从浏览器输入到显示-浏览器篇
进程与线程
- 进程是操作系统资源分配的基本单位,进程中包含线程。
- 线程是由进程所管理的。为了提升浏览器的稳定性和安全性,浏览器采用了多进程模型。
- 一个线程崩了 整个进程就崩了 但是进程不会影响别的进程
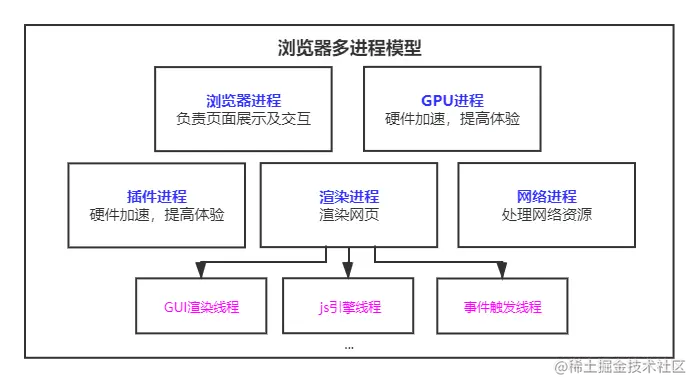
- 浏览器进程:负责界面显示、用户交互、子进程管理,提供存储等。
- 渲染进程:每个也卡都有单独的渲染进程,核心用于渲染页面。
- 网络进程:主要处理网络资源加载(HTML、CSS,、JS等)
- GPU进程:3d绘制,提高性能
- 插件进程: chrome中安装的一些插件
浏览器执行顺序
- 渲染进程把HTML转变为DOM树型结构
- 浏览器中的HTML解析器可以把HTML字符串转换成DOM结构
- HTML解析器边接收网络数据边解析HTML
- 解析DOM
- HTML字符串转Token
- Token栈用来维护节点之间的父子关系,Token会依次压入栈中
- 如果是开始标签,把Token压入栈中并且创建新的DOM节点并添加到父节点的children中
- 如果是文本Token,则把文本节点添加到栈顶元素的children中,文本Token不需要入栈
- 如果是结束标签,此开始标签出栈
- 渲染进程把CSS文本转为浏览器中的stylesheet
- 渲染进程把CSS文本转为浏览器中的stylesheet
- CSS来源可能有link标签、style标签和style行内样式
- 渲染引擎会把CSS转换为document.styleSheets
- 通过stylesheet计算出DOM节点的样式
- 根据CSS的继承和层叠规则计算DOM节点的样式
- DOM节点的样式保存在了ComputedStyle中
- 根据DOM树创建布局树
- 并计算各个元素的布局信息
- 根据布局树生成分层树
- 根据布局树生成分层树
- 渲染引擎需要为某些节点生成单独的图层,并组合成图层树
- z-index
- 绝对定位和固定定位
- 滤镜
- 透明
- 裁剪
- 这些图层合成最终的页面
- 根据分层树进行生成绘制步骤
- 根据分层树进行生成绘制步骤复合图层
- 每个图层会拆分成多个绘制指令,这些指令组合在一起成为绘制列表
- 把绘制步骤交给渲染进程中的合成线程进行合成
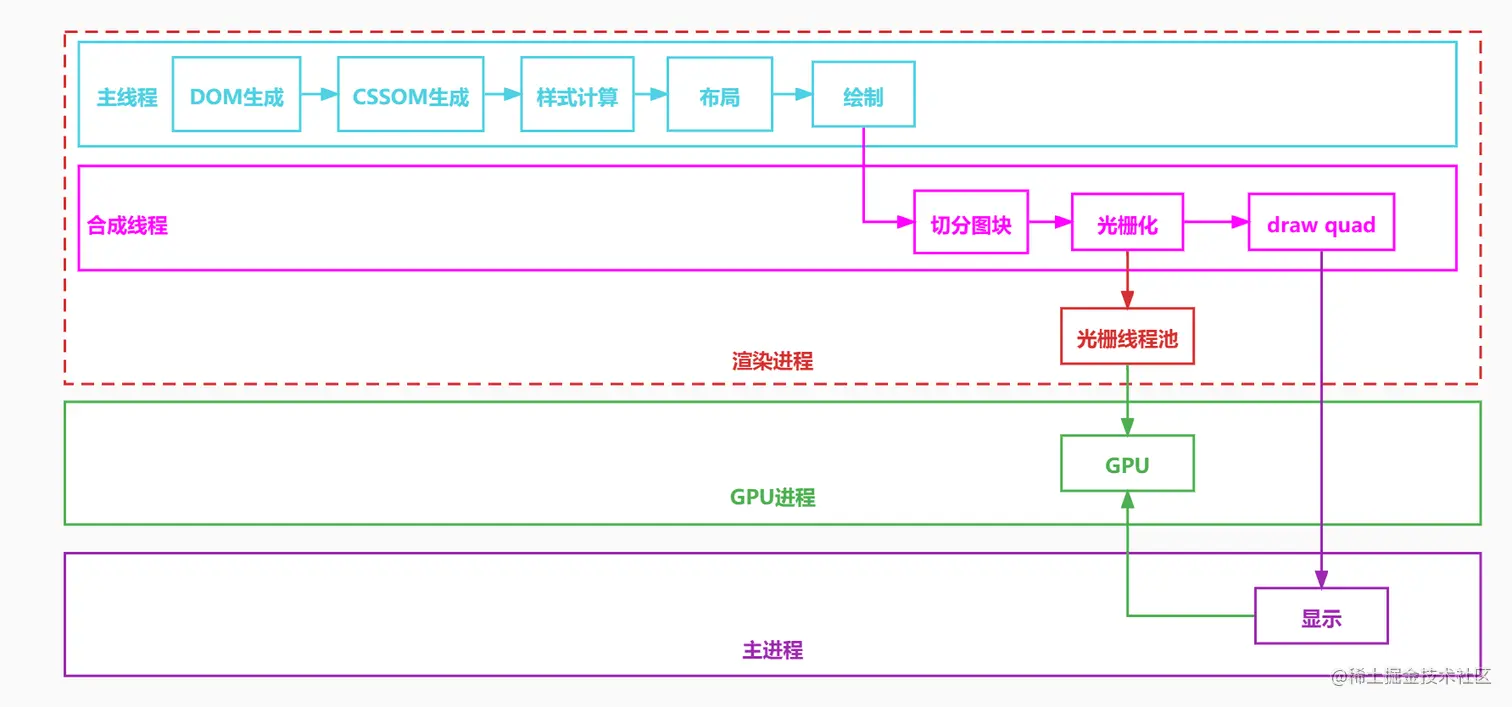
- 合成线程将图层分成图块(tile)
- 图块渲染也称基于瓦片渲染或基于小方块渲染
- 它是一种通过规则的网格细分计算机图形图像并分别渲染图块(tile)各部分的过程
- 合成线程会把分好的图块发给栅格化线程池,栅格化线程会把图片(tile)转化为位图
- 栅格化是将矢量图形格式表示的图像转换成位图以用于显示器输出的过程
- 栅格即像素
- 栅格化即将矢量图形转化为位图(栅格图像)
- 而其实栅格化线程在工作的时候会把栅格化的工作交给GPU进程来完成,最终生成的位图就保存在了GPU内存中
- 当所有的图块都光栅化之后合成线程会发送绘制图块的命令给浏览器主进程
- 浏览器主进程然后会从GPU内存中取出位图显示到页面上
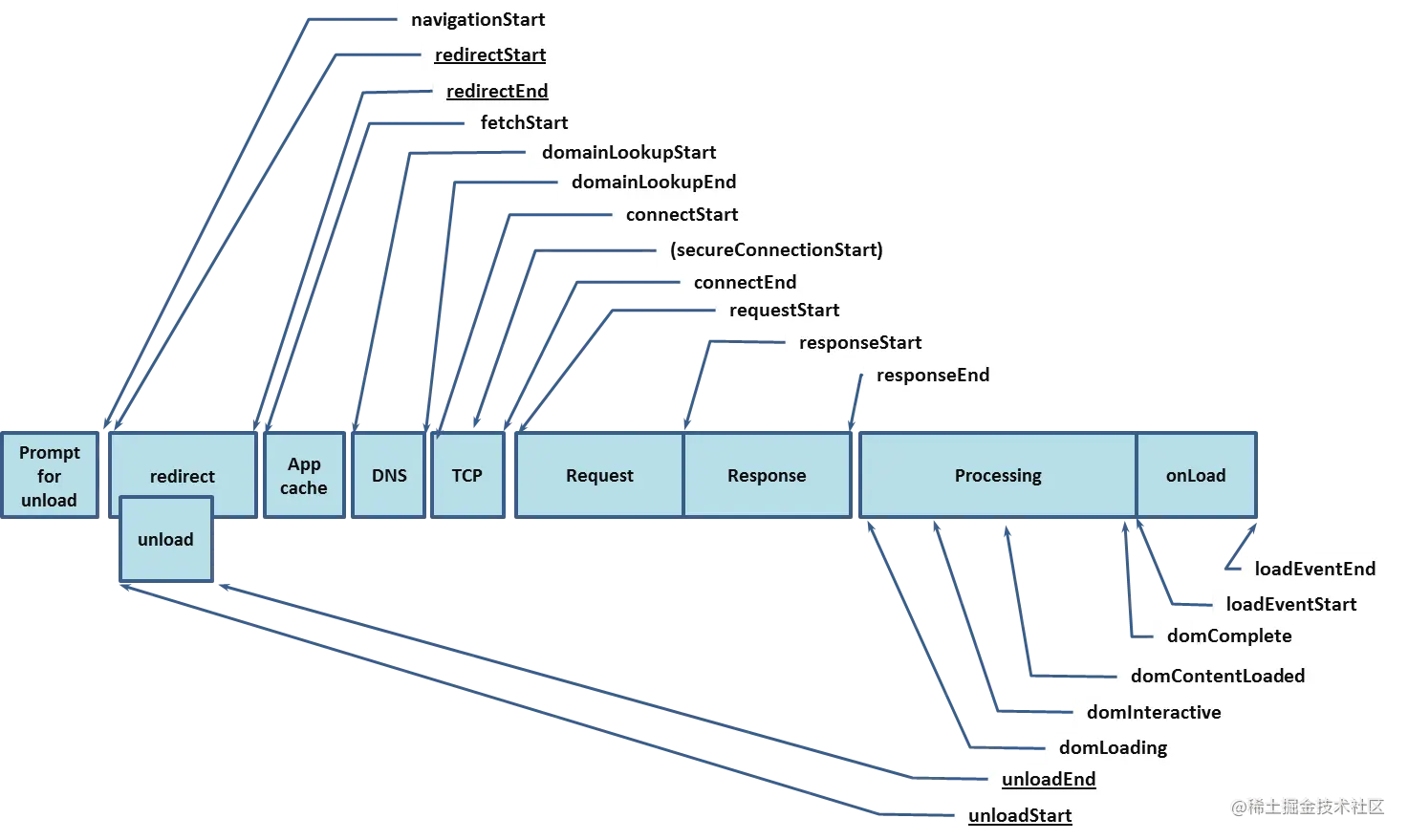
network Timing的参数说明
- Queuing: 请求发送前会根据优先级进行排队,同时每个域名最多处理6个TCP链接,超过的也会进行排队,并且分配磁盘空间时也会消耗一定时间。
- Stalled :请求发出前的等待时间(处理代理,链接复用)
- DNS lookup :查找DNS的时间
- initial Connection :建立TCP链接时间
- SSL: SSL握手时间(SSL协商)
- Request Sent :请求发送时间(可忽略)
- Waiting(TTFB) :等待响应的时间,等待返回首个字符的时间
- Content Dowloaded :用于下载响应的时间
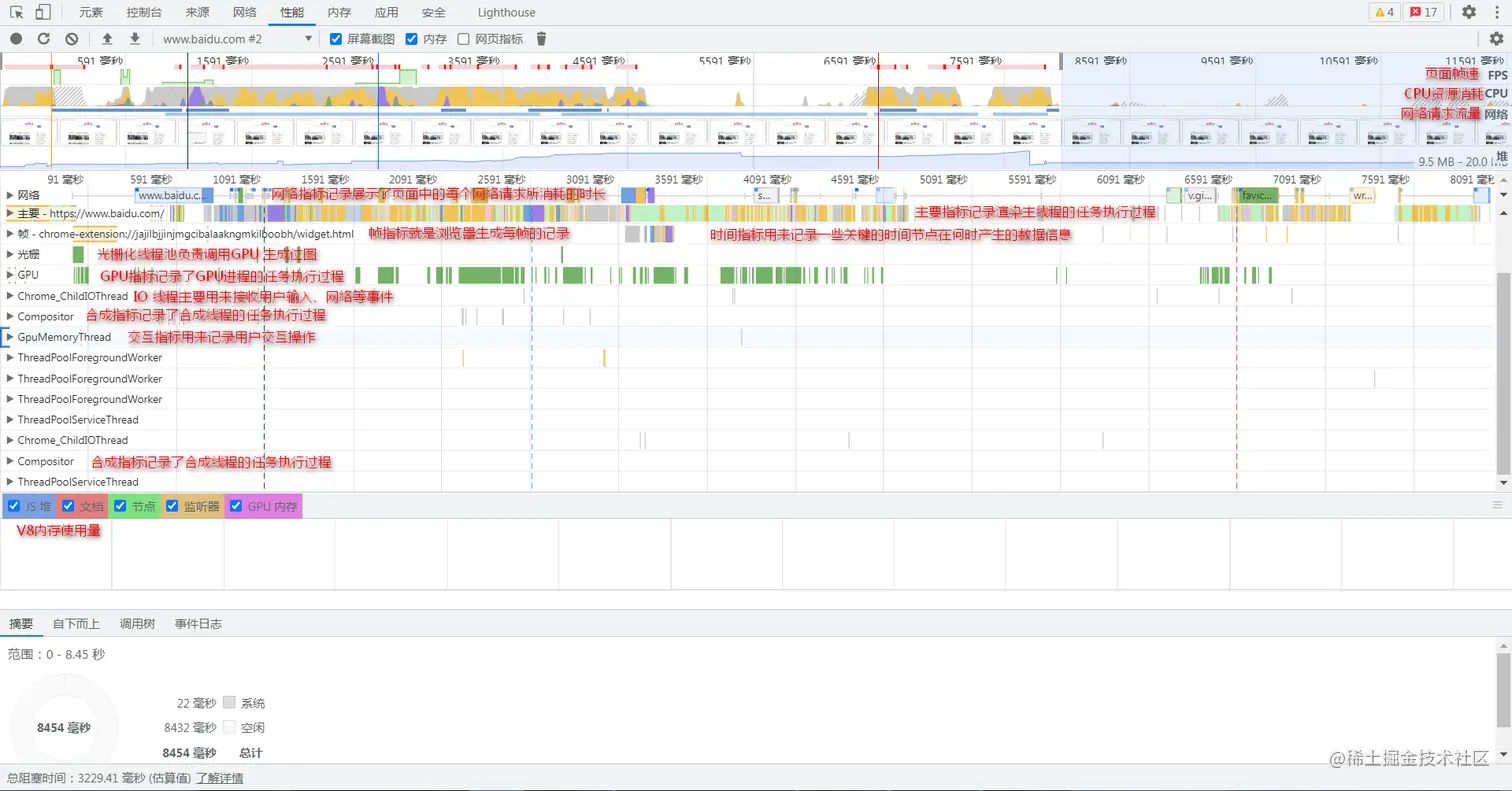
network Perfomance 性能
- 面板说明
- 核心流程
- 导航阶段
- beforeunload 事件触发于 window、document 和它们的资源即将卸载时
- navigationstart 相同的浏览环境下卸载前一个文档结束之时
- pagehide 当浏览器在显示与会话历史记录不同的页面的过程中隐藏当前页面时, pagehide(页面隐藏)事件会被发送到一个Window
- visibilitychange 当浏览器的某个标签页切换到后台,或从后台切换到前台时就会触发该消息
- unload 当文档或一个子资源正在被卸载时, 触发 unload事件
- unloadEventEnd 事件处理程序结束之时
- send request 发送请求
- receive data 接收响应
- commitNavigationEnd 提交本次导航结束
- domLoading 解析器开始工作时
- 解析HTML阶段
- receive data 接收数据
- complete loading 完成加载
- parseHTML 解析HTML
- recalculateStyle 重新计算样式
- layout 布局
- update layer tree 更新图层树
- paint 绘制
- raster GPU光栅化
- compositor 复合图层
- display 显示
- dominteractive 主文档的解析器结束工作时
- readystatechange interactive(可交互)
- domContentLoadedEventStart 所有的需要被运行的脚本已经被解析之时
- DOMContentLoaded 当初始的 HTML 文档被完全加载和解析完成之后,DOMContentLoaded 事件被触发,而无需等待样式表、图像和子框架的完全加载
- domContentLoadedEventEnd 这个时刻为所有需要尽早执行的脚本不管是否按顺序,都已经执行完毕
- domComplete 主文档的解析器结束工作
- readystatechange complete(完成)
- loadEventStart load事件被现在的文档触发之时
- load 当整个页面及所有依赖资源如样式表和图片都已完成加载时,将触发load事件
- loadEventEnd load事件处理程序被终止
- pageshow 当一条会话历史记录被执行的时候将会触发页面显示(pageshow)事件
network memory 内存
- 可查看必要 内存泄露等一系列问题
- 内存快照字段说明
- 摘要 按构造函数进行分组,捕获对象和其使用内存的情况
- 对比 对比某个操作前后的内存快照区别
- 控制 查看堆的具体内容,可以用来查看对象结构
- 统计信息 统计视图
- 距离 显示通过最短的节点路径到根节点的距离,引用层级
- 浅层大小 显示对象所占内存,不包含内部引用的其他对象所占的内存
- 保留的大小 显示对象所占的总内存,包含内部引用的其他对象所占的内存
network layers
优化策略
- 减少HTTP请求数,合并JS、CSS,合理内嵌CSS、JS
- 合理设置服务端缓存,提高服务器处理速度。 (强制缓存、对比缓存)
- 避免重定向,重定向会降低响应速度 (301,302)
- 使用dns-prefetch,进行DNS预解析
- 采用域名分片技术,将资源放到不同的域名下。接触同一个域名最多处理6个TCP链接问题。
- 采用CDN加速加快访问速度。(指派最近、高度可用)
- gzip压缩优化 对传输资源进行体积压缩 (html,js,css)
- 加载数据优先级 : preload(预先请求当前页面需要的资源) prefetch(将来页面中使用的资源) 将数据缓存到HTTP缓存中
回流和重绘的优化点
- JavaScript强制将计算样式和布局操作提前到当前的任务中 app.offsetHeight 调用就会强制提前
- 脱离文档流
- 渲染时给图片增加固定宽高
- 尽量使用css3 动画
- 可以使用will-change提取到单独的图层中
静态文件优化
- 图片优化
- 图片格式
- jpg:适合色彩丰富的照片、banner图;不适合图形文字、图标(纹理边缘有锯齿),不支持透明度
- png:适合纯色、透明、图标,支持半透明;不适合色彩丰富图片,因为无损存储会导致存储体积大
- gif:适合动画,可以动的图标;不支持半透明,不适和存储彩色图片
- webp:适合半透明图片,可以保证图片质量和较小的体积
- svg格式图片:相比于jpg和jpg它的体积更小,渲染成本过高,适合小且色彩单一的图标;
- 避免空的src
- 减小图片尺寸,节约用户流量
- img标签设置alt属性 提高图片加载失败的用户体验
- 原生的loading:lazy 图片懒加载
- 不同环境下,加载不同尺寸和像素的图片 sizes属性
- 对于较大的图片可以考虑采用渐进式图片
- 采用base64URL减少图片请求
- 采用雪碧图合并图标图片等
- HTML优化
- 语义化
- 减少HTML嵌套关系、减少DOM节点数量
- 删除多余空格、空行、注释、及无用的属性等
- HTML减少iframes使用 (iframe会阻塞onload事件可以动态加载iframe)
- 避免使用table布局
- css优化
- 减少伪类选择器、减少样式层数、减少使用通配符
- 避免使用CSS表达式,CSS表达式会频繁求值, 当滚动页面,或者移动鼠标时都会重新计算
- 删除空行、注释、减少无意义的单位、css进行压缩
- 使用外链css,可以对CSS进行缓存
- 添加媒体字段,只加载有效的css文件
- CSS contain属性,将元素进行隔离
- 减少@import使用,由于@import采用的是串行加载
- js优化
- 通过async、defer异步加载文件
- 减少DOM操作,缓存访问过的元素
- 操作不直接应用到DOM上,而应用到虚拟DOM上。最后一次性的应用到DOM上。
- 使用webworker解决程序阻塞问题
- IntersectionObserver
- 虚拟滚动 vertual-scroll-list
- requestAnimationFrame、requestIdleCallback

- 尽量避免使用eval, 消耗时间久
- 使用事件委托,减少事件绑定个数。
- 尽量使用canvas动画、CSS动画
浏览器存储
- cookie
- cookie过期时间内一直有效,存储大小4k左右、同时限制字段个数,不适合大量的数据存储,每次请求会携带cookie,主要可以利用做身份检查。
- 设置cookie有效期
- 根据不同子域划分cookie较少传输
- 静态资源域名和cookie域名采用不同域名,避免静态资源访问时携带cookie
- localStorage
- chrome下最大存储5M, 除非手动清除,否则一直存在。利用localStorage存储静态资源
- sessionStorage
- indexDB
PWA
- webapp用户体验差(不能离线访问),用户粘性低(无法保存入口),pwa就是为了解决这一系列问题,让webapp具有快速,可靠,安全等特点
- Web App Manifest:将网站添加到桌面、更类似native的体验
- Service Worker:离线缓存内容,配合cache API
- Push Api & Notification Api: 消息推送与提醒
- App Shell & App Skeleton App壳、骨架屏
lightHouse优化
- 减少未使用的 JavaScript
- 推迟加载屏幕外图片
- 移除阻塞渲染的资源
- 资源阻止了系统对您网页的首次渲染。建议以内嵌方式提供关键的 JS/CSS,并推迟提供所有非关键的 JS/样式
- 减少未使用的 CSS
- 使用视频格式提供动画内容
- 使用大型 GIF 提供动画内容会导致效率低下。建议您改用 MPEG4/WebM 视频(来提供动画)和 PNG/WebP(来提供静态图片)以减少网络活动消耗的字节数
- 应避免向新型浏览器提供旧版JavaScript
- Polyfill 和 transform 让旧版浏览器能够使用新的 JavaScript 功能。不过,其中的很多函数对新型浏览器而言并非必需。对于打包的 JavaScript,请采用现代脚本部署策略,以便利用 module/nomodule 功能检测机制来减少传送到新型浏览器的代码量,同时保留对旧版浏览器的支持
- 未使用被动式监听器来提高滚动性能
- 建议您将触摸和滚轮事件监听器标记为 passive,以提高页面的滚动性能,passive不会对事件的默认行为说 no
- unload事件监听器改用pagehide或visibilitychange事件
- unload事件不会可靠地触发,而且监听该事件可能会妨碍系统实施“往返缓存”之类的浏览器优化策略
- 请移除 JavaScript 软件包中的重复模块
V8
计算机模型

- 寄存器
- 是中央处理器的组成部分
- 寄存器是有限存储容量的高速存储部件
- 可以用来暂存指令、数据和地址
- 寄存器内的数据可用于执行算术和逻辑运算
- 寄存器内的地址可用于指向内存的某个位置
- 内存
- 随机存取存储器(Random Access Memory)也叫内存,英文缩写RAM
- RAM是与CPU直接交换数据的内部存储器
- RAM工作时可以从任何一个指定地址写入或读出信息
- RAM用来在计算机中用来暂时存储程序、数据和中间结果
- 内存空间
- 数据空间 存储数据
- 指令空间 存储执行命令 0101等二进制
- 机器语言指令
- 计算机只认识0和1,所以我们可以通过二进制指令和计算机进行沟通
- 这些指令被称为指令集,也就是机器语言
- MIPS是一种采取精简指令集(RISC)的处理器架构
- 最常见的MIPS-32位指令集每个指令是一个32位的二进制数
- 汇编指令
- 由于机器语音没有可读性 就产生了汇编语言
- 汇编执行的大致命令种类分为
- opcode 操作码
- rs 第一个来源寄存器
- rt 第二个来源寄存器
- rd 目标寄存器
- shamt 位移量
- funct 函数,这个字段选择opcode操作某个特定字体
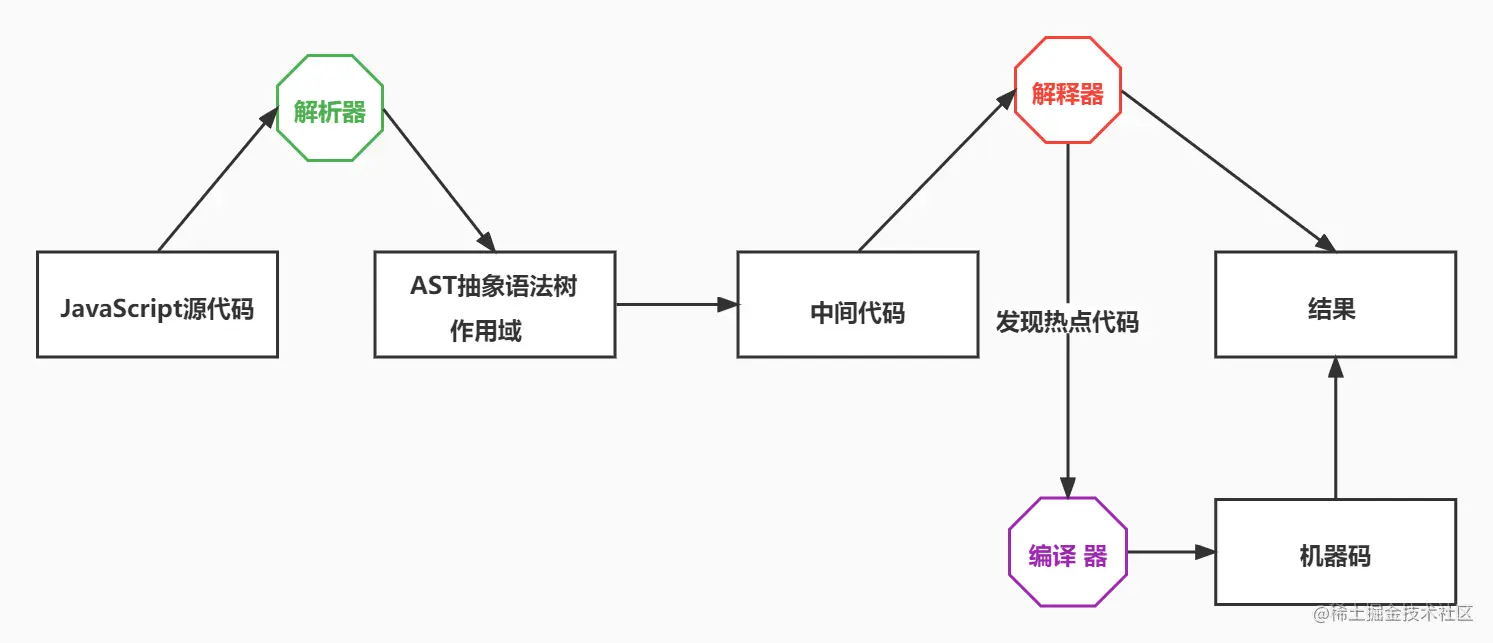
编译语言分类
- 解释执行
- 先将源代码通过解析器转成中间代码,再用解释器执行中间代码,输出结果
- 启动快,执行慢
- 编译执行
- 先将源代码通过解析器转成中间代码,再用编译器把中间代码转成机器码,最后执行机器码,输出结果
- 启动慢,执行快
V8执行过程
- V8采用的是解释和编译两种方式,这种混合使用的方式称为JIT技术
- 第一步先由解析器生成抽象语法树(AST)和相关的作用域(scope)
- 第二步根据AST和作用域生成字节码,字节码是介于AST和机器码的中间代码
- 然后由解释器直接执行字节码,也可以让编译器把字节码编译成机器码后再执行
- v8的开发工具shell d8
v8内存
- 程序运行需要分配内存
- V8也会申请内存,申请的内存又会分为堆内存和栈内存
栈内存
- 栈用于存放JS中的基本类型和引用类型指针
- 栈的空间是连续的,增加删除只需要移动指针,操作速度非常快
- 栈的空间是有限的,当栈满了,就会抛出一个错误
- 栈一般是在执行函数时创建的,在函数执行完毕后,栈就会被销毁
堆内存
- 内存分类
- 新生代 new space
- 老生代 old space
- 用于存放一些生命周期比较长的对象数据
- new space的对象进行两个周期的垃圾回收后,如果数据还存在new space中,则将他们存放到old space中 或者 new space空间被占用25%以上也会直接到old space
- old space又可以分为两部分,分别是Old pointer space和Old data space
- Old pointer space 存放GC后surviving的指针对象
- Old data space 存放GC后surviving的数据对象
- Old Space使用标记清除和标记整理的方式进行垃圾回收
- 大对象空间 Large object space
- 为了避免大对象的拷贝,使用该空间专门存储大对象
- GC 不会回收这部分内存
- map空间 map space
- 存放对象的Map信息,即隐藏类
- 隐藏类是为了提升对象属性的访问速度的
- V8 会为每个对象创建一个隐藏类,记录了对象的属性布局,包括所有的属性和偏移量
- 运行时代码空间 code space
- 用于存放JIT已编译的代码
- 唯一拥有执行权限的内存
- 新生代的垃圾回收机制
- 新生代内存有两个区域,分别是对象区域(from) 和 空闲区域(to)
- 使用Scavenger算法
- 广度优先遍历原则
- 广度优先遍历 From-Space 中的对象,从根对象出发,广度优先遍历所有能到达的对象,把存活的对象复制到 To-Space
- 遍历完成后,清空 From-Space
- From-Space 和 To-Space 角色互换 类似于fiber的双缓冲机制
- 不会产生文档碎片 ,但是会造成空间浪费
- 优化点
- 并行执行
- 新生代的垃圾回收采取并行策略提升垃圾回收速度,它会开启多个辅助线程来执行新生代的垃圾回收工作
- 并行执行需要的时间等于所有的辅助线程时间的总和加上管理的时间
- 并行执行的时候也是全停顿的状态,主线程不能进行任何操作,只能等待辅助线程的完成
- 这个主要应用于新生代的垃圾回收
- 老生代的垃圾回收
- 深度优先遍历原则
- 老生代里的对象有些是从新生代晋升过来的,有些是比较大的对象直接分配到老生代里的,所以老生代的对象空间大,活的长
- 如果使用Scavenge算法,浪费一半空间不说,复制如此大块的内存消耗时间将会相当长。所以Scavenge算法显然不适合
- V8在老生代中的垃圾回收策略采用Mark-Sweep(标记清除)和Mark-Compact(标记整理)相结合
- 标记清除
- 标记清除分为标记和清除两个阶段
- 在标记阶段需要遍历堆中的所有对象,并标记那些活着的对象,然后进入清除阶段。在清除阶段总,只清除没有被标记的对象
- V8采取的是黑色和白色来标记数据,垃圾收集之前,会把所有的数据设置为白色,用来标记所有的尚未标记的对象,然后会从GC根出发,以深度优先的方式把所有的能访问到的数据都标记为黑色,遍历结束后黑色的就是活的数据,白色的就是可以清理的垃圾数据
- 标记清除有一个问题就是进行一次标记清楚后,内存空间往往是不连续的,会出现很多的内存碎片。如果后续需要分配一个需要内存空间较多的对象时,如果所有的内存碎片都不够用,就会出现内存溢出的问题 为了解决这个问题 就有了标记整理
- 标记整理
- 标记整理正是为了解决标记清除所带来的内存碎片的问题
- 标记整理在标记清除的基础进行修改,将其的清除阶段变为紧缩极端
- 在整理的过程中,将活着的对象向内存区的一段移动,移动完成后直接清理掉边界外的内存
- 紧缩过程涉及对象的移动,所以效率并不是太好,但是能保证不会生成内存碎片,一般10次标记清理会伴随一次标记整理
- 优化
- 在执行垃圾回收算法期间,JS脚本需要暂停,这种叫Stop the world(全停顿)
- 如果回收时间过长,会引起卡顿
- 性能优化
- 把大任务拆分小任务,分步执行,类似fiber
- 将一些任务放在后台执行,不占用主线程
- 增量标记
- 老生代因为对象又大又多,所以垃圾回收的时间更长,采用增量标记的方式进行优化
- 增量标记就是把标记工作分成多个阶段,每个阶段都只标记一部分对象,和主线程的执行穿插进行
- 为了支持增量标记,V8必须可以支持垃圾回收的暂停和恢复,所以采用了黑白灰三色标记法
- 黑色表示这个节点被GC根引用到了,而且该节点的子节点都已经标记完成了
- 灰色表示这个节点被 GC根引用到了,但子节点还没被垃圾回收器标记处理,也表明目前正在处理这个节点
- 白色表示此节点还没未被垃圾回收器发现,如果在本轮遍历结束时还是白色,那么这块数据就会被收回
- 引入了灰色标记后,就可以通过判断有没有灰色节点来判断标记是否完成了,如果有灰色节点,下次恢复的应该从灰色节点继续执行
- Write-barrier(写屏障)
- 黑色指向白色节点的时候,就会触发写屏障,这个写屏障会把白色节点设置为灰色
- Lazy Sweeping(惰性清理)
- 当增量标记完成后,如果内存够用,先不清理,等JS代码执行完慢慢清理
- concurrent(并发回收) requestIdleCallback
- 其实增量标记和惰性清理并没有减少暂停的总时间
- 并发回收就是主线程在执行过程中,辅助线程可以在后台完成垃圾回收工作
- 标记操作全都由辅助线程完,清理操作由主线程和辅助线程配合完成
内存泄露
- 不合理的闭包
- 隐式全局变量
- 分离的DOM 删除了dom节点 但是节点的变量没有删除
- 定时器
- 事件监听器
- Map、Set对象
- console
性能优化点
- 少用全局变量
- 通过原型新增方法
- 尽量创建对象一次搞定
- V8会为每个对象分配一个隐藏类,如果对象结构发生改变就会重建隐藏类,结构相同的对象会共且隐藏类
- 隐藏类描述了对象的结构和属性偏移地址,可以加速查找属性的时间
- 优化指南
- 创建对象尽量保持属性顺序一致
- 尽量不要动态添加和删除属性
- 尽量保持参数结构稳定 参数数据类型一致
ECMA
ECMA5中文文档
可执行代码和执行环境
可执行的代码类型
- 一共有三种ECMA脚本可执行代码
- 全局代码 是指被作为 ECMA 脚本 程序 处理的源代码文本。一个特定 程序 的全局代码不包括作为 函数体 被解析的源代码文本。
- Eval代码 如果传递给 eval 内置函数的参数为一个字符串,该字符串将被作为 ECMA 脚本 程序 进行处理
- 函数代码 是指作为 函数体 被解析的源代码文本 同时还特指 以构造器方式调用 Function 内置对象 时所提供的源代码文本。一个 函数体 的 函数代码 不包括作为其嵌套函数的 函数体 被解析的源代码文本。
词法环境
- 词法环境 是一个用于定义特定变量和函数标识符在 ECMAScript 代码的词法嵌套结构上关联关系的规范类型
- 一个词法环境由一个环境记录项和可能为空的外部词法环境引用构成
- 通常词法环境会与特定的 ECMAScript 代码诸如 FunctionDeclaration,WithStatement 或者 TryStatement 的 Catch 块这样的语法结构相联系,且类似代码每次执行都会有一个新的语法环境被创建出来
- 环境记录项记录了在它的关联词法环境域内创建的标识符绑定情形。
- 外部词法环境引用用于表示词法环境的逻辑嵌套关系模型
- (内部)词法环境的外部引用是逻辑上包含内部词法环境的词法环境
- 外部词法环境自然也可能有多个内部词法环境
- 词法环境和环境记录项是纯粹的规范机制,而不需要 ECMAScript 的实现保持一致。ECMAScript 程序不可能直接访问或者更改这些值
环境记录项
- 在本标准中,共有 2 类环境记录项: 声明式环境记录项 和 对象式环境记录项
- 声明式环境记录项用于定义那些将 标识符 与语言值直接绑定的 ECMA 脚本语法元素,例如 函数定义 , 变量定义 以及 Catch 语句
- 对象式环境记录项用于定义那些将 标识符 与具体对象的属性绑定的 ECMA 脚本元素,例如 程序 以及 With 表达式
- 出于标准规范的目的,可以将环境记录项理解为面向对象中的一个简单继承结构,其中环境记录项是一个抽象类,它有 2 个具体实现类,分别为声明式环境记录项和对象式环境记录项
- 声明式环境记录项
- 每个声明式环境记录项都与一个包含变量和(或)函数声明的 ECMA 脚本的程序作用域相关联
- 声明式环境记录项用于绑定作用域内定义的一系列标识符
- 除了所有环境记录项都支持的可变绑定外,声明式环境记录项还提供不可变绑定
- 在不可变绑定中,一个标识符与它的值之间的关联关系建立之后,就无法改变
- 创建和初始化不可变绑定是两个独立的过程,因此类似的绑定可以处在已初始化阶段或者未初始化阶段
- 对象式环境记录项
- 每一个对象式环境记录项都有一个关联的对象,这个对象被称作 绑定对象
- 对象式环境记录项直接将一系列标识符与其绑定对象的属性名称建立一一对应关系
- 不符合IdentifierName 的属性名不会作为绑定的标识符使用
- 无论是对象自身的,还是继承的属性都会作为绑定,无论该属性的 [[Enumerable]] 特性的值是什么
- 由于对象的属性可以动态的增减,因此对象式环境记录项所绑定的标识符集合也会隐匿地变化,这是增减绑定对象的属性而产生的副作用
- 通过以上描述的副作用而建立的绑定,均被视为可变绑定,即使该绑定对应的属性的 Writable 特性的值为 false
- 对象式环境记录项没有不可变绑定
全局环境
- 全局环境 是一个唯一的词法环境 ,它在任何 ECMA 脚本的代码执行前创建
- 全局环境的 环境数据 是一个object-environment-record对象环境数据
- 该环境数据使用 全局对象作为 绑定对象
- 全局环境的 外部环境引用 为 null
- 在 ECMA 脚本的代码执行过程中,可能会向 全局对象 添加额外的属性,也可能修改其初始属性的值
- 全局对象
- 唯一的全局对象建立在控制进入任何执行环境之前
- 全局对象的标准内置属性拥有特性 {[[Writable]]: true, [[Enumerable]]: false, [[Configurable]]: true}
- 全局对象没有 [[Construct]] 内部属性 ; 全局对象不可能当做构造器用 new 运算符调用
- 全局对象没有 [[Call]] 内部属性,全局对象不可能当做函数来调用
- 全局对象的 [[Prototype]] 和 [[Class]] 内部属性值是依赖于实现的
- 除了本规范定义的属性之外,全局对象还可以拥有额外的宿主定义的属性 全局对象可包含一个值是全局对象自身的属性;例如,在 HTML 文档对象模型中全局对象的 window 属性是全局对象自身
执行环境
- 当控制器转入 ECMA 脚本的可执行代码时,控制器会进入一个执行环境
- 当前活动的多个执行环境在逻辑上形成一个栈结构
- 该逻辑栈的最顶层的执行环境称为当前运行的执行环境
- 任何时候,当控制器从当前运行的执行环境相关的可执行代码转入与该执行环境无关的可执行代码时,会创建一个新的执行环境
- 新建的这个执行环境会推入栈中,成为当前运行的执行环境
- 执行环境包含所有用于追踪与其相关的代码的执行进度的状态
- 每个执行环境中会包含以下内容
- 词法环境
- 指定一个词法环境对象,用于解析该执行环境内的代码创建的标识符引用
- 变量环境
- 指定一个词法环境对象,其环境数据用于保存由该执行环境内的代码通过变量表达式和函数表达式创建的绑定
- This绑定
- 指定该执行环境内的 ECMA 脚本代码中 this 关键字所关联的值
- 执行环境的词法环境和变量环境组件始终为 词法环境 对象
- 当创建一个执行环境时,其词法环境组件和变量环境组件最初是同一个值
- 在该执行环境相关联的代码的执行过程中,变量环境组件永远不变,而词法环境组件有可能改变
- 在本标准中,通常情况下,只有正在运行的执行环境(执行环境栈里的最顶层对象)会被算法直接修改
- 因此当遇到词法环境,变量环境和This 绑定这三个术语时,指的是正在运行的执行环境的对应组件
- 执行环境是一个纯粹的标准机制,并不代表任何ECMA脚本实现的工件。在ECMA脚本程序中是不可能访问到执行环境的
标识符解析
- 标识符解析是指使用正在运行的执行环境中的词法环境,通过一个 标识符 获得其对应的绑定的过程。在 ECMA 脚本代码执行过程中,PrimaryExpression : Identifier 这一语法产生式将按以下算法进行解释执行:
- 令 env 为正在运行的执行环境的 词法环境 。
- 如果正在解释执行的语法产生式处在 严格模式下的代码 中,则仅 strict 的值为 true,否则令 strict 的值为 false。
- 以 env,Identifier 和 strict 为参数,调用 GetIdentifierReference 函数,并返回调用的结果。
- 解释执行一个标识符得到的结果必定是 引用 类型的对象,且其引用名属性的值与 Identifier 字符串相等。
建立执行环境
- 解释执行 全局代码 或使用 eval 函数输入的代码会创建并进入一个新的执行环境
- 每次调用 ECMA 脚本代码定义的函数也会建立并进入一个新的执行环境,即便函数是自身递归调用的。
- 每一次 return 都会退出一个执行环境。抛出异常也可退出一个或多个执行环境。
- 当控制流进入一个执行环境时,会设置该执行环境的 this 绑定,定义变量环境和初始词法环境,并执行定义绑定初始化过程,以上这些步骤的严格执行方式由进入的代码的类型决定。
进入全局代码
- 当控制流进入 全局代码 的执行环境时,执行以下步骤:
- 初始化全局执行环境
- 以下步骤描述 ECMA 脚本的全局执行环境 C 的创建过程:
- 将变量环境设置为 全局环境 。
- 将词法环境设置为 全局环境 。
- 将 this 绑定设置为 全局对象 。
- 定义绑定初始化
- 每个执行环境都有一个关联的变量环境
- 当在一个执行环境下执行一段ECMA脚本时,变量和函数定义会以绑定的形式添加到这个变量环境的环境记录中
- 对于函数函数代码,参数也同样会以绑定的形式添加到这个变量环境的环境记录中
- 选择使用哪一个、哪一类型的 环境记录 来绑定定义,是由执行环境下执行的 ECMA 脚本的类型决定的


