

本文将提到查询优化器在哪些条件下决定对查询进行重新编译,以及它如何影响SQL查询的性能。
老大:查询优化器
基本上,当我们向SQL Server提交一个查询时,它会执行3个基本阶段。
- 查询解析:在这个阶段,查询语法的正确性被检查。在这一阶段,生成一个解析树,以发送至下一阶段
- 查询绑定(Algebrizer):这个阶段的主要职责是验证数据库中的列、表和其他对象是否存在。同时,它检查用户对查询中存在的对象是否有权限。
- 查询优化:这一步是查询处理中最复杂和与查询性能有关的阶段,因为查询计划是在这一步形成的。SQL Server查询优化器执行基于成本的优化,因此它评估不同的查询计划候选人,并决定具有最低成本的查询计划。在第一次执行查询后,生成的查询计划被存储在计划缓存中,以便在下一次执行相同的查询时使用。在这一点上,不同的原因可以导致重新编译位于查询计划缓存中的查询
下面的查询结果给了我们所有可能的查询重新编译的原因。
SELECT dxmv.name,
dxmv.map_key,
dxmv.map_value
FROM sys.dm_xe_map_values AS dxmv
WHERE dxmv.name = N'statement_recompile_cause'
ORDER BY dxmv.map_key
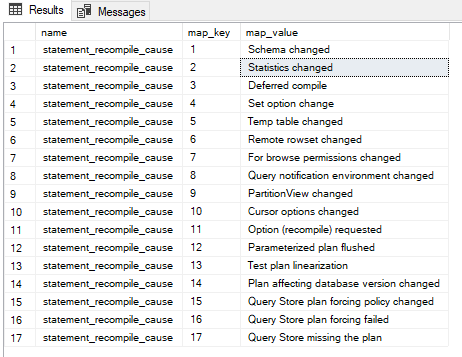
- 模式改变了
- 统计数据改变了
- 推迟编译
- 设置选项改变
- 临时表改变了
- 更改了远程行集
- 更改了浏览权限
- 查询通知环境改变
- 分区视图改变
- 游标选项已更改
- 要求的选项(重新编译)。
- 冲洗了参数化的计划
- 测试计划线性化
- 改变了影响数据库版本的计划
- 查询存储计划强制策略改变
- 查询库计划强制失败
- 查询库丢失计划
监控查询的重新编译
SQL Server Extended Event是一个系统监控工具,有助于监控数据库的性能指标,并收集不同的事件。这样,我们就可以轻松地使用扩展事件来解决查询性能问题。从这个想法出发,使用扩展事件来监控重新编译似乎是一个合适的解决方案。sql_statement_recompile事件可以捕获并报告何时发生了语句级的重新编译。下面的查询将创建并启动一个扩展事件,帮助报告查询被重新编译的情况。
CREATE EVENT SESSION CaptureQuery_Recompilations ON SERVER
ADD EVENT sqlserver.sql_statement_recompile(
ACTION(sqlserver.database_name,sqlserver.query_hash_signed,
sqlserver.query_plan_hash_signed,sqlserver.sql_text,
sqlserver.username))
ADD TARGET package0.ring_buffer
WITH (STARTUP_STATE=ON);
GO
另一方面,SQL Profiler是另一个监测重新编译的工具,和SQL.StmtRecompile事件类。StmtRecompile事件类在重新编译发生时报告。为了在SQL Profiler中启用这个事件类,我们需要在跟踪属性中选择它们。因此,我们可以使用SQL Profiler来监控查询性能,但要注意这个SQL已经废弃了。在Adventureworks数据库中,我们将执行以下查询,它将包含OPTION(RECOMPILE)查询提示。由于这个提示,执行的查询将被优化器重新编译。
SELECT
p.[ProductID]
,p.[Name]
,pm.[Name] AS [ProductModel]
,pmx.[CultureID]
,pd.[Description]
FROM [Production].[Product] p
INNER JOIN [Production].[ProductModel] pm
ON p.[ProductModelID] = pm.[ProductModelID]
INNER JOIN [Production].[ProductModelProductDescriptionCulture] pmx
ON pm.[ProductModelID] = pmx.[ProductModelID]
INNER JOIN [Production].[ProductDescription] pd
ON pmx.[ProductDescriptionID] = pd.[ProductDescriptionID]
WHERE p.ProductID =994
OPTION(RECOMPILE)
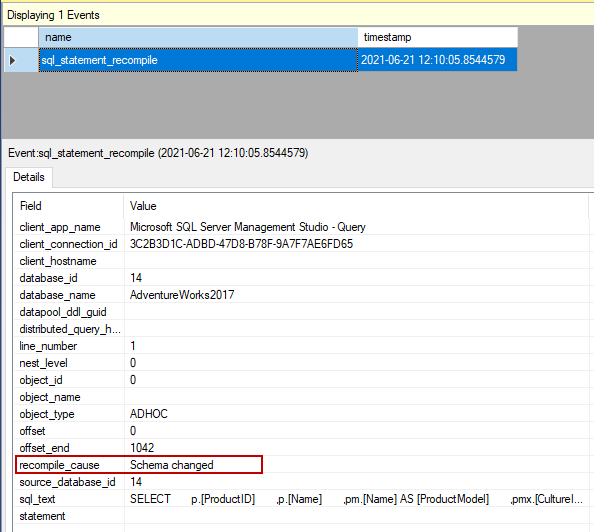
当我们查看创建的扩展事件时,它将捕捉到查询的重新编译以及导致重新编译的原因。

同时,SQL Profiler会在查询执行后显示一份报告,其中包括查询重新编译的原因。

模式的改变和查询的重新编译
有时,我们需要改变数据库中的表的设计。如我们可以添加新的列或改变现有列的数据类型。同时,我们可以创建、改变或删除表的索引。这些类型的变化将导致查询的重新编译。例如,我们将改变ProductDescription表的Description列的数据类型,然后重新执行查询。
ALTER TABLE Production.ProductDescription
ALTER COLUMN Description nvarchar(600);
GO
SELECT
p.[ProductID]
,p.[Name]
,pm.[Name] AS [ProductModel]
,pmx.[CultureID]
,pd.[Description]
FROM [Production].[Product] p
INNER JOIN [Production].[ProductModel] pm
ON p.[ProductModelID] = pm.[ProductModelID]
INNER JOIN [Production].[ProductModelProductDescriptionCulture] pmx
ON pm.[ProductModelID] = pmx.[ProductModelID]
INNER JOIN [Production].[ProductDescription] pd
ON pmx.[ProductDescriptionID] = pd.[ProductDescriptionID]
WHERE p.ProductID =994
我们可以看到,由于列数据类型的改变操作,发生了查询的重新编译。
索引的重建和查询的重新编译
索引是非常特殊的数据库对象,它们有助于从数据库中快速地检索数据。因为这个特点,它们提高了查询性能。然而,数据的修改可能会破坏索引的逻辑顺序。在这种类型的碎片中,新页面的顺序与物理顺序不一样,所以会出现逻辑碎片。为了解决这个问题,我们可以重建索引页的逻辑顺序。通过下面的查询,我们可以重建Product表的所有索引。
ALTER INDEX ALL ON Production.Product REBUILD
当我们在索引重建操作后重新执行示例查询时,我们将看到由于模式改变的原因,查询优化器将重新编译该查询。
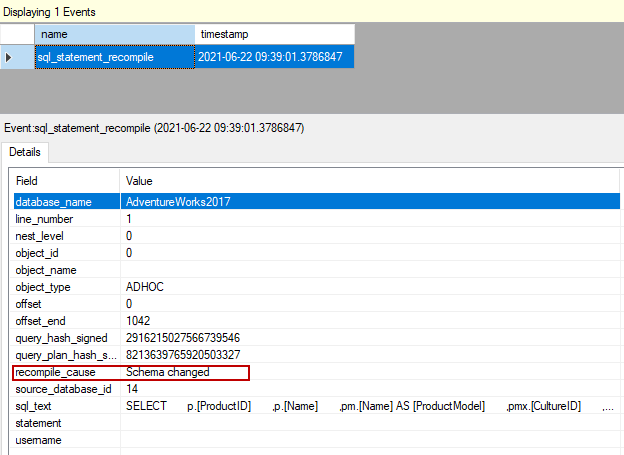
SQL Server统计和查询的重新编译
SQL Server统计数据在查询性能中起着关键作用,因为查询优化器使用统计数据来估计一个查询将返回多少行。如果我们启用数据库的自动创建统计数据选项,查询优化器可以在查询执行期间为单个列创建统计数据。在创建统计信息后,查询优化器会重新编译已执行的查询,假设会有更多最新的统计信息数据。现在让我们通过一个例子更深入地学习这个概念。首先,我们将创建一个表,然后执行一个非常基本的查询。
CREATE TABLE TestNewProduction
(PID INT PRIMARY KEY IDENTITY(1,1),PModelID INT,
Name VARCHAR(50),ProductNumber VARCHAR(50),SafetyStockLevel INT ,ReorderPoint INT)
在执行这个查询后,SQL Server将其执行计划存储到计划缓存中。
SELECT P.Name FROM TestNewProduction P
INNER JOIN Production.ProductModel PM
ON P.PModelID= PM.ProductModelID
WHERE P.Name LIKE 'A%'
现在,我们将向TestNewProduction表插入一些行。
INSERT INTO TestNewProduction ( Name,PModelID,ProductNumber,SafetyStockLevel,ReorderPoint)
SELECT TOP 100 Name,ProductModelID,ProductNumber,SafetyStockLevel,ReorderPoint FROM Production.Product
WHERE ProductModelID IS NOT NULL
作为最后一步,我们将再次执行示例查询。在这种情况下,查询优化器将决定为Name列创建新的统计数据并重新编译查询。
SELECT P.Name FROM TestNewProduction P
INNER JOIN Production.ProductModel PM
ON P.PModelID= PM.ProductModelID
WHERE P.Name LIKE 'A%'
扩展事件捕获了查询优化器的重新编译事件,并显示了重新编译的原因。
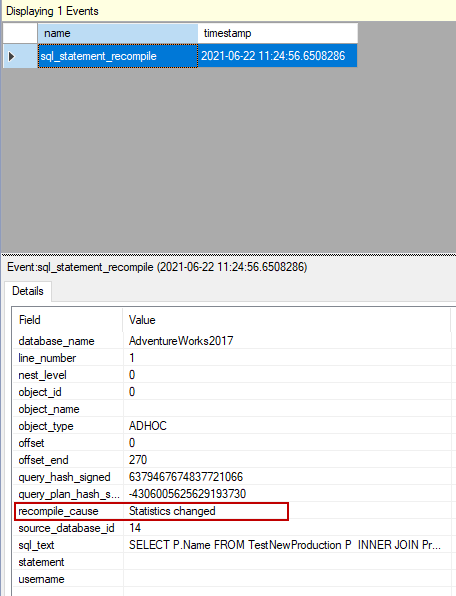
另一方面,SQL Profiler更清楚地显示所有事件,它可以为查询性能指标提供更多的数据。

在执行查询后,会进行以下步骤。
- 查询优化器由于统计信息改变的原因而重新编译该查询
- 为Name列创建一个新的统计数据,因为该列被用于where条件中
- 为PModelID列创建一个新的统计量,因为该列在连接语句中被使用。
- 最后,查询完成
正如我们在这个场景中看到的,解决查询性能问题需要了解查询优化器的行为影响。
关于统计的另一点是,数据的修改会导致统计变得陈旧。SQL Server统计学将数据分布存储在直方图中,但在数据修改后,直方图数据会变得过时。手动或自动更新统计数据会引起查询的重新编译。例如,让我们向TestNewProduction表添加500条新行,了解这种情况是如何发生的。
INSERT INTO TestNewProduction ( Name,PModelID,ProductNumber,SafetyStockLevel,ReorderPoint)
SELECT TOP 100 Name,ProductModelID,ProductNumber,SafetyStockLevel,ReorderPoint FROM Production.Product
WHERE ProductModelID IS NOT NULL
GO 5
为了捕获自动更新的统计事件,我们需要在我们的扩展事件中做一些修改,因此我们可以很容易地观察到幕后发生的事情。auto_stats事件可以捕捉到列统计事件的自动更新发生的时间。
DROP EVENT SESSION [CaptureQuery_Recompilations] ON SERVER
GO
CREATE EVENT SESSION [CaptureQuery_Recompilations] ON SERVER
ADD EVENT sqlserver.auto_stats,
ADD EVENT sqlserver.sql_statement_recompile(
ACTION(sqlserver.database_name,sqlserver.query_hash_signed,sqlserver.query_plan_hash_signed,sqlserver.sql_text,sqlserver.username))
ADD TARGET package0.ring_buffer
WITH (STARTUP_STATE=ON)
GO
在重新创建了扩展事件后,我们将再次执行我们的示例查询,并检查捕获的事件。
SELECT P.Name FROM TestNewProduction P
INNER JOIN Production.ProductModel PM
ON P.PModelID= PM.ProductModelID
WHERE P.Name LIKE 'A%'
从图片中可以看出,正如我们所期望的那样,扩展的事件已经捕获了一个查询重新编译的事件。
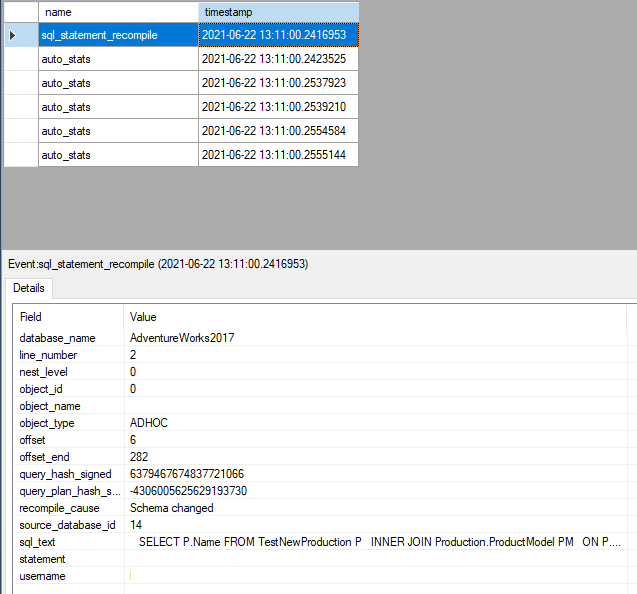
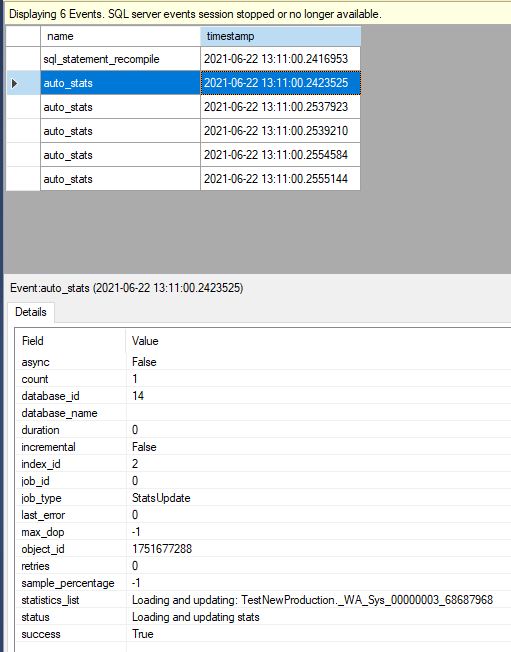
auto_stats表示与统计有关的事件。当我们点击第一个事件时,我们可以看到关于这个事件的所有细节。
SET选项和查询重新编译
SET选项使我们能够改变SQL Server的会话级行为,因此我们可以通过这些选项来修改各种选项。关于SET选项的另一个要点是可能导致查询重新编译。如,SQL Server Management Studio(SSMS)和应用程序的连接选项可能不同,它会导致不同的执行计划。例如,如果我们改变ARITHABORT和NUMERIC_ROUNDABORT连接选项,查询优化器将决定重新编译查询。
SET ARITHABORT ON
SET NUMERIC_ROUNDABORT OFF
SELECT P.Name FROM TestNewProduction P
INNER JOIN Production.ProductModel PM
ON P.PModelID= PM.ProductModelID
WHERE P.Name LIKE 'A%'
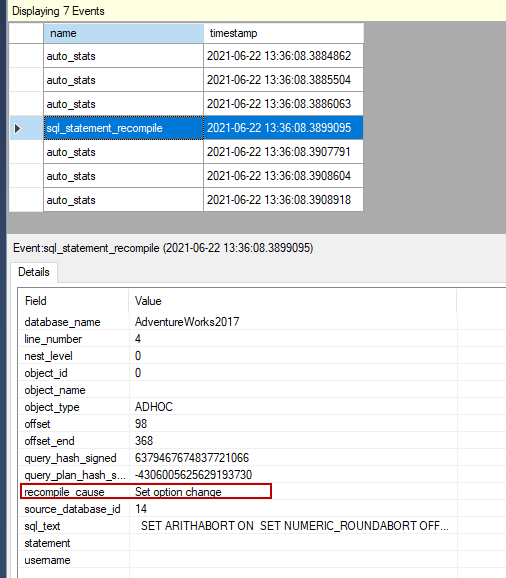
扩展事件向我们显示了重新编译的原因,很明显,设置选项的改变会导致查询的重新编译。
结论
在这篇文章中,我们已经探讨了哪些原因会导致查询重新编译,以及它们与查询性能的相互作用。同时,我们也了解了如何用不同的两种方法来监控查询的重新编译事件。
