || [];
children.forEach((childVnode, index) => {
let newChildVNode = newChildren[index];
if(childVnode.tag === newChildVNode.tag) {
//深层次对比, 递归过程
updateChildren(childVnode, newChildVNode);
} else {
//替换
replaceNode(childVnode, newChildVNode);
}
})
}
JS中的数据类型检测方案
typeof
console.log(typeof 1); // number
console.log(typeof true); // boolean
console.log(typeof 'mc'); // string
console.log(typeof Symbol) // function
console.log(typeof function(){}); // function
console.log(typeof console.log()); // function
console.log(typeof []); // object
console.log(typeof {}); // object
console.log(typeof null); // object
console.log(typeof undefined); // undefined
优点
能够快速区分基本数据类型
缺点
不能将Object、Array和Null区分,都返回object
instanceof
console.log(1 instanceof Number); // false
console.log(true instanceof Boolean); // false
console.log('str' instanceof String); // false
console.log([] instanceof Array); // true
console.log(function(){} instanceof Function); // true
console.log({} instanceof Object); // true
优点
能够区分Array、Object和Function,适合用于判断自定义的类实例对象
缺点
Number,Boolean,String基本数据类型不能判断
Object.prototype.toString.call()
var toString = Object.prototype.toString;
console.log(toString.call(1)); //[object Number]
console.log(toString.call(true)); //[object Boolean]
console.log(toString.call('mc')); //[object String]
console.log(toString.call([])); //[object Array]
console.log(toString.call({})); //[object Object]
console.log(toString.call(function(){})); //[object Function]
console.log(toString.call(undefined)); //[object Undefined]
console.log(toString.call(null)); //[object Null]
优点
精准判断数据类型
缺点
写法繁琐不容易记,推荐进行封装后使用
数组和链表区别
不同
- 链表是链式的存储结构;数组是顺序的存储结构。
- 链表通过指针来连接元素与元素,数组则是把所有元素按次序依次存储。
- 链表的插入删除元素相对数组较为简单,不需要移动元素,且较为容易实现长度扩充,但是寻找某个元素较为困难;
- 数组寻找某个元素较为简单,但插入与删除比较复杂,由于最大长度需要再编程一开始时指定,故当达到最大长度时,扩充长度不如链表方便。
相同
两种结构均可实现数据的顺序存储,构造出来的模型呈线性结构
数组
一、数组的特点
1.在内存中,数组是一块连续的区域
2.数组需要预留空间
在使用前需要提前申请所占内存的大小,这样不知道需要多大的空间,就预先申请可能会浪费内存空间,即数组空间利用率低 ps:数组的空间在编译阶段就需要进行确定,所以需要提前给出数组空间的大小(在运行阶段是不允许改变的)
3.在数组起始位置处,插入数据和删除数据效率低。
插入数据时,待插入位置的的元素和它后面的所有元素都需要向后搬移
删除数据时,待删除位置后面的所有元素都需要向前搬移
4.随机访问效率很高,时间复杂度可以达到O(1)
因为数组的内存是连续的,想要访问那个元素,直接从数组的首地址处向后偏移就可以访问到了
5.数组开辟的空间,在不够使用的时候需要扩容,扩容的话,就会涉及到需要把旧数组中的所有元素向新数组中搬移
6.数组的空间是从栈分配的
二、数组的优点
随机访问性强,查找速度快,时间复杂度为O(1)
三、数组的缺点
1.头插和头删的效率低,时间复杂度为O(N)
2.空间利用率不高
3.内存空间要求高,必须有足够的连续的内存空间
4.数组空间的大小固定,不能动态拓展
链表
一、链表的特点
1.在内存中,元素的空间可以在任意地方,空间是分散的,不需要连续
2.链表中的元素都会两个属性,一个是元素的值,另一个是指针,此指针标记了下一个元素的地址
每一个数据都会保存下一个数据的内存的地址,通过此地址可以找到下一个数据
3.查找数据时效率低,时间复杂度为O(N)
因为链表的空间是分散的,所以不具有随机访问性,如要需要访问某个位置的数据,需要从第一个数据开始找起,依次往后遍历,直到找到待查询的位置,故可能在查找某个元素时,时间复杂度达到O(N)
4.空间不需要提前指定大小,是动态申请的,根据需求动态的申请和删除内存空间,扩展方便,故空间的利用率较高
5.任意位置插入元素和删除元素效率较高,时间复杂度为O(1)
6.链表的空间是从堆中分配的
二、链表的优点
1.任意位置插入元素和删除元素的速度快,时间复杂度为O(1)
2.内存利用率高,不会浪费内存
3.链表的空间大小不固定,可以动态拓展
三、链表的缺点
随机访问效率低,时间复杂度为0(N)
promise all allSettled any race
Promise.all()
promise.all() 如果其中一个 promise reject() 了 就会返回 该 reject()信息
接受一个由promise任务组成的数组,可以同时处理多个promise任务,当所有的任务都执行完成时Promise.all()返回resolve,但当有一个失败(reject),则返回失败的信息,即使其他promise执行成功,也会返回失败。可以用一句话来说Promise.all(),要么全有要么全无。
但话又说回来,有时候我们使用Promise.all()执行很多个网络请求,可能有一个请求出错,但我们并不希望其他的网络请求也返回reject,要错都错,这样显然是不合理的。
手写
Promise.MyAll = function (promises) {
// 返回一个新的 promise list
let arr = [],
count = 0 // 用来计数 如果都 resolve 了 判断length 返回 resolve
return new Promise((resolve, reject) => {
// 循环 传入都promise
promises.forEach((item, i) => {
Promise.resolve(item).then(res => {
// 成功 就往数组里面赋值
arr.push(res)
// 记录 成功次数
count += 1
// 如果都成功 resolve
if (count === promises.length) resolve(arr)
}).catch(reject)
})
})
}
案例
const p1 = Promise.resolve('p1')
const p2 = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('p2 延时一秒')
}, 1000)
})
const p3 = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('p3 延时两秒')
}, 2000)
})
const p4 = Promise.reject('p4 rejected')
const p5 = new Promise((resolve, reject) => {
setTimeout(() => {
reject('p5 rejected 延时1.5秒')
}, 1500)
})
// 所有Promise实例都成功
Promise.all([p1, p2, p3])
.then(res => {
console.log(res)
})
.catch(err => console.log(err)) // 2秒后打印 [ 'p1', 'p2 延时一秒', 'p3 延时两秒' ]
// 一个Promise实例失败
Promise.all([p1, p2, p4])
.then(res => {
console.log(res)
})
.catch(err => console.log(err)) // p4 rejected
// 一个延时失败的Promise
Promise.all([p1, p2, p5])
.then(res => {
console.log(res)
})
.catch(err => console.log(err)) // 1.5秒后打印 p5 rejected
// 两个Promise实例失败
Promise.all([p1, p4, p5])
.then(res => {
console.log(res)
})
.catch(err => console.log(err)) // p4 rejected
Promise.race()
最快的 Promise 成功 Promise.race 就成功,最快的 Promise 失败 Promise.race 就失败。
Promise.race 从字面意思理解就是赛跑,以状态变化最快的那个 Promise 实例为准
手写
Promise.MyRace = (promise) => {
return new Promise((resolve,reject) => {
promise.forEach((item) => {
Promise.resolve(item).then(resolve,reject)
})
})
}
案例
Promise.MyRace = (promise) => {
return new Promise((resolve,reject) => {
promise.forEach((item) => {
Promise.resolve(item).then(resolve,reject)
})
})
}
const p1 = Promise.resolve('p1')
const p2 = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('p2 延时一秒')
}, 1000)
})
const p3 = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('p3 延时两秒')
}, 2000)
})
const p4 = Promise.reject('p4 rejected')
const p5 = new Promise((resolve, reject) => {
setTimeout(() => {
reject('p5 rejected 延时1.5秒')
}, 1500)
})
// p1无延时,p2延时1s,p3延时2s
Promise.MyRace([p1, p2, p3])
.then(res => console.log(res))
.catch(err => console.log(err)) // p1
// p4无延时reject
Promise.MyRace([p4, p2, p3])
.then(res => console.log(res))
.catch(err => console.log(err)) // p4 rejected
// p5 延时1.5秒reject,p2延时1s
Promise.MyRace([p5, p2, p3])
.then(res => console.log(res))
.catch(err => console.log(err)) // 1s后打印: p2 延时一秒
Promise.allSettled()
promise.allSettled() 一定是 所有 promise 的状态发生变更之后 才会返回结果 注意: reject() 不会中断后续执行
方法接受一个数组作为参数,数组的每个成员都是一个 Promise 对象,并返回一个新的 Promise 对象。只有等到参数数组的所有 Promise 对象都发生状态变更(不管是fulfilled还是rejected),返回的 Promise 对象才会发生状态变更,一旦发生状态变更,状态总是fulfilled,不会变成rejected
手写
Promise.MyAllSettled = function (promises) {
let arr = [],
count = 0
return new Promise((resolve, reject) => {
promises.forEach((item, i) => {
Promise.resolve(item).then(res => {
arr[i] = { status: 'fulfilled', val: res }
count += 1
if (count === promises.length) resolve(arr)
}, (err) => {
arr[i] = { status: 'rejected', val: err }
count += 1
if (count === promises.length) resolve(arr)
})
})
})
}
案例
Promise.MyAllSettled = function (promises) {
let arr = [],
count = 0
return new Promise((resolve, reject) => {
promises.forEach((item, i) => {
Promise.resolve(item).then(res => {
arr[i] = { status: 'fulfilled', val: res }
count += 1
if (count === promises.length) resolve(arr)
}, (err) => {
arr[i] = { status: 'rejected', val: err }
count += 1
if (count === promises.length) resolve(arr)
})
})
})
}
const p1 = Promise.resolve('p1')
const p2 = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('p2 延时一秒')
}, 1000)
})
const p3 = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('p3 延时两秒')
}, 2000)
})
const p4 = Promise.reject('p4 rejected')
const p5 = new Promise((resolve, reject) => {
setTimeout(() => {
reject('p5 rejected 延时1.5秒')
}, 1500)
})
// 所有 Promise 实例都成功
Promise.MyAllSettled([p1, p2, p3])
.then(res => console.log(res))
.catch(err => console.log(err))
// [
// { status: 'fulfilled', value: 'p1' },
// { status: 'fulfilled', value: 'p2 延时一秒' },
// { status: 'fulfilled', value: 'p3 延时两秒' }
// ]
// 有一个 Promise 失败
Promise.MyAllSettled([p1, p2, p4])
.then(res => console.log(res))
.catch(err => console.log(err))
// [
// { status: 'fulfilled', value: 'p1' },
// { status: 'fulfilled', value: 'p2 延时一秒' },
// { status: 'rejected' , value: 'p4 rejected' }
// ]
// 所有 Promise 都失败
Promise.MyAllSettled([p4, p5])
.then(res => console.log(res))
.catch(err => console.log(err))
// [
// { status: 'rejected', reason: 'p4 rejected' },
// { status: 'rejected', reason: 'p5 rejected 延时1.5秒' }
// ]
Promise.any
Promise.any() 中只要有一个 Promise 实例成功就成功
与 Promise.all 可以看做是相反的。只有当所有的 Promise 实例失败时 Promise.any 才失败,此时Promise.any 会把所有的失败/错误集合在一起,返回一个失败的 promise 和AggregateError类型的实例。
手写
Promise.MyAny = function (promises) {
let arr = [],
count = 0
return new Promise((resolve, reject) => {
promises.forEach((item, i) => {
Promise.resolve(item).then(resolve, err => {
arr[i] = { status: 'rejected', val: err }
count += 1
if (count === promises.length) reject(new Error('没有promise成功'))
})
})
})
}
案例
Promise.MyAny = function (promises) {
let arr = [],
count = 0
return new Promise((resolve, reject) => {
promises.forEach((item, i) => {
Promise.resolve(item).then(resolve, err => {
arr[i] = { status: 'rejected', val: err }
count += 1
if (count === promises.length) reject(new Error('没有promise成功'))
})
})
})
}
const p1 = Promise.resolve('p1')
const p2 = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('p2 延时一秒')
}, 1000)
})
const p3 = new Promise((resolve, reject) => {
setTimeout(() => {
resolve('p3 延时两秒')
}, 2000)
})
const p4 = Promise.reject('p4 rejected')
const p5 = new Promise((resolve, reject) => {
setTimeout(() => {
reject('p5 rejected 延时1.5秒')
}, 1500)
})
// 所有 Promise 都成功
Promise.MyAny([p1, p2, p3])
.then(res => console.log(res))
.catch(err => console.log(err)) // p1
// 两个 Promise 成功
Promise.MyAny([p1, p2, p4])
.then(res => console.log(res))
.catch(err => console.log(err)) // p1
// 只有一个延时成功的 Promise
Promise.MyAny([p2, p4, p5])
.then(res => console.log(res))
.catch(err => console.log(err)) // p2 延时1秒
// 所有 Promise 都失败
Promise.MyAny([p4, p5])
.then(res => console.log(res))
.catch(err => console.log(err)) // AggregateError: All promises were rejected
react router exact starict 区别
exact
exact默认为false,如果为true时,需要和路由相同时才能匹配,但是如果有斜杠也是可以匹配上的。
如果在父路由中加了exact,是不能匹配子路由的,建议在子路由中加exact,如下所示
//父路由
<Switch>
<Route path="/a" component={ComponentA} />
</Switch>
//子路由,tuanDetail组件里
<Switch>
<Route path="/a/b" exact component={ComponentB}/>
</Switch>
strict
<Route strict path="/one" component={About} />
strict默认为false,如果为true时,路由后面有斜杠而url中没有斜杠,是不匹配的
\
实现一个最大并发数的 批量请求 有顺序返回
利用 promise.allSettled 配合 数组切片 (maxNum)
function sliceArr (arr, count) {
let result = [];
//遍历输出成员
arr.forEach((item, index) => {
let temp = Math.floor(index / count);
//检验数组是否初始化
if (!(result[temp] instanceof Array)) {
result[temp] = new Array;
}
result[temp].push(item);
})
return result;
}
const allRequest = async (urls, maxNum) => {
// 切片
const arr = sliceArr(urls, maxNum)
const result = []
for (let i = 0; i < arr.length; i++) {
const data = await Promise.allSettled(arr[i])
result.push(...data)
}
console.log(result)
return result
}
const p1 = new Promise((resolve, reject) => {
resolve('p1')
})
const p2 = new Promise((resolve, reject) => {
resolve('p2')
})
const p3 = new Promise((resolve, reject) => {
reject('p3')
})
const p4 = new Promise((resolve, reject) => {
resolve('p4')
})
const p5 = new Promise((resolve, reject) => {
resolve('p5')
})
const p6 = new Promise((resolve, reject) => {
resolve('p6')
})
allRequest([p1, p2, p3, p4, p5, p6], 2)
Promise 执行顺序 (Js引擎)
Promise.resolve().then(() => {
console.log(0);
return Promise.resolve(4);
}).then((res) => {
console.log(res)
return
})
.then((res) => {
console.log(7)
})
.then((res) => {
console.log(8)
})
Promise.resolve().then(() => {
console.log(1);
}).then(() => {
console.log(2);
}).then(() => {
console.log(3);
}).then(() => {
console.log(5);
}).then(() =>{
console.log(6);
})
// 大家先思考一下
结论
Js引擎为了让microtask尽快的输出,做了一些优化,连续的多个then(3个) 如果没有reject或者resolve会交替执行then而不至于让一个堵太久完成用户无响应,不单单v8这样 其他引擎也是这样,因为其实promise内部状态已经结束了。这块在v8源码里有完整的体现
答案
通过结论 得出答案
0,1,2,3,4,5,7,6,8
运行 npm run xxx 的时候发生了什么?
对象隐士转换
var a = { name: "Sam" };
var b = { name: "Tom" };
var o = {};
o[a] = 1;
o[b] = 2;
console.log(o[a]);
答案 : 2
原因
- 对象会隐士转换成 "[object Object]"
- 所以 o[a] = o[ "[object Object]" ] = 1 o[b] = o[ "[object Object]" ] =2
- 改变的都是o 对象里面的 "[object Object]" 这个key 的value 所以是2
js 为什么基本数据类型存到栈但是引用数据类型存到堆
原始值:
存储在栈(stack)中的简单数据段,也就是说,它们的值直接存储在变量访问的位置。
这是因为这些原始类型占据的空间是固定的,所以可将他们存储在较小的内存区域 – 栈中。这样存储便于迅速查寻变量的值。
引用值:
存储在堆(heap)中的对象,也就是说,存储在变量处的值是一个指针(point),指向存储对象的内存地址。
这是因为:引用值的大小会改变,所以不能把它放在栈中,否则会降低变量查寻的速度。相反,放在变量的栈空间中的值是该对象存储在堆中的地址。 地址的大小是固定的,所以把它存储在栈中对变量性能无任何负面影响。
SPA 和 MPA 的区别
什么是SPA
- SPA(single-page application),
- 翻译过来就是单页应用SPA是一种网络应用程序或网站的模型,它通过动态重写当前页面来与用户交互
- 这种方法避免了页面之间切换打断用户体验在单页应用中,所有必要的代码(HTML、JavaScript和CSS)都通过单个页面的加载而检索,
- 我们熟知的JS框架如react,vue,angular,ember都属于SPA
什么 是 MPA
- 多页应用MPA(MultiPage-page application)
- 翻译过来就是多页应用在MPA中,每个页面都是一个主页面,都是独立的当我们在访问另一个页面的时候,都需要重新加载html、css、js文件
- 公共文件则根据需求按需加载如下图
单页应用与多页应用的区别
| 单页面应用(SPA) | 多页面应用(MPA) | |
|---|---|---|
| 组成 | 一个主页面和多个页面片段 | 多个主页面 |
| 刷新方式 | 局部刷新 | 整页刷新 |
| url模式 | 哈希模式 | 历史模式 |
| SEO搜索引擎优化 | 难实现,可使用SSR方式改善 | 容易实现 |
| 数据传递 | 容易 | 通过url、cookie、localStorage等传递 |
| 页面切换 | 速度快,用户体验良好 | 切换加载资源,速度慢,用户体验差 |
| 维护成本 | 相对容易 | 相对复杂 |
单页应用优缺点
优点:
- 具有桌面应用的即时性、网站的可移植性和可访问性
- 用户体验好、快,内容的改变不需要重新加载整个页面
- 良好的前后端分离,分工更明确
缺点:
- 不利于搜索引擎的抓取
- 首次渲染速度相对较慢
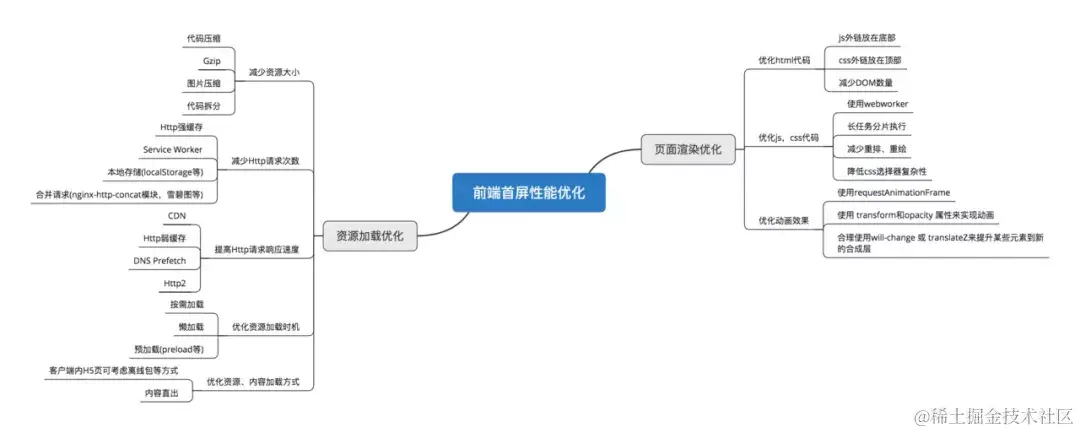
单页应用的首评优化
 实现一个函数,每调用一次,函数输出值 +1
实现一个函数,每调用一次,函数输出值 +1
const add = (function () {
let i = 0
return function () {
return ++i
}
})()
console.log(add())// 1
console.log(add())// 2
function add () {
let i = 0
return function () {
return ++i
}
}
const temp = add() // 先用一个临时变量接收执行 add 的返回值,再调用 temp()
console.log(temp()) // 1
console.log(temp()) // 2
// 如果直接写 add()() 不会生效
function fn () {
var i = 0
return { // fn 函数返回一个对象,有 get、set 等方法,来操作私有变量 i
get: function () {
return i
},
set: function (val) {
i = val
},
increment: function () {
return ++i
}
}
}
const counter = fn() // 执行 fn 函数,拿到 counter 对象
counter.get() // 0
counter.set(3)
counter.increment() // 4
counter.increment() // 5
路由原理
两种模式
前端路由实现起来其实很简单,本质就是监听 URL 的变化,然后匹配路由规则,显示相应的页面,并且无须刷新页面。目前前端使用的路由就只有两种实现方式
- Hash 模式
- History 模式
Hash 模式
www.test.com/#/ 就是 Hash URL,当 # 后面的哈希值发生变化时,可以通过 hashchange 事件来监听到 URL 的变化,从而进行跳转页面,并且无论哈希值如何变化,服务端接收到的 URL 请求永远是 www.test.com。
window.addEventListener('hashchange', () => {
// ... 具体逻辑
})
History 模式
History 模式是 HTML5 新推出的功能,主要使用 history.pushState 和 history.replaceState 改变 URL。
通过 History 模式改变 URL 同样不会引起页面的刷新,只会更新浏览器的历史记录。
// 新增历史记录
history.pushState(stateObject, title, URL)
// 替换当前历史记录
history.replaceState(stateObject, title, URL)
当用户做出浏览器动作时,比如点击后退按钮时会触发 popState 事件
window.addEventListener('popstate', e => {
// e.state 就是 pushState(stateObject) 中的 stateObject
console.log(e.state)
})
两种模式对比
- Hash 模式只可以更改 # 后面的内容,History 模式可以通过 API 设置任意的同源 URL
- History 模式可以通过 API 添加任意类型的数据到历史记录中,Hash 模式只能更改哈希值,也就是字符串
- Hash 模式无需后端配置,并且兼容性好。History 模式在用户手动输入地址或者刷新页面的时候会发起 URL 请求,后端需要配置 index.html 页面用于匹配不到静态资源的时候
