这是我参与「第四届青训营 」笔记创作活动的第1天
SQL 查询优化器浅析
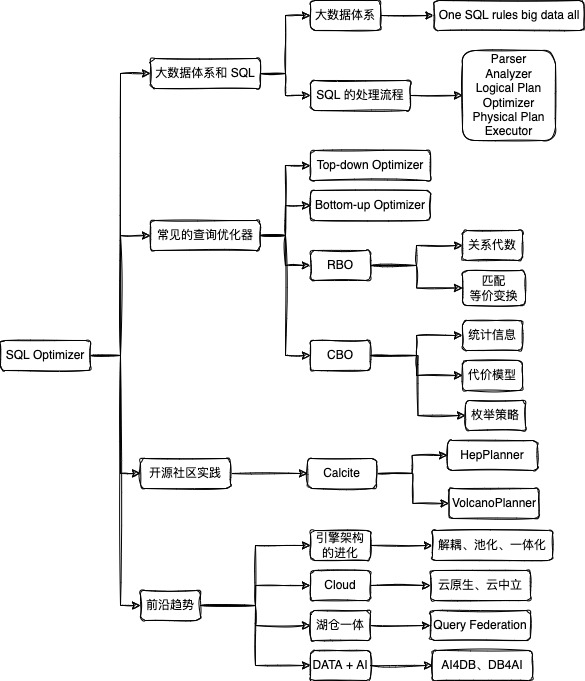
一、大数据体系
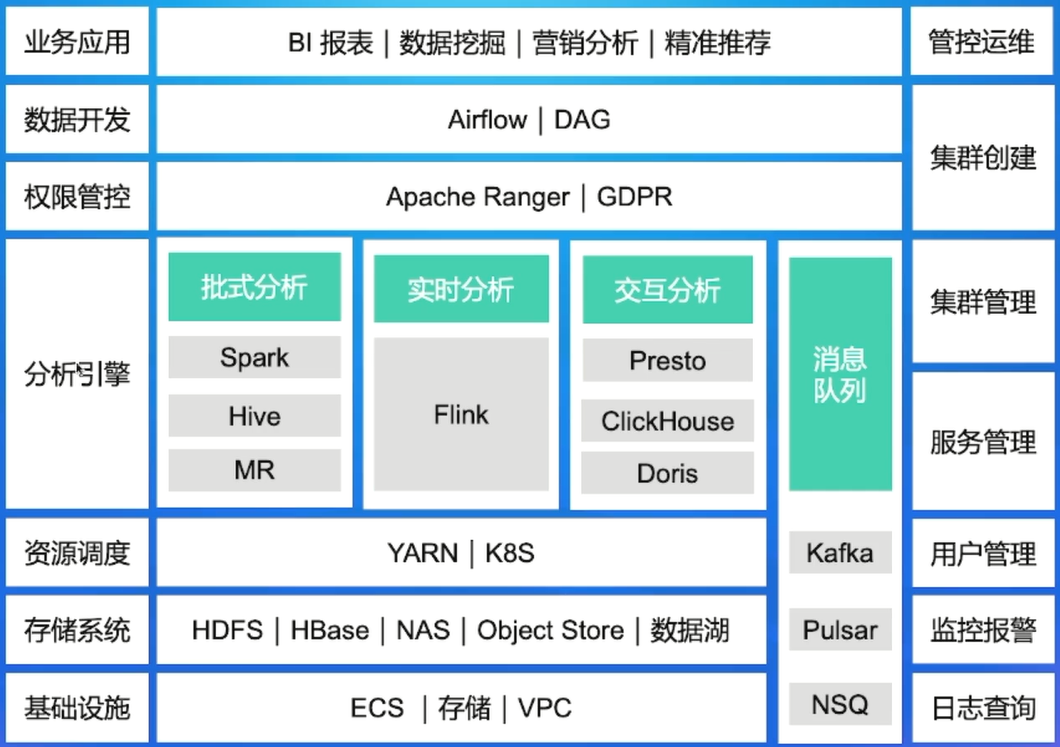
左侧是大数据的应用,自底向上。中间为细节划分,右侧为运维组件。
具体对应关系如上所示,这里的消息队列是为了解耦存储和计算。数据开发中常用的任务流调度有Airflow等等。
二、大数据体系和SQL
介绍大数据体系和SQL的处理流程,重点介绍SQL在分布式环境下的处理
2.1 大数据体系中的 SQL
SQL成为大数据处理的接口。
目标:SQL处理所有的大数据。One SQL rules big data all
2.2 SQL的处理流程
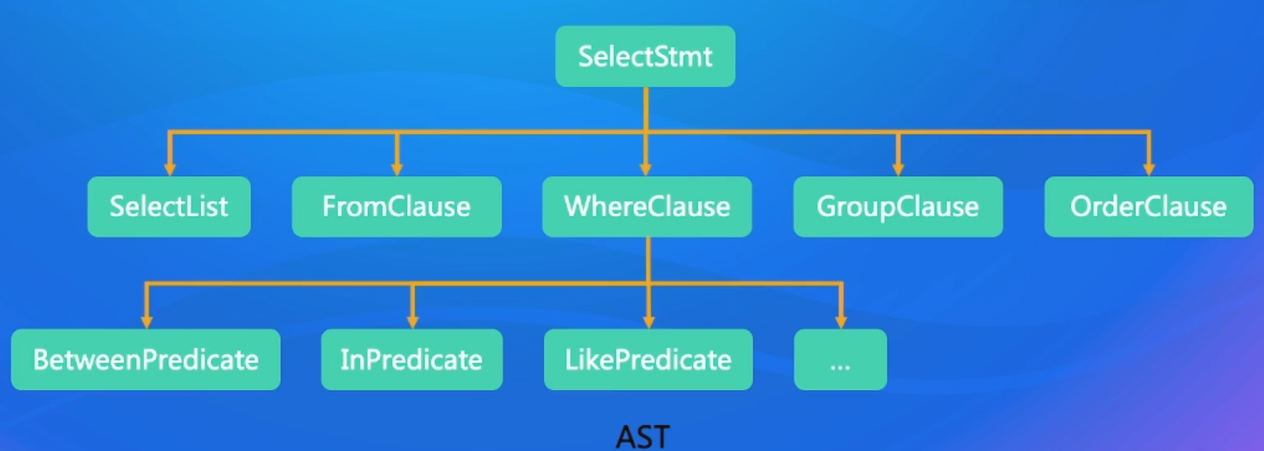
- 首先是parser:把一个SQL输入变成了一个AST的输出
- 经过Analyzer的一个处理输出一个logical plan逻辑的计划
- 经过一个优化器处理(本节重点)输出一个物理的执行计
- 交给Executor做执行,然后处理数据返回结果给用户
2.2.1 SQL的处理流程-Parser
-
String -> AST (abstract syntax tree)抽象语法树
-
经过两个步骤
词法分析:拆分字符串,得到关键词、数值常量、字符串常量、运算符号等token
语法分析:将token组成AST node,最终得到一个AST
-
实现:递归下降(ClickHouse),Flex Bison(PostgreSQL),JavaCC(FIink),Antlr(Presto, Spark)
2.2.2 SQL的处理流程- Analyzer和 Logical Plan
-
Analyzer
- 检查并绑定Database, Table, Column等元信息
- SQL的合法性检查,比如min/max/avg 的输入是数值
- AST -> Logical Plan
-
Logical Plan
- 逻辑计划就是逻辑地描述SQL对应的分步骤计算操作
- 计算操作:算子(operator),定义了数据的计算,像过滤、排序、聚合。
- 代表了数据的流向,并不细分算法,例如使用冒泡排序对数据进行排序,在逻辑计划中只是描述这一步骤为排序。
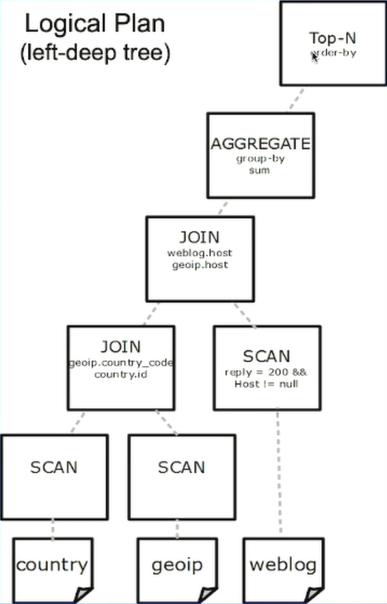
可以用下面的逻辑计划来表示:
注意这个结构叫left-deep tree。特点是右侧必须是表的结构。
由下图可知有scan算子、JOIN连接算子、聚合、堆排。
2.2.3 SQL的处理流程–查询优化
- SQL是一种声明式语言,用户只描述做什么,没有告诉数据库怎么做,给了数据库很大自由度
- 目标:找到一个正确且执行代价最小的物理执行计划
- 查询优化器是数据库的大脑,最复杂的模块,很多相关问题都是NP的(可能没法求最优解)
- 一般SQL越复杂,Join的表越多,数据量越大,查询优化的意义就越大,因为不同执行方式的性能差别可能有成百上千倍
2.2.4 SQL的处理流程- Physical Plan和Executor
-
Plan Fragment:执行计划子树
- 目标:最小化网络数据传输
- 利用上数据的物理分布(数据亲和性)实现。保证每个节点只读本地的因为远程读取的话会,涉及到网络的开销。
- 增加Shuffle算子,用于执行计划的连接,一边做发送一边做接收。
-
Executor
- 单机并行: cache, pipeline,SIMD(项链化技术)
- 多机并行:一个 fragment 对应多个实例
对优化后的逻辑计划进行拆分,每个节点只拿到这个 完整的一个执行计划的一个部分。然后这个拆分出来的一些子树称为plan fragment。
如上图,拆分成七个Fragment,而在节点中,1和2都有F1的实例,F3根据数据亲和性,会与F1在同一个节点上。
2.3 小结
- One sQL rules big data all
- SQL需要依次经过Parser,Analyzer,Optimizer 和Executor 的处理
- 查询优化器是数据库的大脑,在大数据场景下对查询性能至关重要
- 查询优化器需要感知数据分布,充分利用数据的亲和性
- 查询优化器按照最小化网络数据传输的目标把逻辑计划拆分成多个物理计划片段
三、常见的查询优化器
介绍查询优化器的分类,重点介绍RBO和CBO的原理
3.1 查询优化器分类
两种分类方法
3.1.1 遍历树的顺序划分
-
Top-down Optimizer
- 从目标输出开始,由上往下遍历计划树,找到完整的最优执行计划
- 例子: Volcano/Cascade,SQLServer
-
Bottom-up Optimizer
- 从零开始,由下往上遍历计划树,找到完整的执行计划
- 例子:System R(最早的优化器),PostgreSQL, IBM DB2
3.1.2 根据优化的方法划分
-
Rule-based Optimizer (RBO)
- 根据关系代数等价语义,重写查询
- 基于启发式规则
- 会访问表的元信息(catalog),不会涉及具体的表数据(data)
-
Cost-based Optimizer (CBO)
- 使用一个模型估算执行计划的代价,选择代价最小的执行计划
3.2 RBO(Rule-based Optimizer)
3.2.1 RBO-关系代数
运算符: Select , Project , Join , Rename , Union 等等价变换:结合律,交换律,传递性
- Select: (可以拆分)
- Join: (先后顺序不影响)
两张表,连接,再做过滤选择,最后project输出。
3.2.2 RBO-优化原则
- Read data less and faster (I/O)
- Transfer data less and faster (Network)
- Process data less and faster (CPU & Memory)
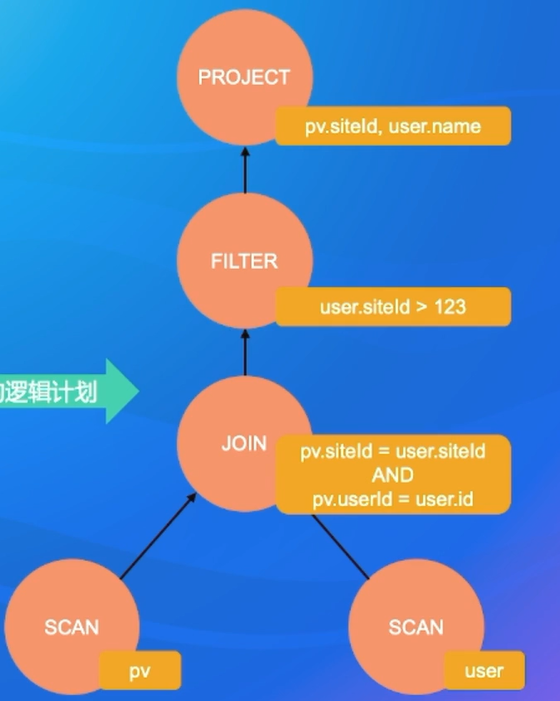
例子:
连接两张表,连接条件ON,还有过滤条件Where
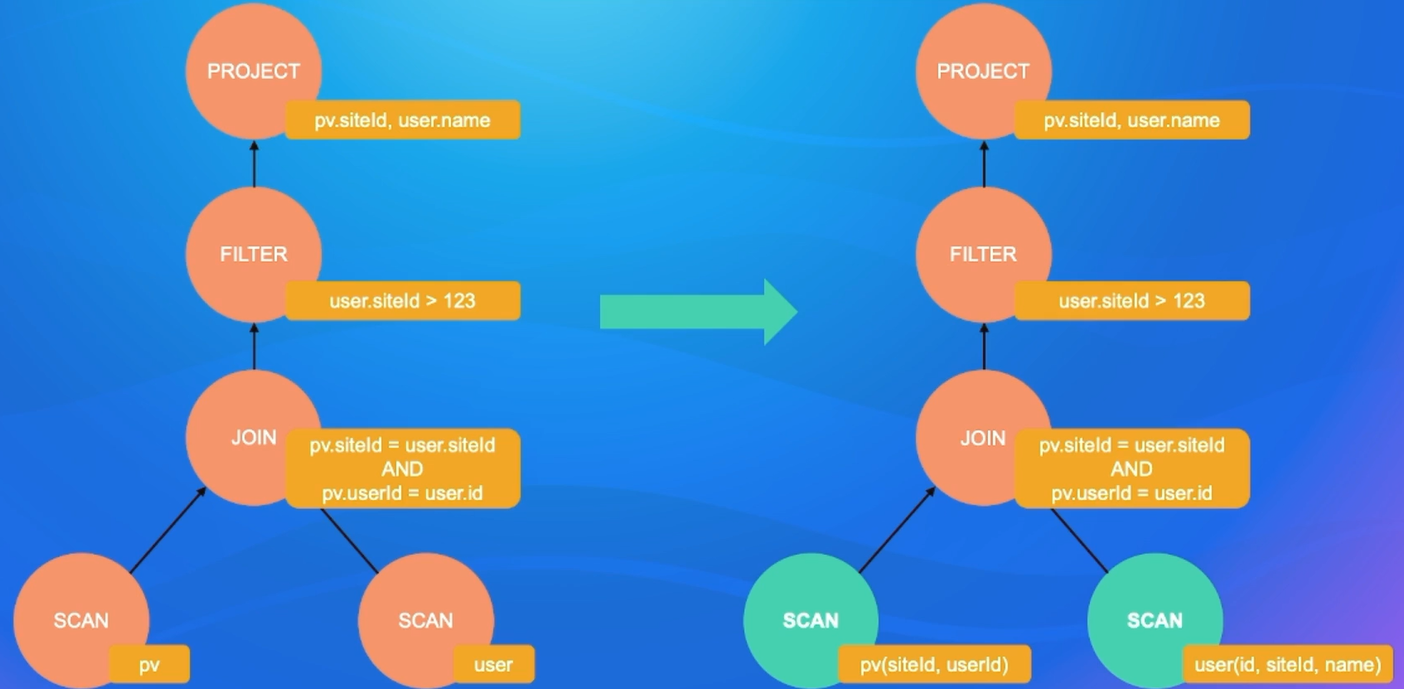
3.2.3 RBO-列裁剪

由列裁剪,先自顶向下扫描需要的列,然后把scan只保留所需要的列即可。
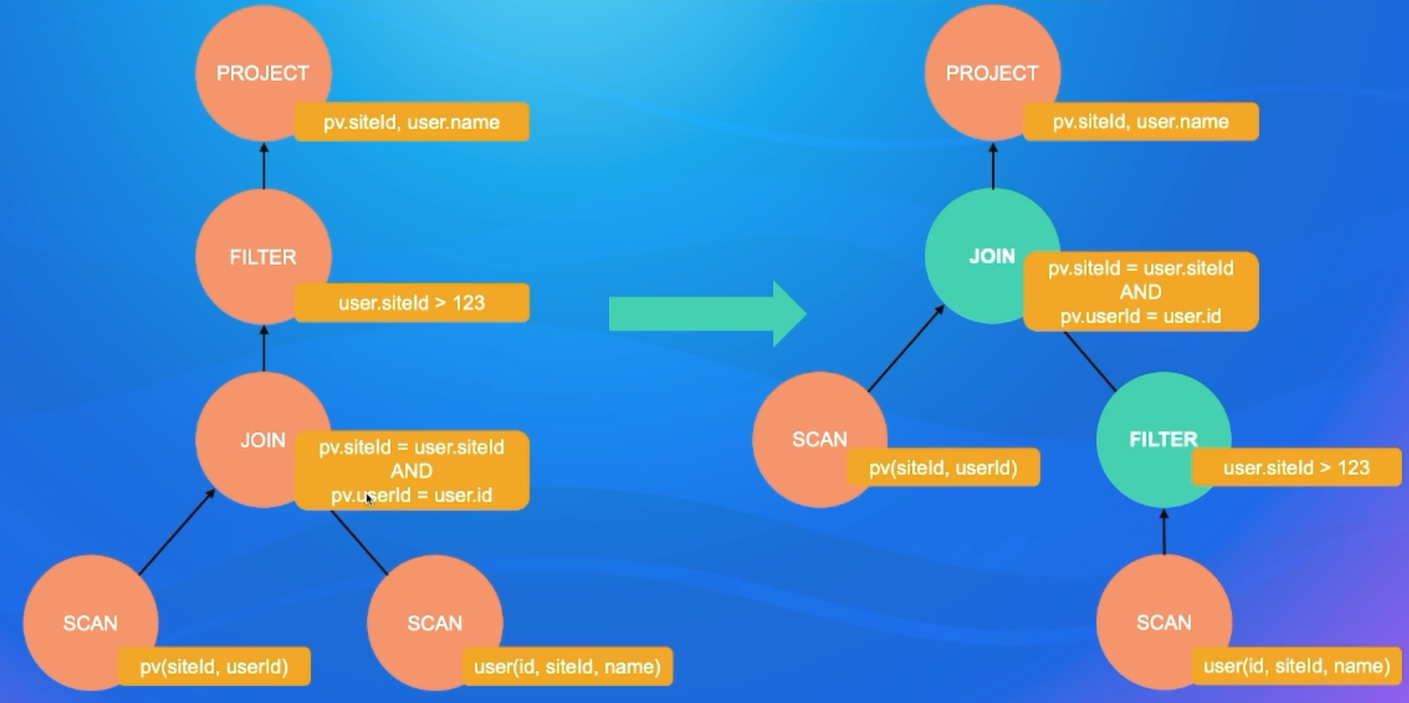
3.2.4 RBO-谓词下推
在某些场景下先后过滤结果是不受影响,那么我们就可以 把这个谓词尽可能往下推,尽早过滤掉一些不必要的数据,显著的减少传输或者计算的开销。

Where后的表达式称为谓词
3.2.5 RBO-传递闭包
根据等价关系推导出新的过滤条件。
SELECT pv.siteld, user.name
FROM pv JOIN user
ON pv.siteld = user.siteld AND pv.userld = user.id
WHERE user.siteld > 123;
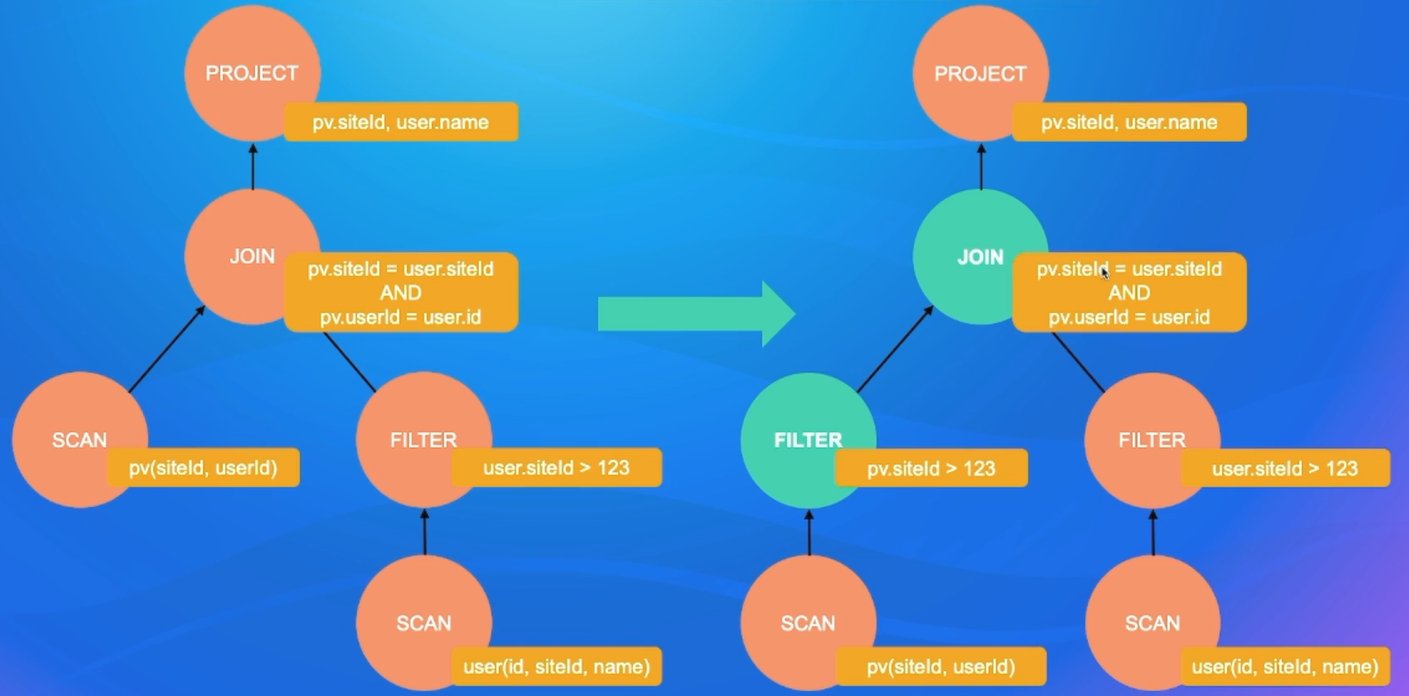
3.2.6 RBO -Runtime Filter
运行时才会有的runtime 过滤

例如右边是个哈希表,左边是要遍历关系查询它在哈希表中是否存在。
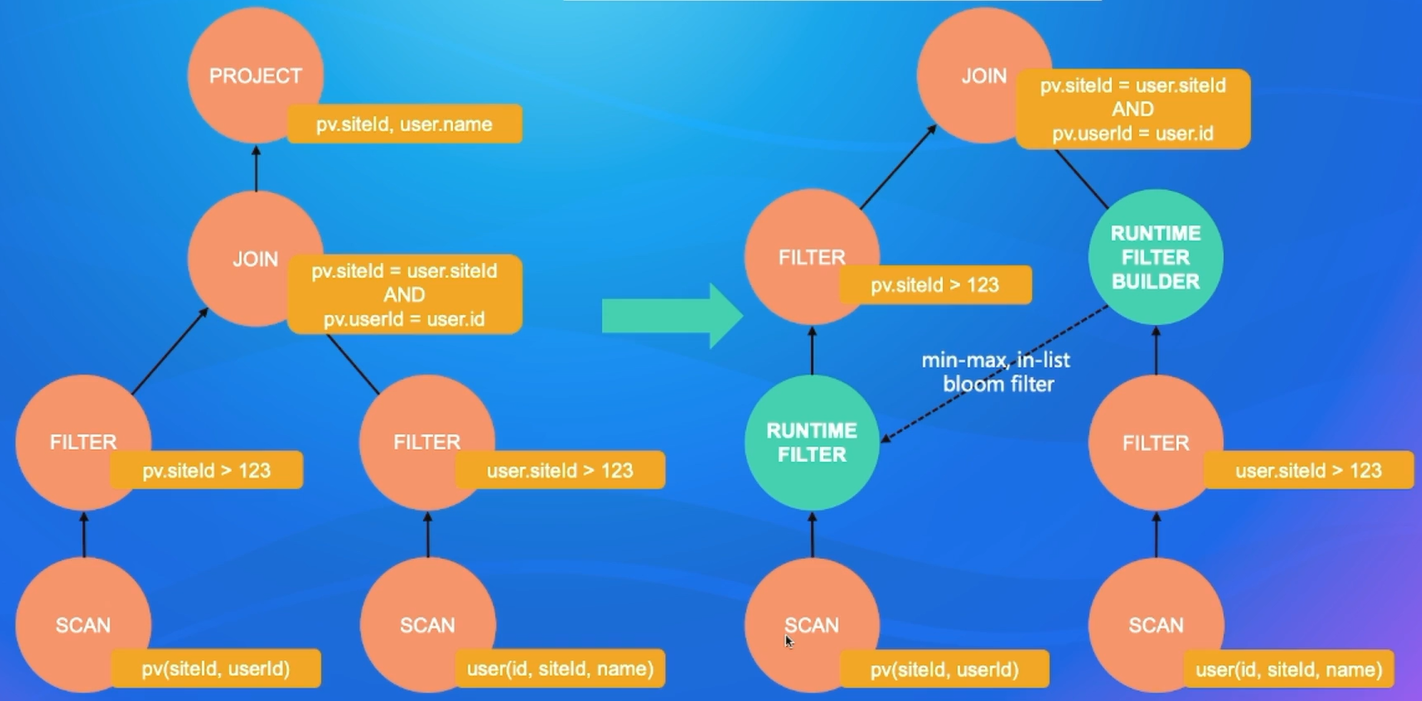
右边在过滤之后,生成一个Runtime filter builder,传递数据的min-max参数供左侧提早过滤。
但是min-max可能会产生数据范围过大的情况,过滤效果不强。例如数据是0到100万,但是他大部分数据是都是集中到0到100。
这时可以附加in list,里面包含0到100的101一个数,还包含一百万这么一个数,实际上就是102个数。传递的给左边,就可以完成过滤了。扫描in list这个里面集合的那个值对应数据就可以了。起到很好的过滤效果。
但是in list的缺点是右边他的集合的个数很多的时候,in list就会很大,开销也很大。
可以加入bloom filter,大小是不属于这个集合的大小而改变,是固定大小的。具体细节见后面的系列文章。
3.3 RBO小结
-
主流RBO实现一般都有几百条基于经验归纳得到的优化规则
-
优点:实现简单,优化速度快
-
缺点:不保证得到最优的执行计划(因为是基于经验)
-
单表扫描:索引扫描(随机I/O)vs全表扫描(顺序I/O)
- 如果查询的数据分布非常不均衡,索引扫描可能不如全表扫描
-
Join的实现:Hash Join vs. SortMerge Join
没办法做到最优的选择join
-
两表Hash Join:用小表构建哈希表——如何识别小表?
-
多表Join:
-
哪种连接顺序是最优的?
-
是否要对每种组合都探索?
- N个表连接,仅仅是 left-deep tree就有差不多N!种连接顺序
- e.g. N =10->总共3,628,800个连接顺序,但是不可能遍历每一种。
-
-
选择错误的一边构建哈希表容易导致内存溢出。filter之后选择左侧构建更好。
3.4 CBO(Cost-based Optimizer)
3.4.1 CBO-概念
-
使用一个模型估算执行计划的代价,选择代价最小的执行计划
- 执行计划的代价等于所有算子的执行代价之和
- 通过 RBO得到(所有)可能的等价执行计划
-
算子代价:CPU,内存,磁盘I/O,网络I/O等代价
-
和算了输入数据的统计信息有关:输入、输出结果的行数,每行大小...
- 叶子算子Scan:通过统计原始表数据得到
- 中间算子:根据一定的推导规则,从下层算子的统计信息推导得到
-
和具体的算子类型,以及算子的物理实现有关
-
例子: Spark Join算子代价= weight * row_count (CPU代价)+ (1.0 - weight) * size (IO代价)
当然每个系统中计算公式不一样
-
处理流程:

3.4.2 CBO-统计信息与推导
(1)统计信息
-
原始表统计信息
- 表或者分区级别:行数、行平均大小、表在磁盘中占用了多少字节等
- 列级别: min、max、num nulls、num not nulls、num distinct value(NDV互不相同的值)、histogram(直方图)等
-
推导统计信息
- 选择率(selectivity):对于某一个过滤条件,查询会从表中返回多大比例的数据
- 基数(cardinality):在查询计划中常指算子需要处理的行数
准确的cardinality,远比代价模型本身重要。——“How Good Are Query Optimizers,Really?"
(2)CBO-统计信息的收集方式

第一种实时更新会有参数更新慢的缺点。
第二种手动方式,缺点没更新之前统计信息比较旧。
第三种,动态采样。一个query过来时先采样一下表,比如先采样table种的行数信息,估算整张表的数据。
(3)CBO-统计信息推导规则
假设是独立分布,值是均匀分布。

1代表选中所有数据,0代表不选。第三种情况是选择率。
(4)CBO-统计信息的问题
假设列和列之间是独立的,列的值是均匀分布。
这个假设往往是不相符的。例如
考虑一个汽车数据库automobiles ,有10个制造商,100个车型, filter为“制造商=‘比亚迪’且车型='汉',根据独立性和均匀分布假设,则selectivity = 1/10 × 1/100= 0.001 ,但是‘比亚迪′和‘汉′是相关联的,车型是汉则制造商必为比亚迪,实际selectivity = 1/100= 0.01。
这时候必须用户指定或者数据库自动识别相关联的列。
考虑中国人口数据库,性别,年龄,数量都不是均匀分布
可以使用直方图来筛出不是均匀分布的情况。
3.4.3 CBO-执行计划枚举
-
单表扫描:索引扫描(随机I/O) vs.全表扫描(顺序I/O)
- 如果查询的数据分布非常不均衡,索引扫描可能不如全表扫描
-
Join的实现:Hash Join vs. SortMerge Join
-
两表Hash Join:用小表构建哈希表——如何识别小表
-
多表Join:
-
哪种连接顺序是最优的?
-
是否要对每种组合都探索?
- N个表连接,仅仅是left-deep tree就有差不多N!种连接顺序
- e.g.N= 10-→>总共3,628,800个连接顺序
-
通常使用贪心算法或者动态规划选出最优的执行计划
动态规划过程



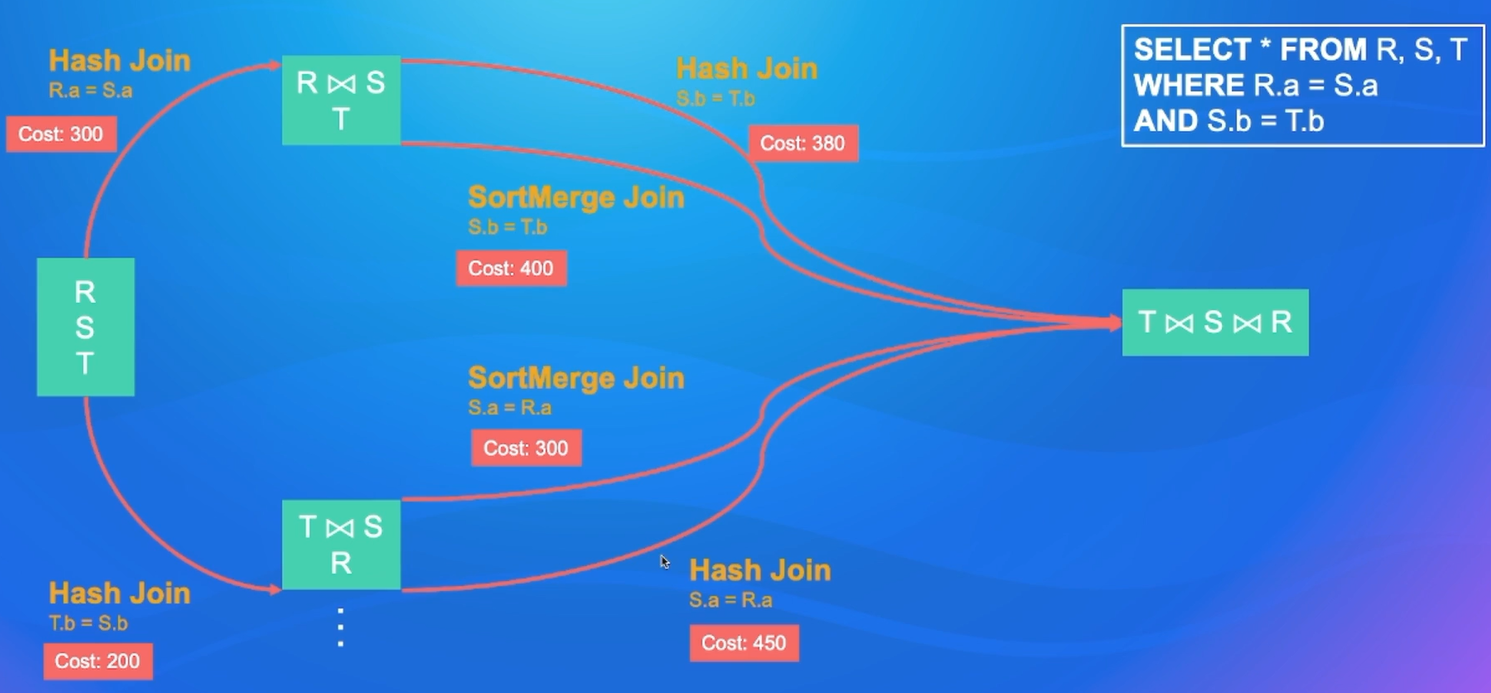
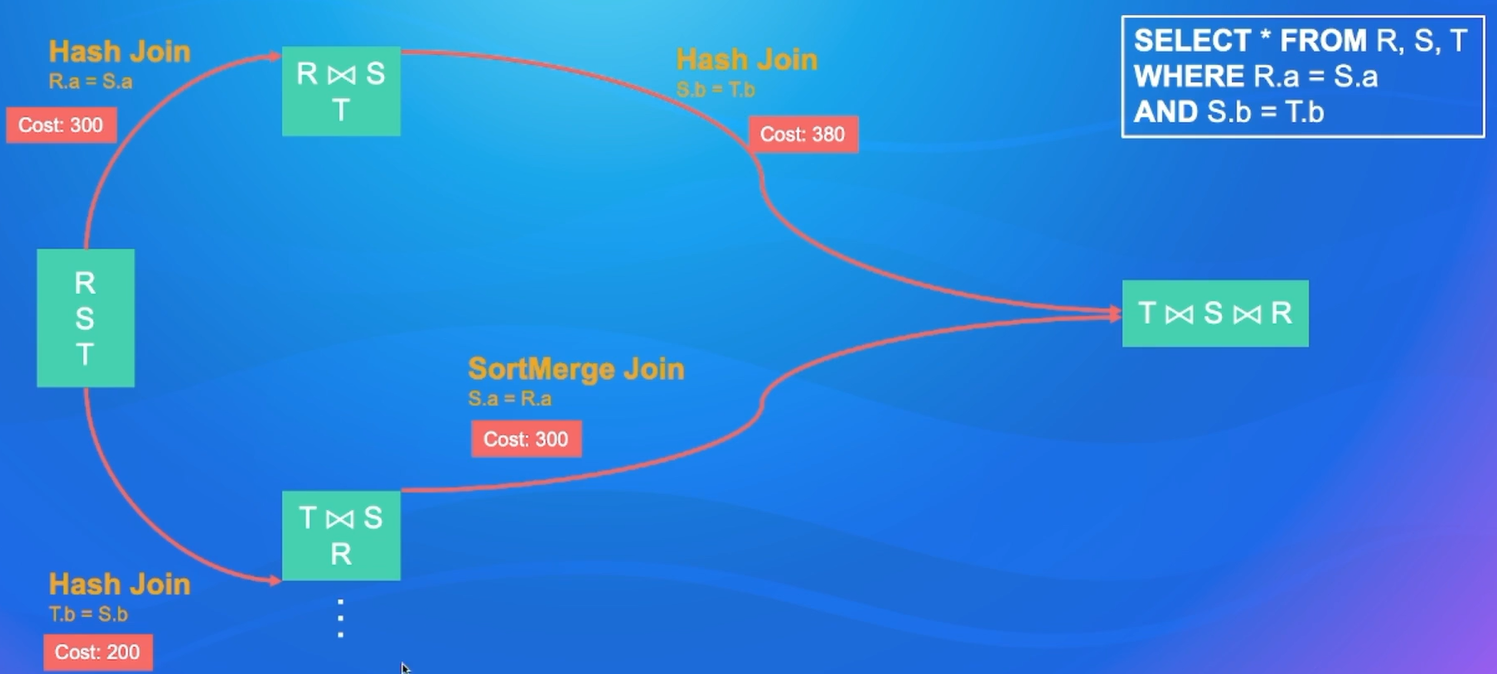
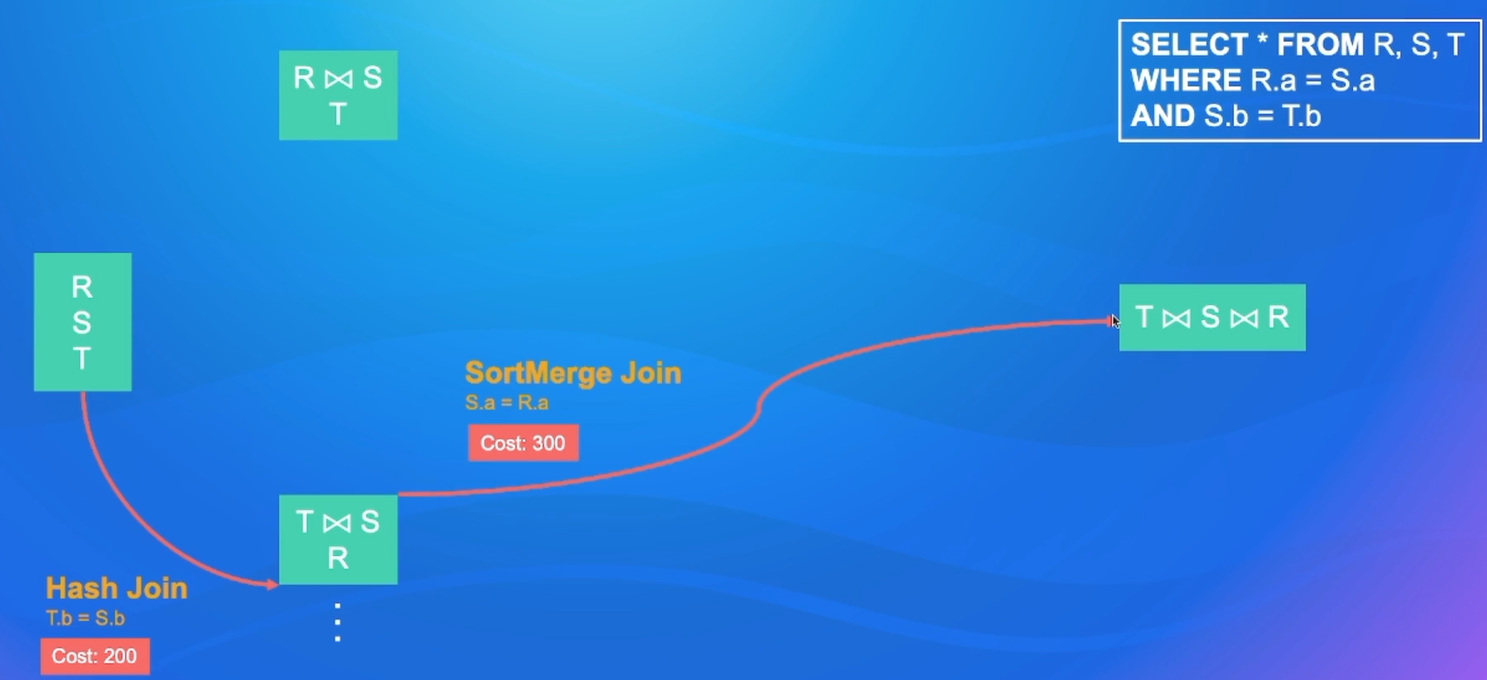
CBO效果-TPC-DS Q25
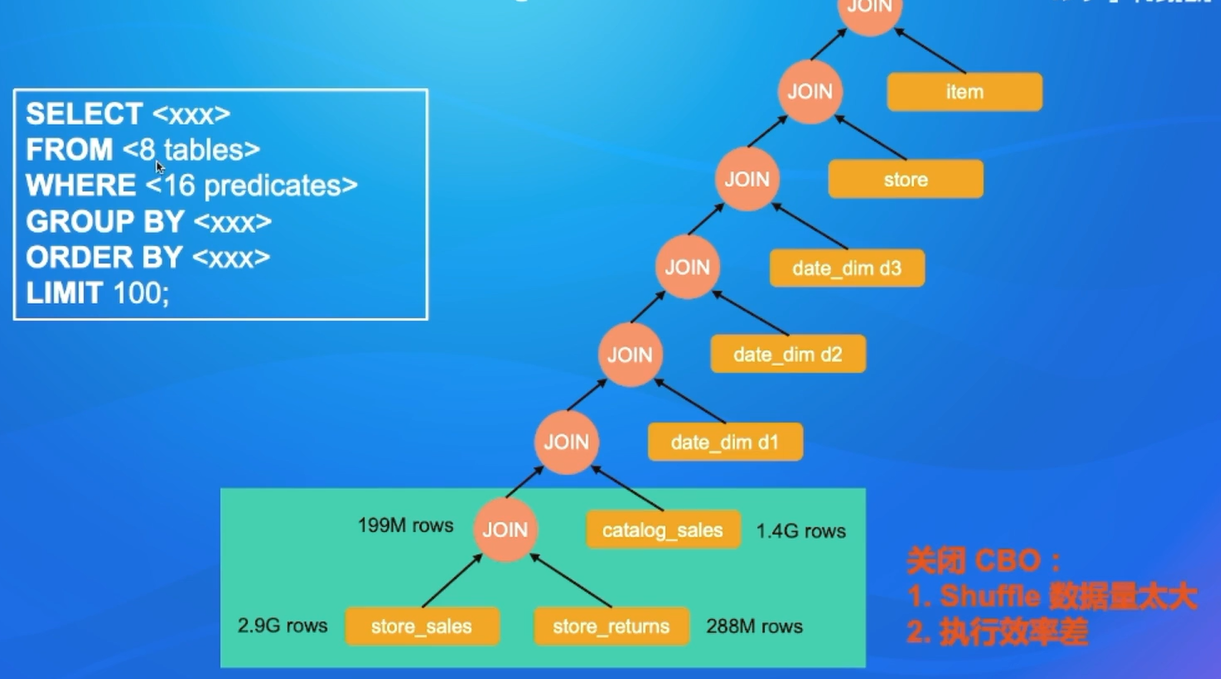
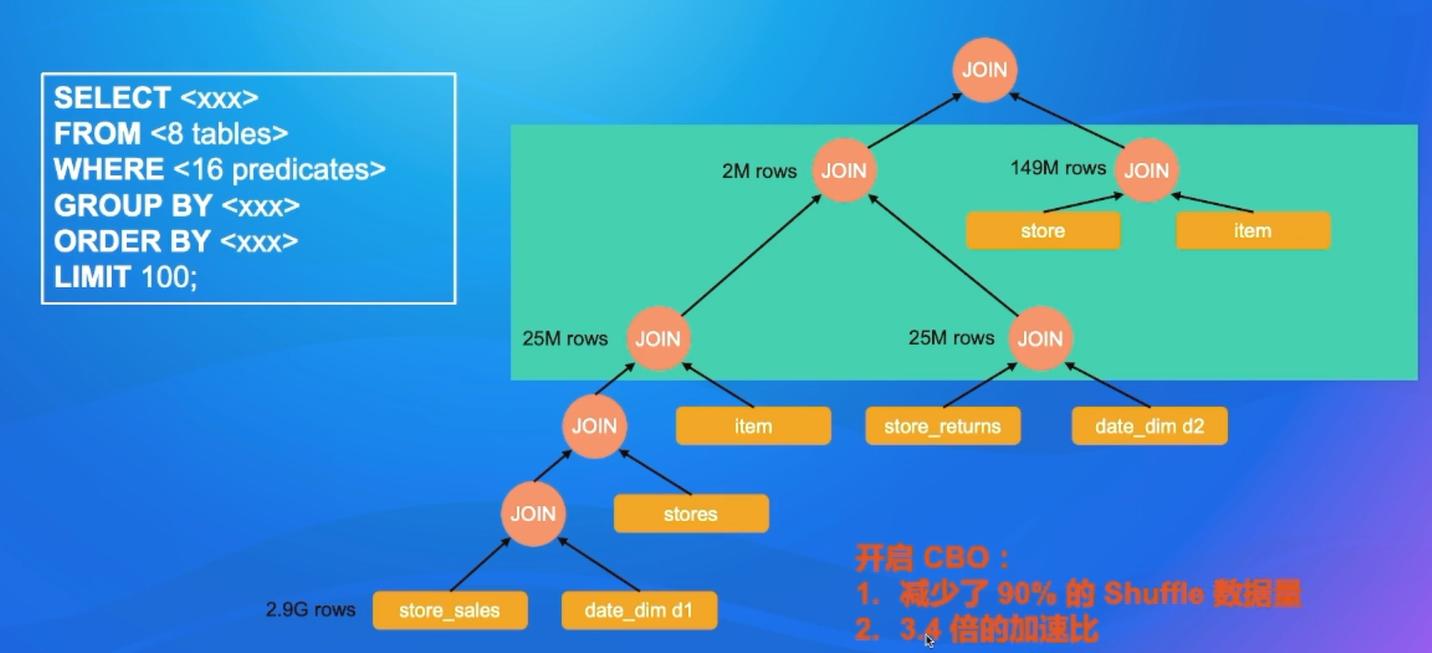
CBO效果对比- TPC-DS
- 大概一半的查询都没显示出性能变化,这是因为RBO能为这些查询找到最优执行计划。
- 16个查询在CBO下有更好的执行性能
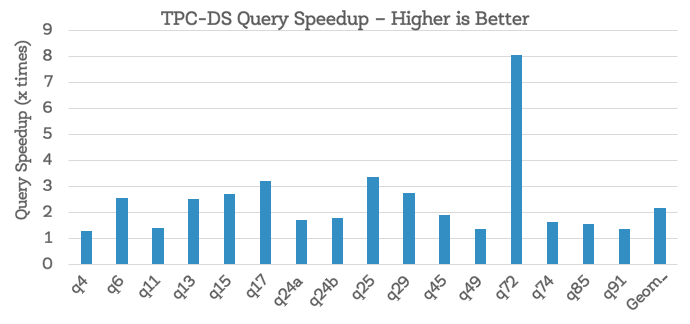
- 加速比从2.2X ~ 8X
- 性能提升很大
3.5 CBO小结
- CBO使用代价模型和统计信息估算执行计划的代价
- CBO使用贪心或者动态规划算法寻找最优执行计划
- 在大数据场景下CBO对查询性能非常重要
3.6 小结
RBO
- 主流 RBO 实现一般都有几百条基于经验归纳得到的优化规则
- RBO 实现简单,优化速度快
- RBO不保证得到最优的执行计划
CBO
- CBO使用代价模型和统计信息估算执行计划的代价
- CBO使用贪心或者动态规划算法寻找最优执行计划
- 大数据场景下CBO对查询性能非常重要
四、社区开源实践
介绍查询优化器在社区的开源实践,重点介绍Apache Calcite项目
4.1 社区开源实践–概览
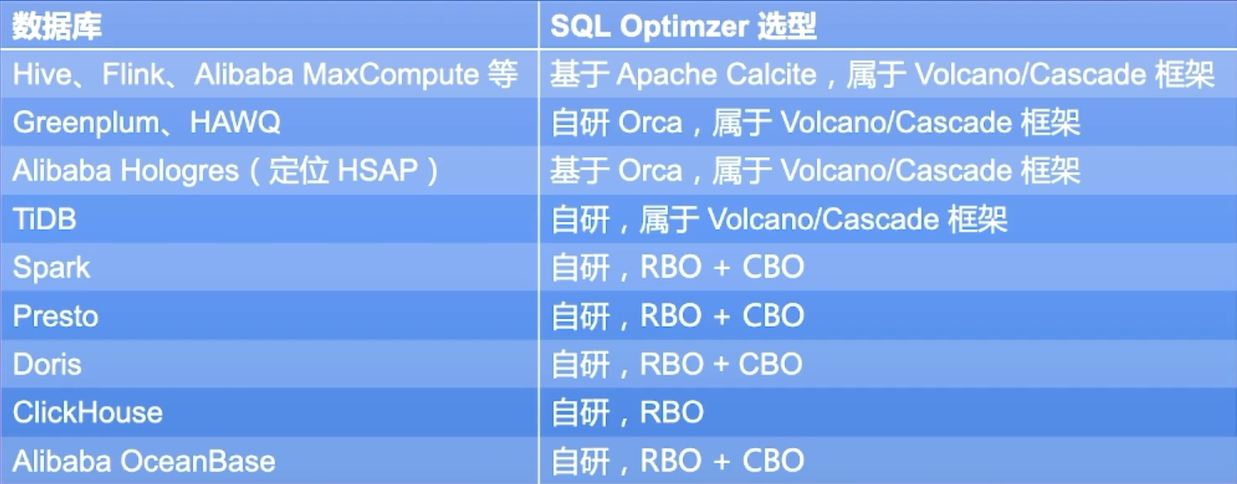
其中Volcanol(C++)/Cascade(java)框架属于优化器的一种实践框架。概述实现过程。
- 可见主流的优化器都包含RBO和CBO。
4.2 Apache Calcite
4.2.1 Apache Calcite概览
-
One size fits all:统一的SQL查询引擎
作为一个通用的查询优化模块,至于处理等后续过程交给其他模块。
-
模块化,插件化,稳定可靠
-
支持异构数据模型
- 关系型
- 半结构化
- 流式
- 地理空间数据
-
内置 RBO和CBO
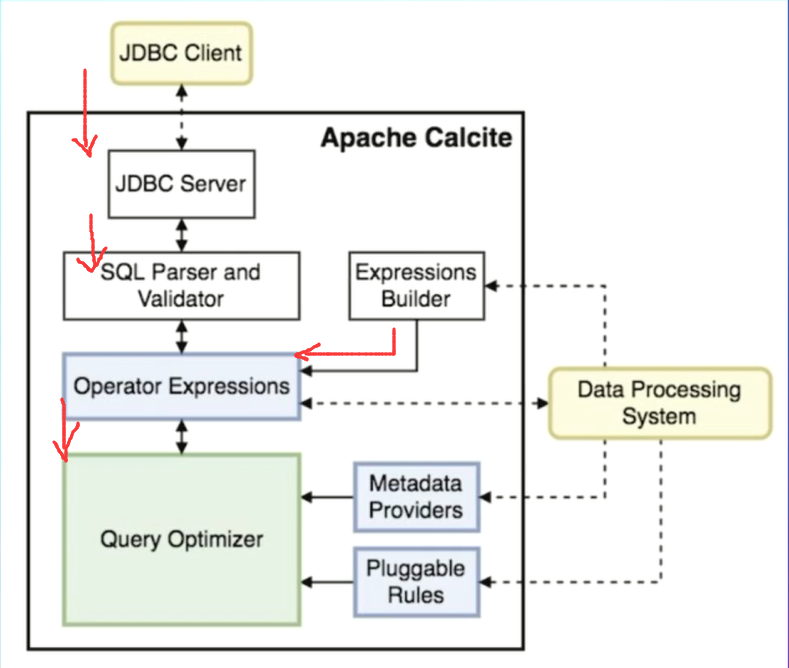
框架图如上所示。
Operator Expressions包括一些算子和表达式。
Metadata Providers,Pluggable Rules两个插件可以支持不同的系统。
4.3 Calcite RBO
HepPlanner
-
优化规则(Rule)
- Pattern:匹配表达式子树
- 匹配之后会对表达式等价变换:得到新的表达式,替换原来的子树。
-
内置有100+优化规则
-
四种匹配规则
- ARBITRARY/DEPTH_FIRST:深度优先
- TOP DOWN:拓扑顺序
- BOTTOM_UP:与TOP_DOWN 相反
-
遍历所有的rule,直到没有rule可以被触发
-
优化速度快,实现简单,但是不保证最优
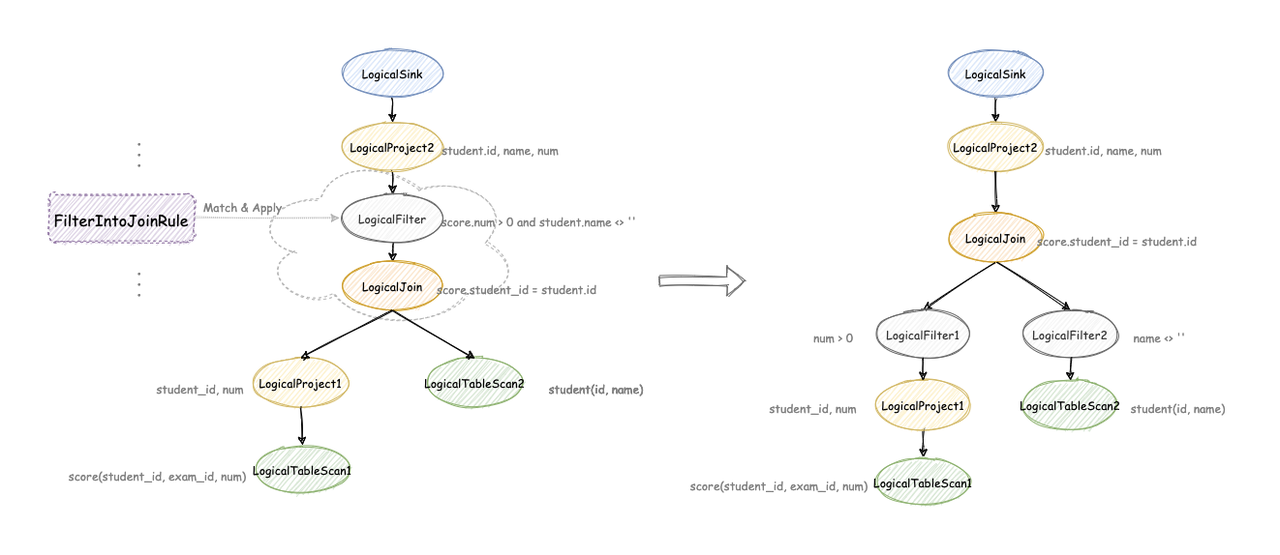
4.4 Calcite CBO
VolcanoPlanner
-
基于Volcano/Cascade框架
-
成本最优假设
-
Memo:存储候选执行计划
- Group:等价计划集合
-
Top-down动态规划搜索
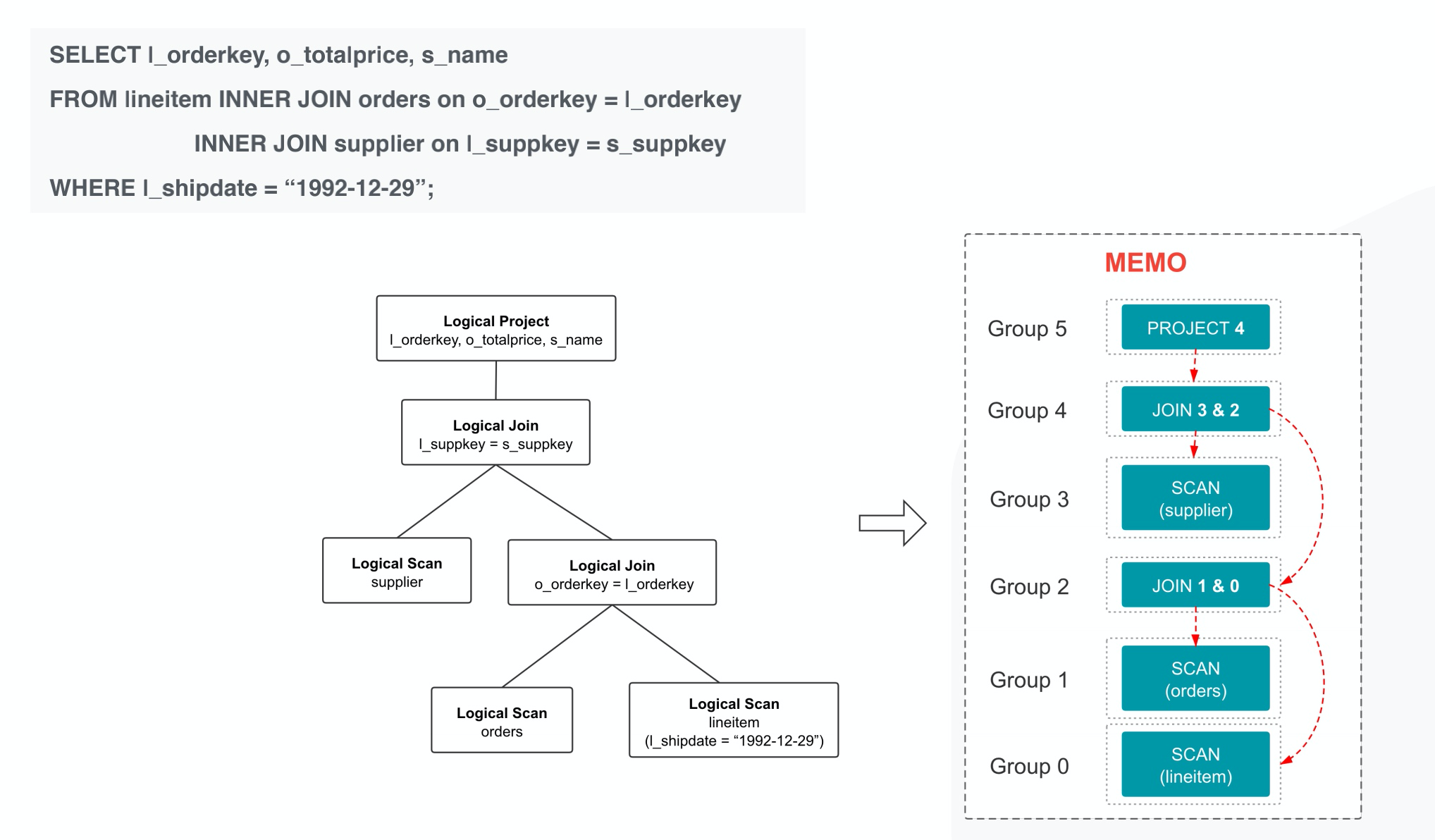
左边为原始,右边为CBO之后的。精妙的是可以转换为MEMO的结构实现。
等价的关系算子放在一个group之间,可以共享子树从而减少内存开销。
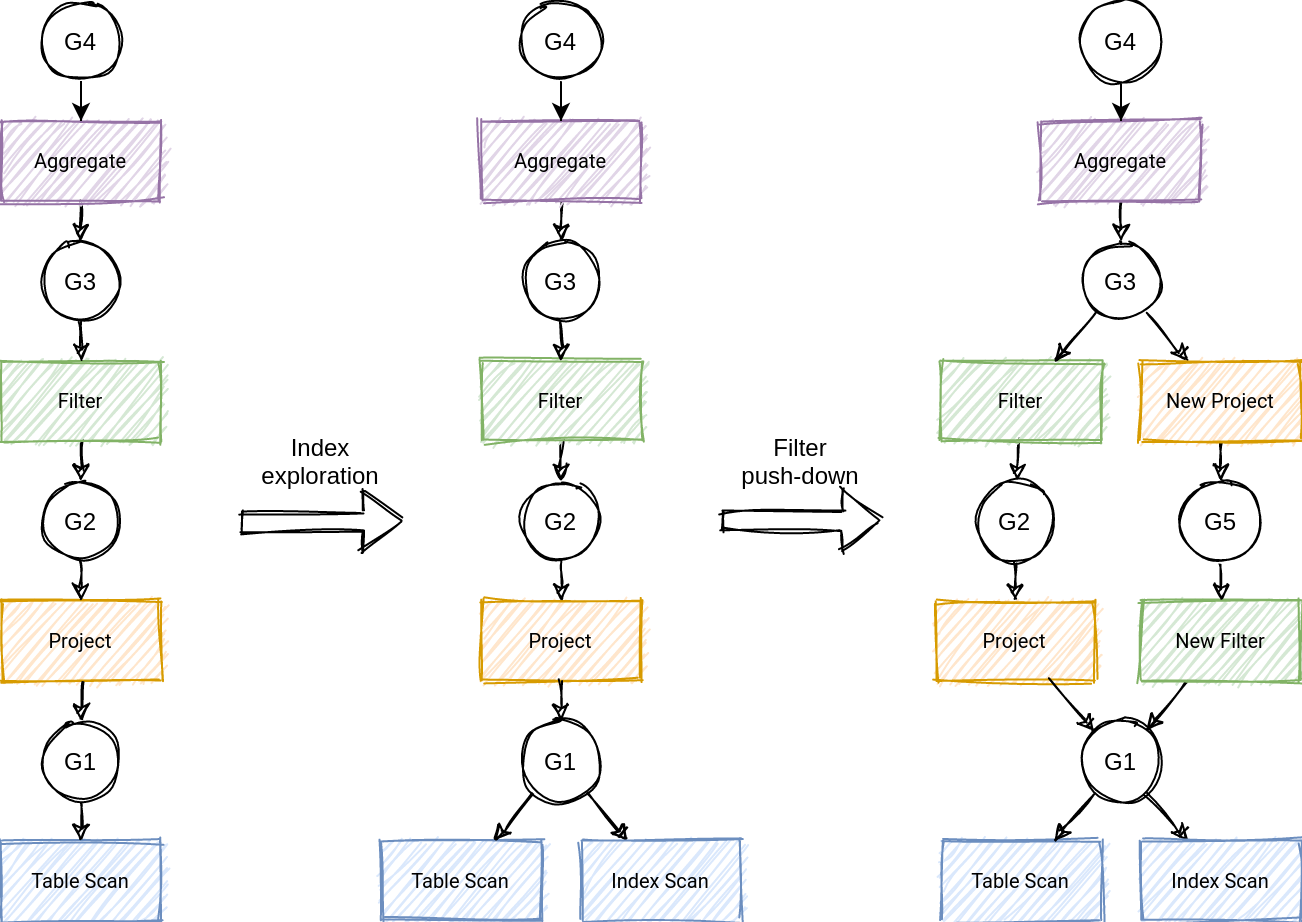
-
应用Rule搜索候选计划
-
Memo
- 本质:AND/OR graph
- 共享子树减少内存开销
是一个and or关系图,上下是and,左右并列的为or关系。
- Group winner:目前的最优计划
.png)
-
剪枝(Branch-and-bound pruning) :减少搜索空间
- 可行的Aggregate总的cost = 500
- 自己的cost = 150
- 孩子节点cost上限= 350
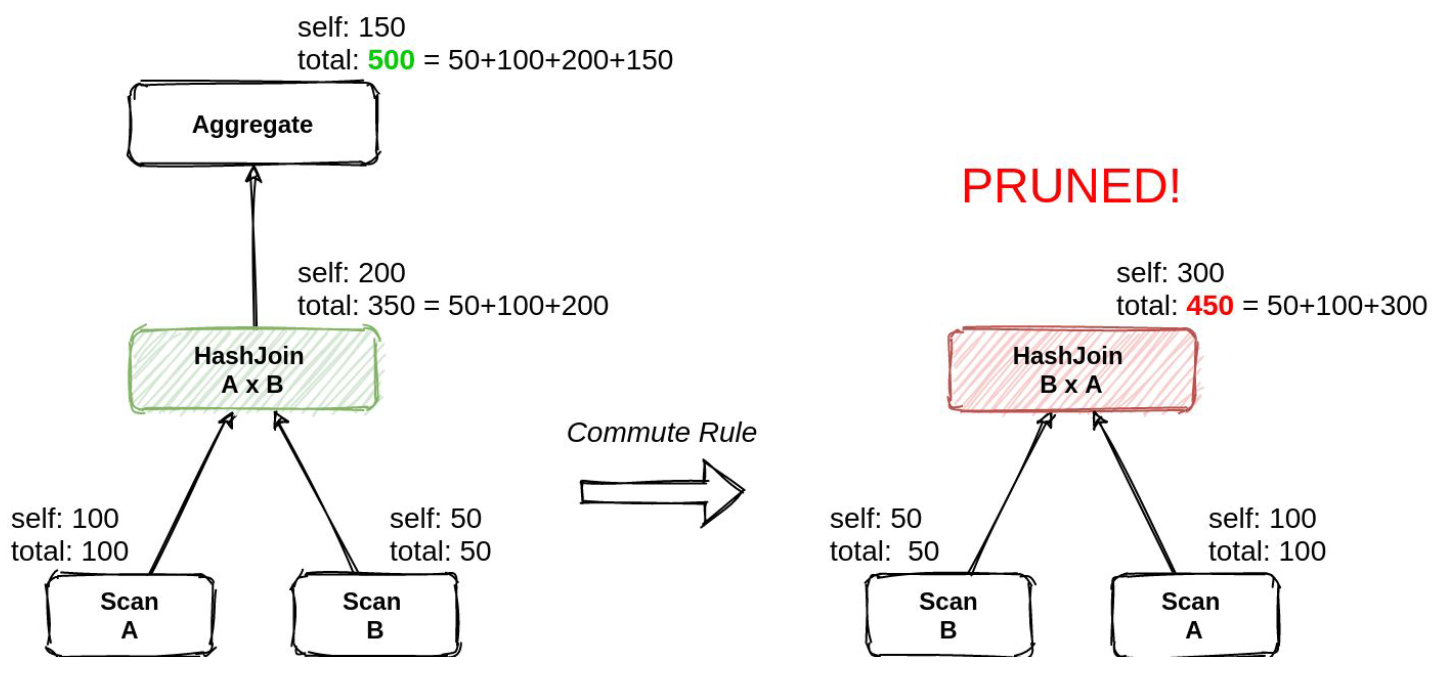
然后不断更新上限,超过HashJoin上限的可以直接剪枝掉。
- Top-down遍历:选择winner构建最优执行计划
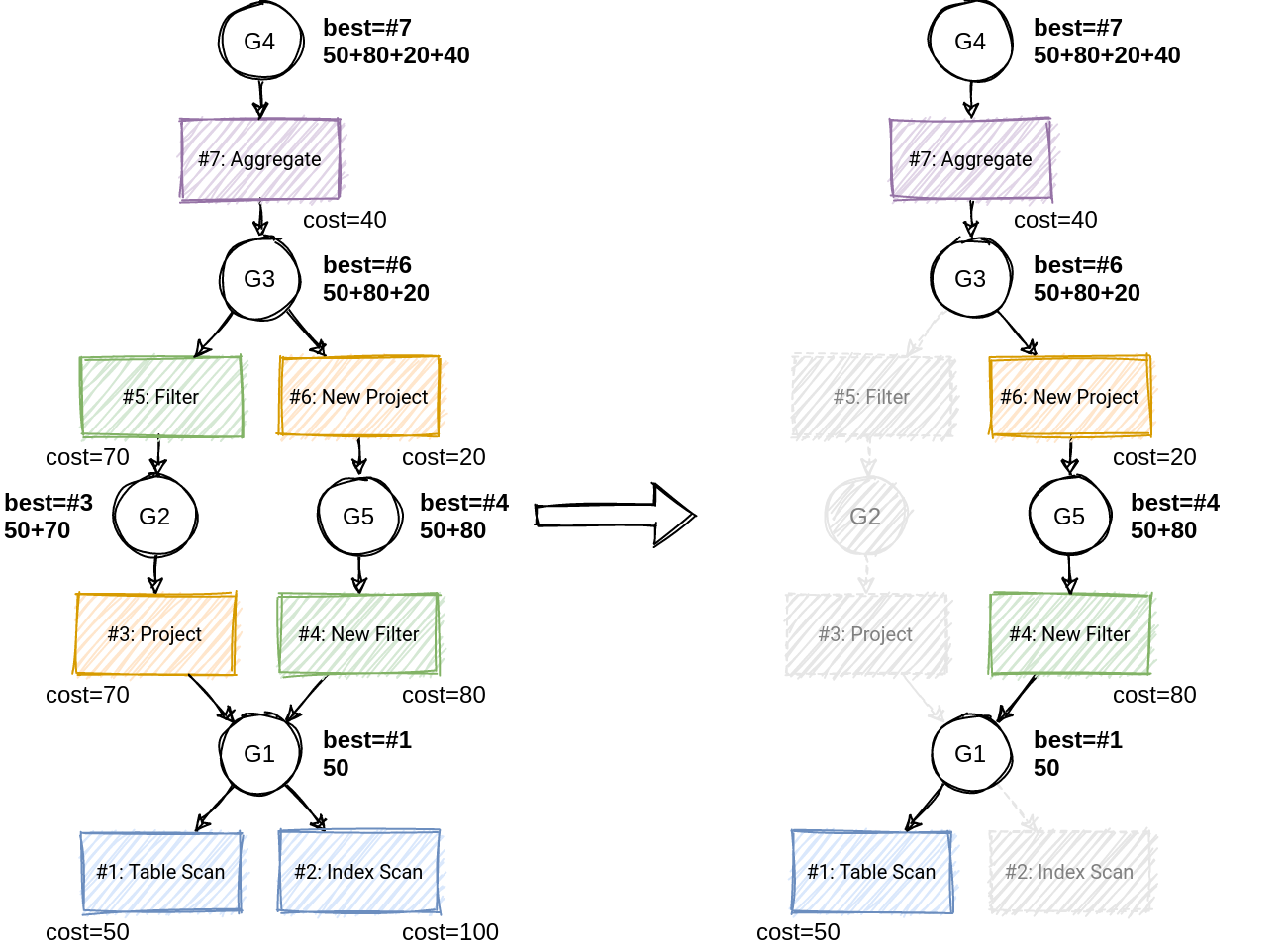
4.5 小结
- 主流的查询优化器都包含RBO和CBO
- Apache Calcite是大数据领域很流行的查询优化器
- Apache Calcite RBO定义了许多优化规则,使用pattern匹配子树,执行等价变换
- Apache Calcite CBO基于Volcano/Cascade框架
- Volcano/Cascade的精髓:Memo、动态规划、剪枝
五、前沿趋势
介绍SQL引学的前沿趋势,重点介绍Al和DB的结合
5.1 Big Data,Big Money
- 2021年初,Starburst Data公司为其Trino系统(以前的 PrestoSQL)筹集了1亿美元。
- 2021年6月,Apache Kafka商业化公司Confluent登陆 NSDAQ,首日涨25%,市值超110亿美元。
- 2021年8月,Apache lceberg的创建者Ryan Blue正式成立围绕lceberg的商业公司Tabular。
- 2021年8月,Spark背后的公司Databricks宣布获得16亿美元融资,最新估值飙升至380亿美元。
- 2021年9月,ClickHouse的创建者Alexey正式成立公司: ClickHouse, Inc,获得了5000万美元融资。
- 2021年10月,基于Apache Pulsar的商业化公司StreamNative宣布茨得 2300万美元A轮融资。
5.2 概览
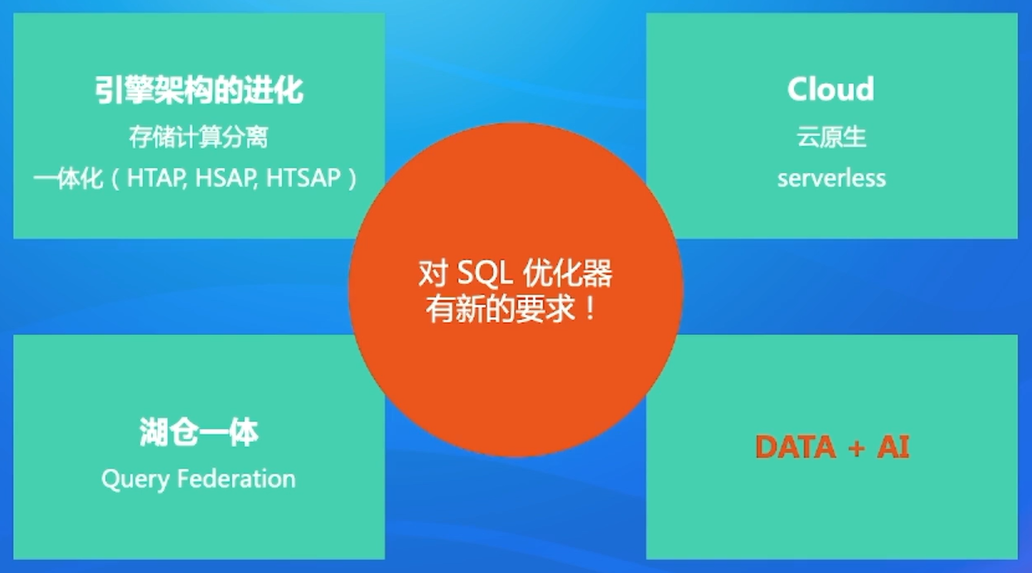
-
存储计算分离
之前的数据库都是存储跟计算连在一起的,这个节点既存储数据又做计算。无法单独扩容,如果计算需求很小,又会浪费计算。因此未来趋势可以单独扩容。
-
云原生,serverless
上K8S,根据负载动态的去调整集群规模,当没有流量过来即没有查询的时候,可以把那个计算节点给缩险缩减。当流量变大的时候,就可以把计算机点扩充,这样可以大大减少成本。
-
湖仓一体
数据仓库的概念:预先的定义好一些数、一些表的模型,然后对原始的日志,各种数据进行一些处理 ,把它变成一个关系型的数据,存到这个数据仓库里面。但是这会限制使用,因为业务往往不知道需要的模型是什么,会丢失原始数据,对迭代不是很友好。
因此需要把原始数据都当成文件存下来,这个就是一个数据湖。里面的数据是,不规则的,管理起来比较乱。
因此现在趋势就是湖仓一体,能用一个统一的SQL去查询、记录数据以及数据仓库元数据。
-
DATA+AI
5.3 DATA+AI
-
AI4DB
-
自配置
- 智能调参(OtterTune,QTune)
- 负载预测/调度:预测高峰期,提前扩容。
-
自诊断和自愈合:错误恢复和迁移
-
自优化:
- 统计信息估计( Learned cardinalities )
- 代价估计
- 学习型优化器(IBM DB2 LEO)
- 索引/视图推荐
-
-
DB4AI
- 数据库内嵌人工智能算法(MLSQL,SQLFlow)
- 数据库内嵌机器学习框架(SparkML, Alink,dl-on-flink )
5.4 小结
- 大数据创业如火如荼,SQL查询优化器仍然是必不可少的一个重要组件
- 引擎架构的进化、云原生、湖仓─体等对SQL查询优化器有新的要求和挑战
- Al加持,学习型查询优化器在不断进化
六、总结