

这是我参与「第四届青训营」笔记创作活动的的第8天
01.发展历史
数据湖发展阶段- Hadoop
-
数据湖最开始的概念一 分布式存储HDFS
-
使用目录来区分不同的数据集
-
好处:
- 同一公司/组织可以使用共享存储
- 数据访问方便,灵活性高
-
坏处:
- 没有记录文件的schema (包括列名、列类型),经常使用Schema on Query的方式
- 难以得知数据集包含了那些文件,是通过什么样的分区组织的
- 如果多个程序都在修改这个数据集(修改数据、修改表结构),其他程序难以配合做修改
数据湖发展阶段2 - Hive
-
数据湖的演进
-
Hive Metastore
- 对数据湖中的数据集进行集中"定义”
- 数据湖中存在了哪些数据集
- 它们都存储在什么目录
- 数据集的schema是什么样子的
- 数据集有哪些分区,每个分区的目录是什么
-
如果这张hive表是静态的,没有新增写入,则所有读取方都能很便捷的使用
-
问题来了:
- ①假设Reader A和B都正在读取分区/20220623下的文件
- 此时Writer B开始重写/20220623分区,一些文件被删了,一 些文件增加了,一 些文件还在修改中
- Reader A和B读到的文件可能是不同的!
-
我们需要Transaction ACID!
-
问题又来了:
- 分区/20220623下存储了schema为date | userld | phoneNumber的数据
- 需要注意: Hive allows us to add column after last column only
- 根据合规,我需要删掉phoneNumber, 但是在Hive表上做不到。只好重写一张表(耗费资源)
-
我们需要支持更多样的schema变更!
-
And more!
数据湖发展阶段3 -湖仓一体
题外话——数据仓库
-
什么是数据仓库?
- 数据仓库将数据从数据源提取和转换,加载到目的地
- 数据仓库存储+计算不分离
- 数据仓库严格控制写入数据的schema
湖仓一体(数据湖的现状) :
- 结合了数据湖和数据仓库的优势
- 将数据仓库中对于数据的严格管理直接实现到了低成本的分布式存储之上
-
Key Features:
- Transaction ACID
- Schema管理
- 存储计算分离
- 由支持多种计算引擎和文件格式
02.核心技术
Time travel
- 每次写入都生成个新的元数据文件, 记录变更
- 分区数据在Update时, 不要删除旧数据,保证新旧共存
- 元数据中存储具体的文件路径,而不仅仅是分区文件夹
-
每一次写入操作,创建一个 新的json文
件,以递增版本号命名,记录本次新增/删
除的文件。
-
每当产生N个json,做-次聚合,记录
完整的分区文件信息
-
用checkpoint记录上次做聚合的版本号
Transaction
交易?事务! ACID,是指数据库在写入或更新资料的过程中,为保证事务是正确可靠的,所必须具备的四个特性。 以A给B转账10元为例:
- Atomicity: 原子性- 要么A-10 B+10,要么都不变
- Consistency: 一致性 不可以A-10 B+5
- lsolation: 事务隔离 A和C同时给B转10, B最终结果应是+20
- Durability: 持久性- 转账服务器重启,结果不变
数据湖中的ACID:
- Atomicity: 原子性-本次写入要么对用户可见,要么不可见(需要设计)
- Consistency: -致性-输入是什么,落盘的就是什么(由计算弓|擎保证)
- lsolation: 事务隔离-正确解决读写冲突和写写冲突(需要设计)
- Durability: 持久性-落完数据后,即便服务器重启结果不变( 由存储引擎保证)
Schema Evolution
-
Add/Drop/Rename
-
重要:
- 用户并不直接读取parquet文件本身, 而是通过数据湖接口读取,如
Dataset<Row> ds =simpleDataL ake.read(mytable).option(date=2020 01-01) - 数据湖内部会读取应该读的parquet, 并在schema上做进一步处理
- 用户并不直接读取parquet文件本身, 而是通过数据湖接口读取,如
ID将data和metadata的列名做一一对应!
-
1.唯一确定的ID。新增列赋予新ID。删列ID不复用。
-
2.写入数据时,ID也写入数据文件
-
3.读取数据时,用ID做映射,如果
- Data中没有, metadata中有: ADD
- Data中有, metadata中没有: DROP
- Data和metadata中都有同一 -ID,但是name不同: RENAME
- 如果都有同一列名,而ID不同?
03.各有所长
Iceberg工作重点
➢用户体验
- Schema evolution
- Partition evolution
- Hidden partition
- Time Travel
- Version Rollback
➢性能
- 快速file plan
- 更多的filter方式
➢可靠性
ACID Transaction
➢完全开源,由Apache孵化开发
Well-designed Metadata Layer
Data File Filter
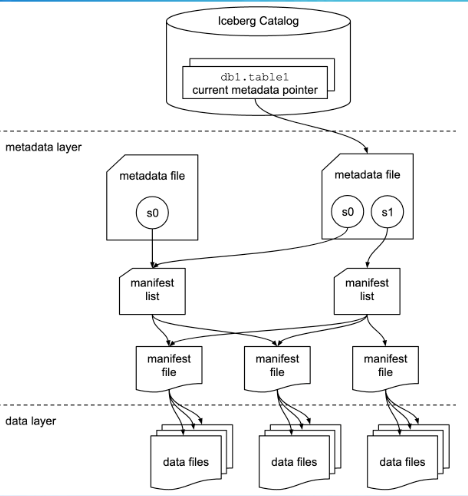
Hidden Partition
➢传统的分区方式: D数据中包含了date列,则按照date分区;如果希望按照hour分区,则需要新增hour列
-
➢Iceberg的分区方式:
-
数据中包含timestamp列,设置好partition transform式
- 设置为date时,iceberg 帮你转化为date分区
- 设置为hour时,iceberg 帮你转化为hour分区
- Iceberg记录了这层转化关系,并且按你的需要进行partition evolution
Hudi
Hadoop Upsert Delete and Incremental
Hudi工作重点:
- Timeline service: Hudi 管理transaction的方式
- Hudi Table Type: Copy on Write / Merge on Read
- 高效的Upserts: update or insert
- 索引表:快速定位一条数据的位置
- Streaming Ingestion Service
- 完全开源,由Apache孵化
Timeline Serivce & Upsert & Incremental
- Timeline Service:记录的信息类似于metadata
- Upsert: 每一 条样本都有一 个主键PK,当Upsert-条数据时,如果现有的数据中有这个PK,则update这条数据。否则直接insert这条数据
- Incremental: 某个时间点后新增的数据
Copy on Write
Merge On Read
3.3 Delta Lake工作重点
- ACID Transaction
- Schema 校验(不是evolution)
- 流批一体
- Time Travel
- Upsert/Delete
- Z Order优化
- 只开源了一部分,由Databricks自己主导开发,Z-order 等优化的实现未开源
04.总结场景
回顾:三个数据湖的异同
-
短期来看:每个项目都有一些属于自己的功能,
- 如果强需求Upserts,也许Hudi是最好的选择
- 如果希望可扩展性强,那么设计优良的Iceberg是最好的选择
- 如果希望用上Z- Order等优化,那么掏钱买Databricks 的企业版Delta是不二之选
-
长期来看:数据湖取代Hive,成为HDFS上的表格式标准是必然的,在选择之前问自己四个问题:
- 我需要的feature在哪个数据湖上是最稳定的
- 哪一个数据湖能够用最简单的接入方式(SQL)用上最完善的功能
- 哪一个数据湖有计算引擎侧的支持和社区的支持
- 哪一个数据湖的版本管理做的最好,最鲁棒
