深入浅出 HBase 实战 | 青训营笔记
这是我参与「第四届青训营 」笔记创作活动的的第8天
使用场景
开源的NoSQL分布式数据库,对稀疏表提供了更高的存储空间使用率和读写效率。CP系统。 存储层基于HDFS存储 计算层提供水平扩展、负载均衡、故障恢复
半结构化,无数据类型,以列族进行存储、支持TB、PB级数据
HBase数据类型
以列族组织数据,以行键索引数据。
- 列族需要在使用前预先创建,列名不需要预先声明,因此支持半结构化数据模型
- 支持保留多个版本的数据,(行键+列族+列名+版本号)定位一个具体的值
行键(rowkey):唯一索引一行的主键,字典序组织,一行可包含多个列族 列族(column family):一系列的列名,一个列族可以包含任意多个列名,每个列族数据物理上相互独立的存储,支持按列读取部分数据 列名(column name):定义一个具体的列,一个列名可以包含多个版本的数据,不需要预先定义列名 版本号(version):用于标识一个列内多个不同版本的数据,每个版本号对应一个值 值(value):存储的一个具体的值
主要数据结构
- HDFS目录结构
- MemStore:使用跳表(Skiplist)组织KeyValue数据,提供O(logN)的查询/插入/删除,支持双向遍历
- HFile:
- Scanned block section:顺序扫描HFile时所有的数据块将会被读取
- Non-scanned block section:扫描的过程中不会被读取
- load-on-open-section:region server启动时,需要加载到内存当中
- Trailer:记录HFile基本信息,各个部分的偏移值和寻址信息
- HFileblock:
- DataBlock:HBase中数据存储的最小文件单元,存储用户的KeyValue数据,是数据表示的最基础单位
- Block Index:索引分为单层和多层。
- 单层:root data index
- 多层:NonRoot index一般有intermediate和leaf两层,具有相同的结构。
场景:
适用场景:
- “近在线”的海量分布式KV/宽表存储,数据量级可以达到PB级以上
- 写密集型、高吞吐应用,可接受一定程度的时延抖动
- 字典序主键索引、批量顺序扫描多行数据的场景
- Hadoop大数据生态友好兼容
- 半结构化数据模型,行列稀疏的数据分布,动态增减列名
- 敏捷平滑的水平扩展能力,快速响应数据体量、流量变化
典型应用:
- 电商订单数据
- 搜索推荐引擎
- 广告数据流
- 用户交互数据
- 时序数据引擎:日志、监控(OpenTSDB)
- 图存储引擎:JanusGraph
- 大数据生态:高度融入Hadoop生态
半结构化/字典序有序索引的数据
HBase提供近在线读写的谁推荐候选数据集
查询模式:批量查询指定tenantID租户的指定channelID频道下的推荐候选集
例如:
start rowkey:"part1:tenant1:channel1",
end rowkey:"part1:tenant1:channel2",
- 对应数据:
- value:"features(e.g. sport,basketball,...)"
- column:"additional lables(e.g. region=CN,...)"
"近在线"海量分布式KV/宽表存储
商家订单系统使用HBase管理卖家、卖家的订单操作
生态
- Phoenix:提供SQL查询HBase里面的数据。一般能够在毫秒级别返回。
- Spark:Spark Streaming + HBase进行实时广告推荐
- HGraphDB:分布式图数据库,可以使用其进行图OLTP查询
- GeoMesa:目前基于NoSQL数据库的时空数据引擎中功能最丰富、社区贡献人数最多的开源系统。提供高效时空索引,支持点、线、面等空间要素存储,百亿级数据实现毫秒(ms)级响应;提供轨迹查询、区域分布统计、区域查询、密度分析、聚合、OD 分析等常用的时空分析功能;提供基于Spark SQL、REST、GeoJSON、OGC服务等多种操作方式,方便地理信息互操作
- OpenTSDB:可伸缩的时间序列数据库
- Solr:使用Solr建立二级索引/全文索引
功能
- Bulkload:大批量向HBase导入数据。使用MapReduce任务直接生成底层存储的HFile文件,并移动到HBase存储目录下。
- Coprocessor:接口框架,给HBase原生接口添加类似lifecycle hook函数的能力
- Filter:将过滤逻辑下推到HBase服务端
- MOB:Medium Object Storage解决HBase对中等大小对象的低延迟读写支持
- Snapshot:数据备份
- Replication:将HBase集群中的数据复制到目标HBase集群
架构设计
-
主要组件:
- HMaster:元数据管理,集群调度,保活。通常部署一个主节点和一到多个备节点,通过Zookeeper选主。
- RegionServer:提供数据读写服务,每个实例负责若干个互不重叠的rowkey区间内的数据。
- ThriftServer:提供Thrift协议访问数据的代理层
-
依赖组件:
- Zookeeper:分布式一致共识协作管理,HMaster选主,任务分发,元数据变更管理等
- HDFS:数据存储
HMaster
- CatalogJanitor:定期扫描元数据hbase:meta的变化,回收无用的region
- AssignmentManager:管理region分配,processAssignQueue方法每当pendingAssignQueue放满RegionStateNode时批量处理。单独启动daemon线程循环处理。
Master故障恢复:故障恢复流程即从master实例从ZK监听到主master节点掉了,抢主成功后执行启动流程。
RegionServer故障恢复:regionserver每次启动的startcode不同,都视为一个新的rs实例,因此走一遍启动流程。
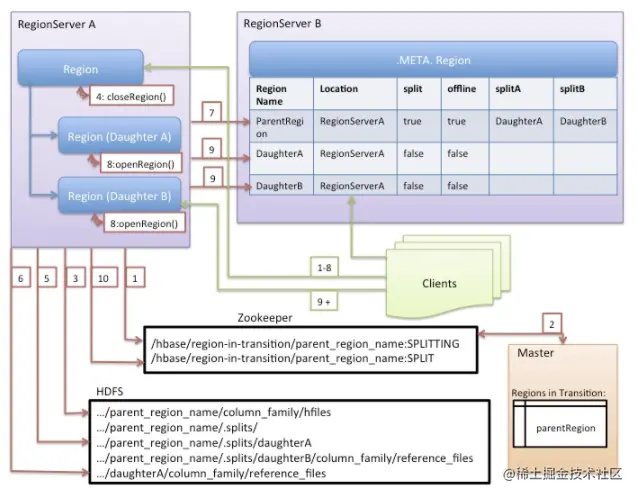
Region Split 热点切分
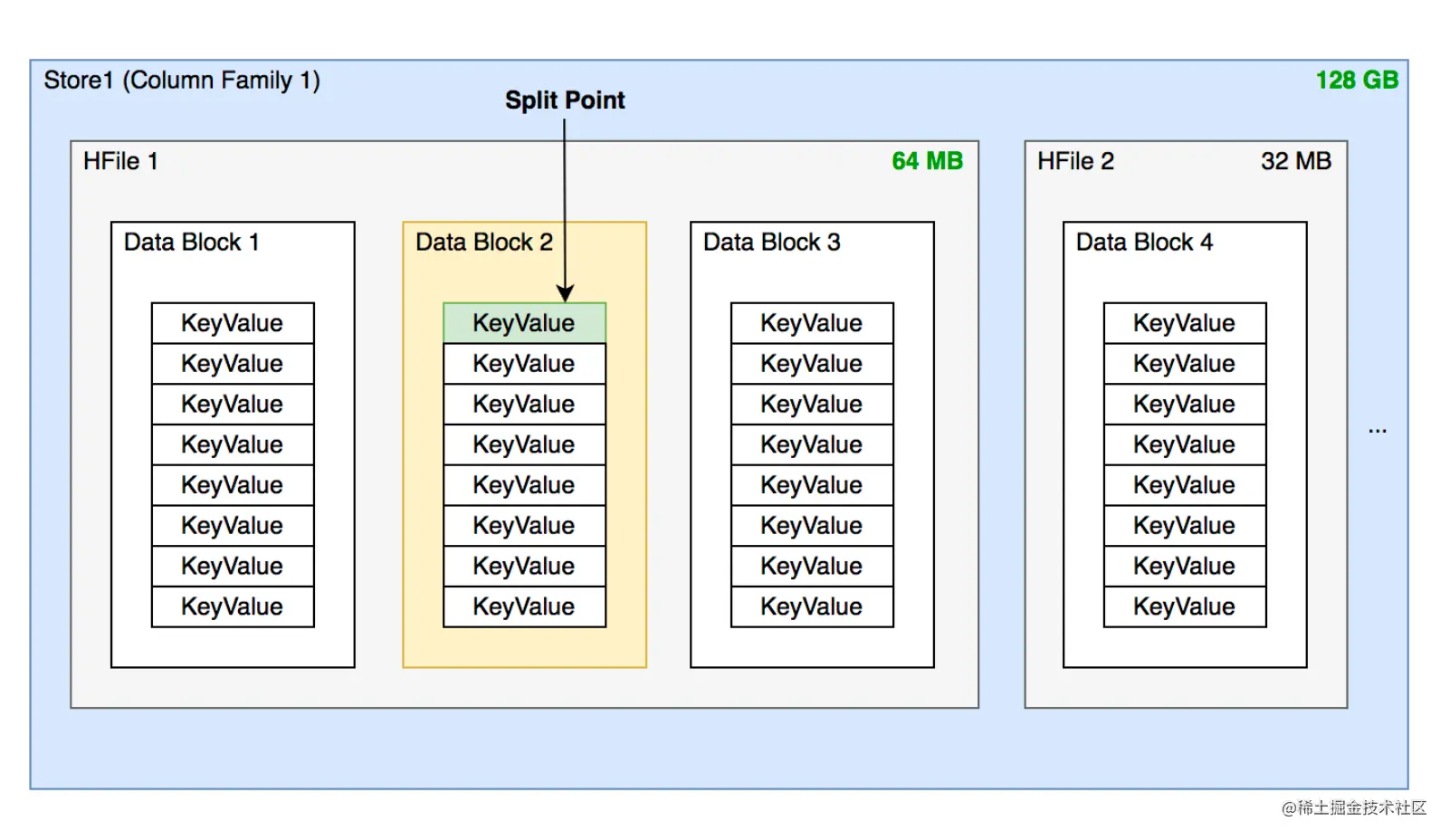
- 找到切分点:整个region中最大store中的最大HFile文件中最中心的一个block的首个rowkey
- 
- HBase将整个切分过程包装成了一个事务,意图能够保证切分事务的原子性。整个分裂事务过程分为三个阶段:prepare – execute – (rollback)
- prepare阶段:在内存中初始化两个子region,具体是生成两个HRegionInfo对象,包含tableName、regionName、startkey、endkey等。同时会生成一个transaction journal,这个对象用来记录切分的进展
- execute阶段
-