

什么是Airflow?
Airflow是一个开源的平台,用于安排和监控工作流程。它提供了一个Web界面,你可以启动、开始或停止执行DAG,并看到每个任务的日志和状态。
一个DAG是一个需要执行的任务序列。Airflow提供了与不同平台的集成。
Airflow可以安装在Kubernetes集群中,其中Airflow所需的不同组件被安装为独立的pod。
什么是Spark?
Apache Spark是一个处理大规模数据的框架,你可以在其中用Java、Scala、Python或R语言运行你的代码。
Spark工具还提供额外的工具,如用于SQL的Spark SQL,用于机器学习的MLlib,用于图形处理的GraphX,以及结构化流。
星火集群
Spark可以作为独立的任务在集群模式下运行。这些任务由SparkContext协调,可以连接到不同类型的集群:

它由一个主从架构组成,其中工作节点(从属)负责任务的执行。集群管理器负责将工作划分为要处理的任务。下面是一个spark应用程序的执行方式。
Spark Context:连接到一个spark执行环境。
集群管理器
- 安排spark应用程序。
- 将资源分配给驱动程序,以运行任务。
- 分割成任务并分配到工作节点上。
工作者节点:执行分配的任务:
运行spark集群有不同的集群管理器类型。你可以作为一个独立的节点运行,当你只有一个Spark工作负载时,这对创建一个小集群很有用。
当你需要创建一个更大的集群时,最好使用一个更复杂的架构,解决调度和监控应用程序等问题。
以下是可用的集群管理器类型:
- Hadoop YARN- 一个运行应用程序的资源管理器。
- Apache Mesos- 一个通用的集群管理器,用于运行框架。
- Kubernetes- 用于部署和管理容器化应用程序。
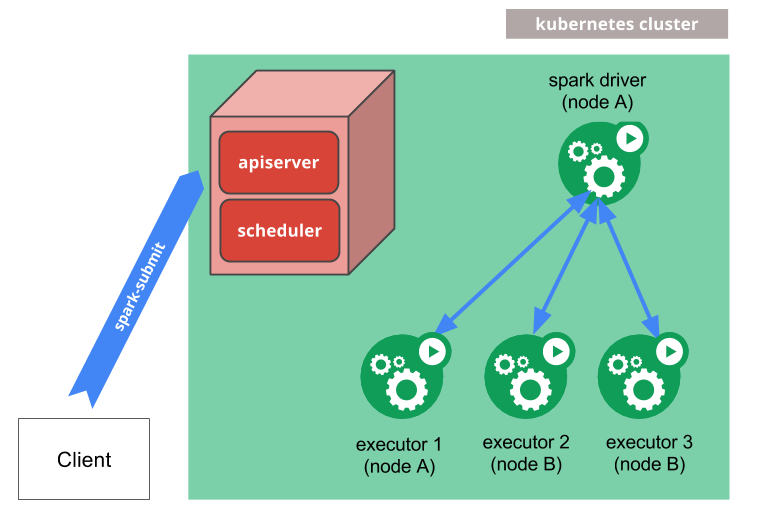
在Kubernetes上运行Spark
既然我们有了用于Airflow的Kubernetes集群,那么在同一个集群中运行所有东西是有意义的。这就是Kubernetes上的Spark是如何工作的:
- 从集群外部或内部用spark-submit运行。
- 请求被发送到API服务器(Kubernetes主服务器)。
- 为Spark驱动创建一个pod。
- Spark驱动请求执行器来运行任务。
- 荚的执行器被运行,然后它们运行应用的代码。
- 当应用程序完成后,执行器的pod被杀死,但驱动程序会持续记录日志以跟踪结果。
Docker图像
要在Kubernetes中运行一个任务,你需要提供一个docker镜像,它将在执行者的pod中执行。Spark包含一个Docker文件来建立一个镜像基础,或者你也可以创建你自己的自定义镜像。
当你运行应用程序时,你可以设置你想使用的执行器的数量。
如果启用了动态分配,你可以让Kubernetes按需启动执行器:
什么是Apache Livy?
Apache Livy是一个REST服务,用于提交Spark作业Spark集群。使用Apache Livy,你可以:
- 享受轻松提交Spark作业的乐趣。
- 配置,以确保通过认证的安全性。
- 启用火花作业之间共享缓存和RDDs。
- 管理多个火花上下文。
- 利用Web界面来跟踪作业。
架构
从Airflow中,任务可以使用Apache Livy在Spark集群中执行:
在EKS中的部署
Airflow
你可以使用这个repo 在 EKS 中部署 Airflow。你需要为持久化卷使用EFS CSI驱动,因为它支持多个节点同时读写。
火花集群
Spark集群在同一个Kubernetes集群中运行,并共享卷来存储中间结果。Spark节点在需要时按需创建,并作为集群中的独立豆荚。
安装Apache Livy
为了安装apache Livy,你需要使用这个repo并完成这些步骤。
Livy Operator
为了支持Airflow中的Livy Operator,你将需要以下的依赖关系,如这里所述。
为了支持这一点,图像 [rootstrap/eks-airflow:2.1.2] 。 位于这里,然后通过这个repo 创建。
题外话,如果你想添加更多的依赖项,只需使用该Docker文件,添加。
*pipinstall\[the necessary dependencies\]*
要做到这一点,构建并推送该图像,并更新图像的名称和版本,在 [values.yaml]。 文件这里。
你可以通过改变defaultAirflowRepository和defaultAirflowTag的相应值来实现这一点。
*defaultAirflowRepository: rootstrap/eks-airflowdefaultAirflowTag: "2.1.2"*
修改完values.yaml后,你再用新的镜像升级图表。
*helm upgrade airflow -n airflow.*
Livy连接
你可以在Airflow网络控制台的 "连接 "部分配置一个apache Livy连接。
在这样做的时候,添加一个带有这些参数的连接:
- 连接标识:Livy_conn_id
- 连接类型:连接类型:Apache Livy
- 描述Apache Livy REST API
- 主机:获取apache-livy的ClusterIP 执行
:kubectl get services | grep apache-livy | awk '{print $3}' - 端口:8998
从DAG中,你可以创建一个任务,使用配置的连接调用Apache Livy。 你可以在这里看到这个DAG的例子。
总结
通过上述的架构,我们有效地实现了以下结果:
- 任务的隔离
- 横向和纵向可扩展性
- 用spark更快地处理
- 可追溯性
谢谢你的阅读,请继续关注更多类似的内容。
