

本文将帮助你了解Azure数据工厂的数据流组件中提供的所有转换。
简介
数据传输和转换的一个主要实践领域是ETL管道的开发。有许多工具和技术可以在企业内部和云端建立ETL管道。一个ETL工具的效率与支持的数据转换数量一样,因为转换是实现构建丰富ETL管道的关键因素,开发人员可以使用开箱即用的控件来构建数据转换,而不是放置大规模的定制开发工作来转换数据。Azure数据工厂是Azure云上的一项服务,有利于开发ETL管道。在Azure数据工厂中转换数据的典型方法是使用数据流组件中的转换。在这个组件中,有几种转换方式可用。在本文中,我们将介绍数据流组件中提供的所有转换,我们将了解一些关键的设置以及可以使用这些转换的用例。
数据流转换
要访问数据工厂中的转换列表,需要创建一个实例,我们可以用它来创建数据管道。我们可以创建数据流,它可以作为数据管道的一部分来使用。在数据流图中,一旦你添加了一个或多个数据源,那么下一个逻辑步骤就是向它添加一个或多个转换。
联接
当你点击图形中的+号来添加转换时,这是你在列表中发现的第一个转换。通常情况下,当你有来自一个或多个数据源的数据时,需要将这些数据绑定到一个共同的数据流中,对于这种使用情况,可以使用这种转换。下面显示的是支持的不同类型的连接,以及用不同操作符指定连接条件的选项。
分割
在Azure Data Factory中,分割转换可以用来根据一个标准将数据分成两个数据流。可以根据第一个匹配标准或所有匹配标准来分割数据。这有利于使用此转换将数据分类划分为不同的数据流的离散类型的数据处理。
存在(EXISTS
Azure Data Factory中的Exists转换相当于SQL中的EXISTS子句。它可以使用一个或多个条件来比较一个流的数据和另一个流的数据。如下所示,人们可以使用exists和does not exist,即exist的逆向,使用不同类型的表达式找到匹配或唯一的数据集。
联合
Azure Data Factory中的联合转换等同于SQL中的联合子句。它可以用来将具有相同或兼容模式的两个数据流的数据合并成一个数据流。两个数据流的模式可以通过列的名称或顺序位置来映射,如下图的设置。
查找(LOOKUP
Azure数据工厂中的查找转换是最关键的数据转换之一,在涉及交易系统和数据仓库的数据流中使用。在向维度或事实加载数据时,需要验证数据是否已经存在,以采取相应的更新或插入数据的行动。在交易系统中,这种转换也可以用来执行UPSERT类型的操作。查询转换从传入的数据流中获取数据,并与查询流中的数据相匹配,将查询流中的列追加到主流中。
衍生的列
通过这个转换,我们从模式修改器类别的转换开始。通常情况下,需要在数据流中创建新的计算字段或更新现有字段的数据。在这种情况下可以使用派生列转换。我们可以在这个转换中添加所需的字段,并为新字段提供计算表达式,如下所示。
选择
当输入流中的数据被处理时,在连接、合并、分割和创建计算字段时,可能会导致一些不必要的字段或重复的字段。为了从数据流中删除这些字段,人们可以重命名字段,改变映射,以及从数据流中删除不需要的字段。SELECT转换有助于实现这一功能,以管理数据流中的字段。
AGGREGATE
大多数ETL数据管道涉及某种形式的数据聚合,通常是在将数据加载到数据仓库或分析数据存储库时。在SQL中聚合或滚动数据的明显机制之一是使用GROUP BY子句。这个功能可以通过使用Azure Data Factory中的Gregate转换来行使。虽然分组是最常见的汇总数据的方式,但它不是唯一的方式。也可以创建不同类型的聚合计算,用于基于某个条件的自定义计算。为了解决这种情况,可以使用汇总选项卡(如下所示),在这里可以配置这种自定义计算。
叠加键(SURROGATE KEY
在数据仓库场景中,通常是在缓慢变化的维度(SCD)中,人们不能使用业务键作为主键,因为业务键会随着同一记录的不同版本的创建而重复,所以要创建代理键,作为记录的唯一标识。Azure数据工厂提供了一个转换,可以使用代理键转换生成这些代理键。
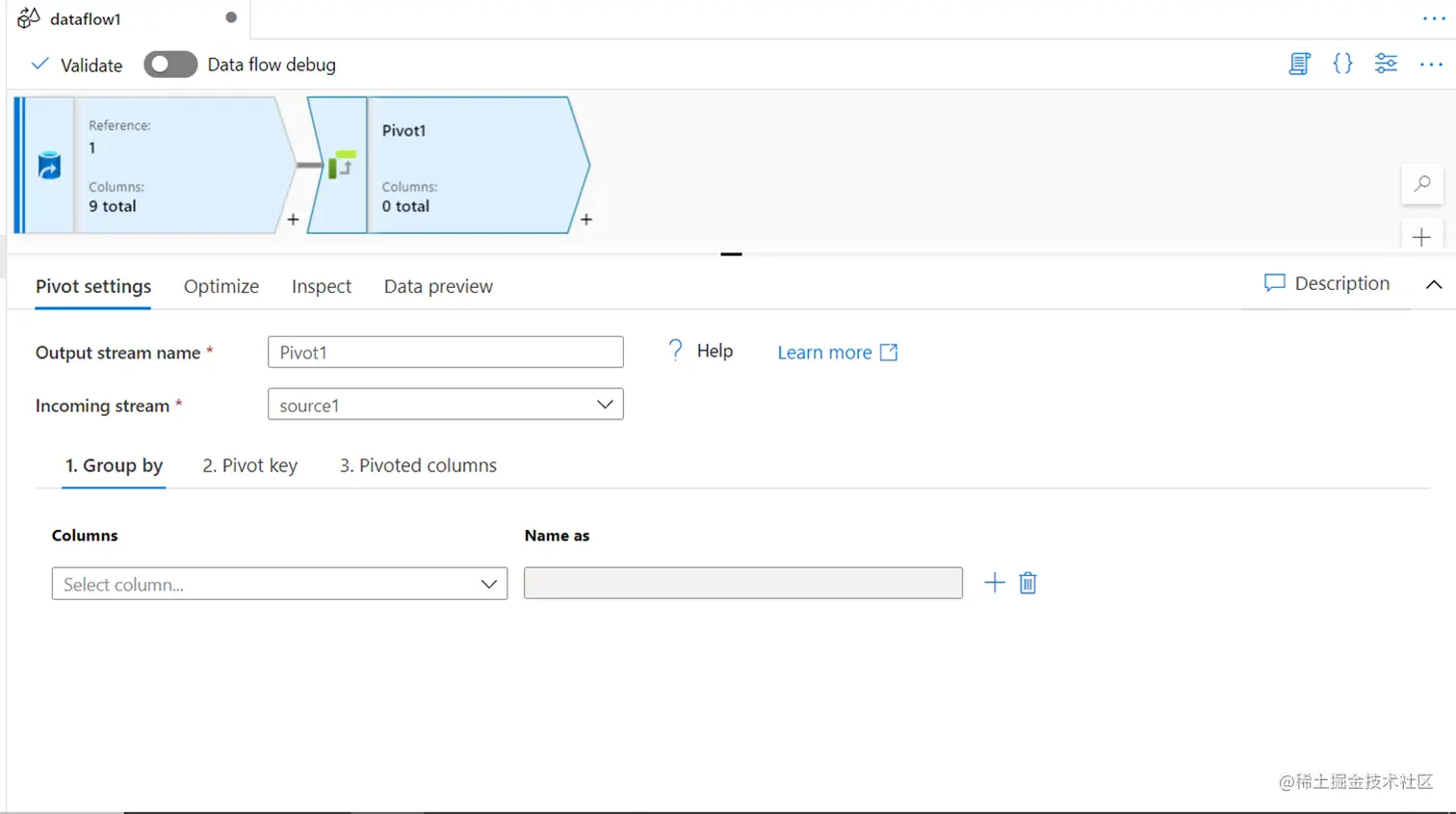
PIVOT
将一个字段的行的唯一值转换为列,被称为数据的透视。数据透视是一个非常常见的功能,从大多数基本的数据工具如Microsoft Excel到所有不同类型的数据库都可以使用。通常情况下,在处理嵌套格式的数据时,例如JSON文件中的数据,需要将数据调制成特定的模式,用于报告或汇总。在这种情况下,人们可以使用PIVOT转换。配置透视转换的设置如下所示。
 UNPIVOT
UNPIVOT
Unpivot转换是pivot转换的逆向,它将列转换为行。在枢轴转换中,数据是按照标准分组的,在这种情况下,数据是未分组和未枢轴的。如果我们将下面显示的设置与枢轴转换的设置相比较,它们几乎是相同的。
窗口
窗口转换支持使用窗口函数创建聚合,例如RANK。它允许使用自定义表达式建立复杂的聚合,这些表达式可以使用众所周知的窗口函数,如rank、denserank、ntile等。如果你在任何数据库中使用过窗口函数,你会发现非常容易理解下面所示的图形界面,它可以使用这个转换配置类似的功能。
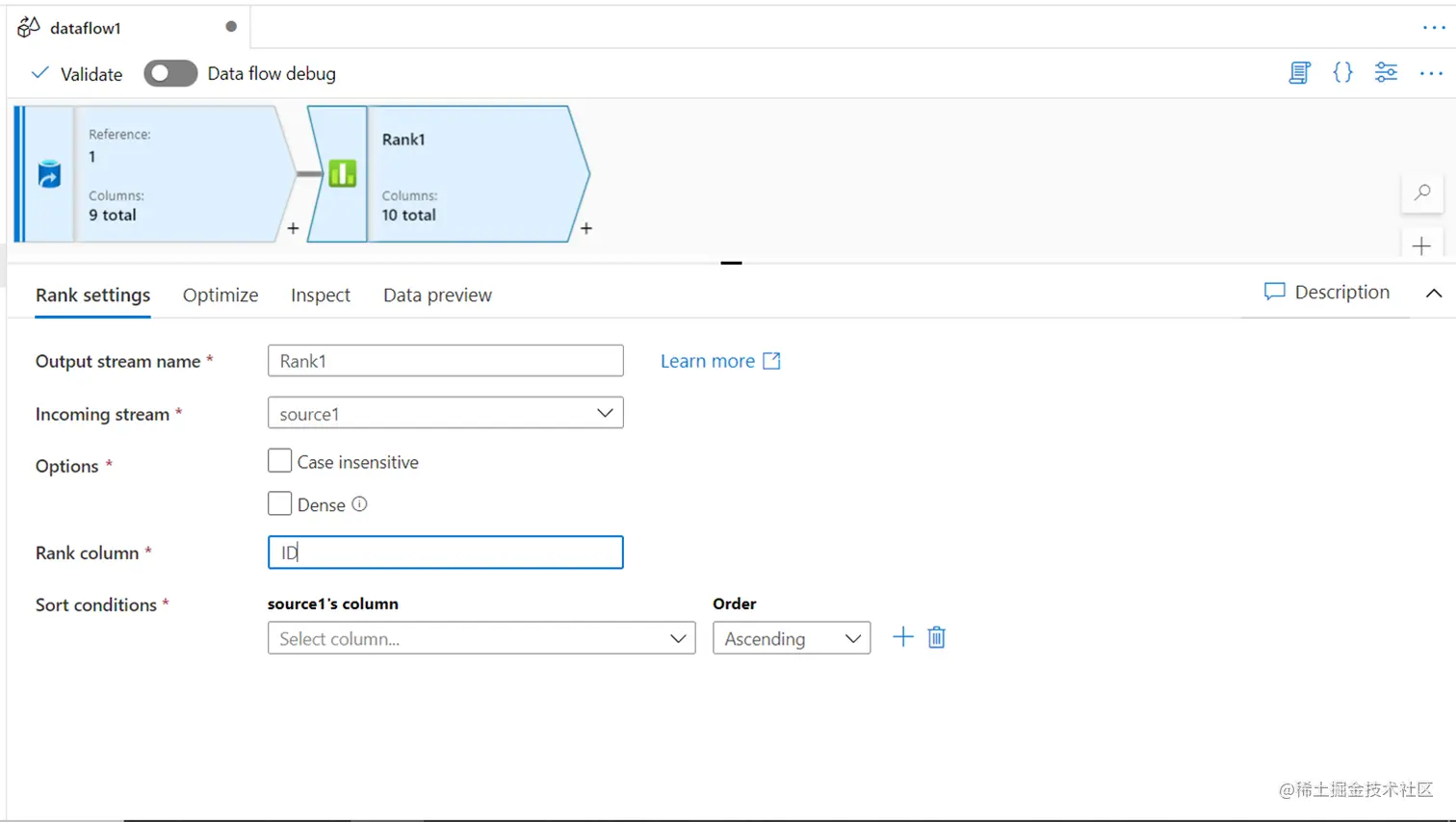
排名
一旦数据被引导到不同的数据流中,通过不同的源和目标存储库进行验证,计算,并使用自定义表达式进行汇总,在数据管道的末端,人们通常会对数据进行排序。在这种情况下,可能需要根据特定的排序标准对数据进行排序。Azure数据工厂中的等级转换可以通过下面的选项来实现这一功能。
 扁平化
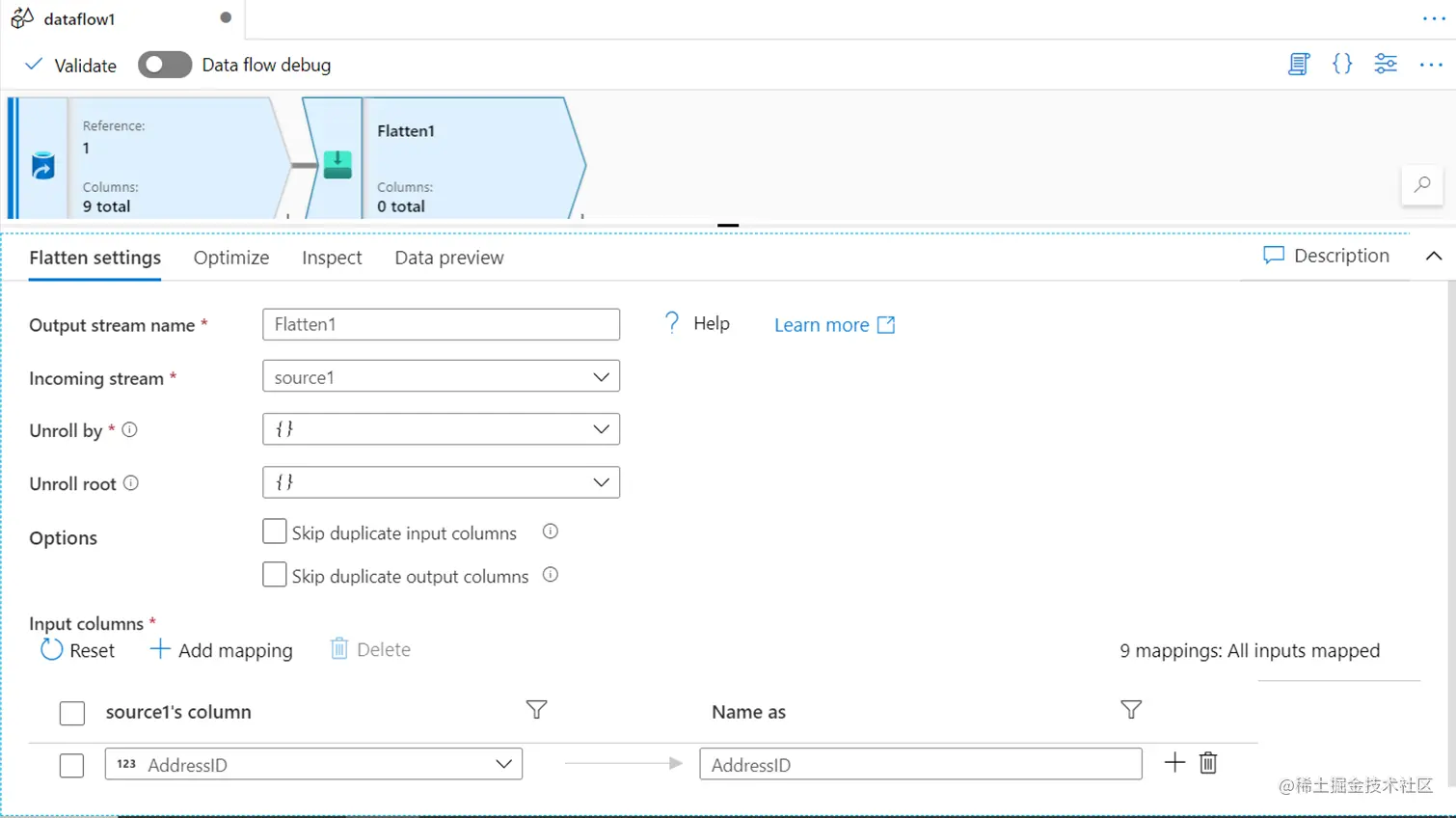
扁平化
有时,当数据是分层或嵌套的,并且要求将数据平铺成表格结构,而不需要进一步优化,如透视或取消透视,在Azure数据工厂中平铺数据的一个更简单的方法是使用平铺转换。这种转换将数组或任何嵌套结构中的值转换为扁平化的行和列结构。
 PARSE
PARSE
数据大多是以结构化格式从数据存储库中读取的。但数据也存在于半结构化或文档格式中,如XML、JSON和分隔的文本文件。一旦数据从这样的格式中获取,就可能需要对这样的数据格式中的字段和数据类型进行解析,然后才能用这样的数据进行其他的转换。对于这种情况,我们可以使用下面的设置来使用Parse转换。
过滤
数据处理中最常见的部分之一是对数据进行过滤,以限制数据的范围并有条件地处理它。筛选器就是这样一个转换,它有助于在Azure Data Factory中筛选数据。
排序
另一个与过滤转换相配合的转换是排序转换。有时,某些涉及时间序列的数据集,如果不进行排序,就不可能正确处理。另外,当数据准备加载到目标数据存储库时,对数据进行排序并以排序的方式加载是一个好的做法。在这种情况下可以使用排序转换。
这些都是Azure Data Factory的数据转换组件中的所有转换,以建立一个数据流,将数据转换为所需的形状和大小。
总结
在这篇文章中,我们介绍了Azure数据工厂的数据转换组件所提供的不同转换。我们了解了当我们考虑使用这些转换时的高级用例,并通过这些转换的配置设置进行了探讨。
