

卷积神经网络在计算机视觉应用中已经被发现是成功的。人们提出了各种网络架构,它们既不神奇也不难理解。
在本教程中,我们将了解卷积层的操作以及它们在更大的卷积神经网络中的作用。
完成本教程后,你将学会
- 卷积层如何从图像中提取特征
- 不同的卷积层如何叠加起来构建一个神经网络
让我们开始吧。
概述
本文分为三个部分,它们是:
- 一个网络实例
- 显示特征图
- 卷积层的效果
一个网络实例
下面是一个对CIFAR-10数据集进行图像分类的程序。
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Dropout, MaxPooling2D, Flatten, Dense
from tensorflow.keras.constraints import MaxNorm
from tensorflow.keras.datasets.cifar10 import load_data
(X_train, y_train), (X_test, y_test) = load_data()
# rescale image
X_train_scaled = X_train / 255.0
X_test_scaled = X_test / 255.0
model = Sequential([
Conv2D(32, (3,3), input_shape=(32, 32, 3), padding="same", activation="relu", kernel_constraint=MaxNorm(3)),
Dropout(0.3),
Conv2D(32, (3,3), padding="same", activation="relu", kernel_constraint=MaxNorm(3)),
MaxPooling2D(),
Flatten(),
Dense(512, activation="relu", kernel_constraint=MaxNorm(3)),
Dropout(0.5),
Dense(10, activation="sigmoid")
])
model.compile(optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics="sparse_categorical_accuracy")
model.fit(X_train_scaled, y_train, validation_data=(X_test_scaled, y_test), epochs=25, batch_size=32)
这个网络应该能够达到70%左右的分类精度。这些图像是32×32像素的RGB颜色。它们分为10个不同的类别,标签是0到9的整数。
我们可以使用Keras的summary() 功能打印网络。
...
model.summary()
在这个网络中,屏幕上将会显示以下内容。
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 32, 32, 32) 896
dropout (Dropout) (None, 32, 32, 32) 0
conv2d_1 (Conv2D) (None, 32, 32, 32) 9248
max_pooling2d (MaxPooling2D (None, 16, 16, 32) 0
)
flatten (Flatten) (None, 8192) 0
dense (Dense) (None, 512) 4194816
dropout_1 (Dropout) (None, 512) 0
dense_1 (Dense) (None, 10) 5130
=================================================================
Total params: 4,210,090
Trainable params: 4,210,090
Non-trainable params: 0
_________________________________________________________________
在图像分类的网络中,典型的做法是在早期阶段由卷积层组成,并交错使用dropout和pooling层。在后期,卷积层的输出会被一些全连接层平铺和处理。
显示特征图
在上述网络中,我们使用了两个卷积层(Conv2D)。第一层的定义如下。
Conv2D(32, (3,3), input_shape=(32, 32, 3), padding="same", activation="relu", kernel_constraint=MaxNorm(3))
这意味着卷积层将有一个3×3的内核,适用于32×32像素和3个通道(RGB颜色)的输入图像。该层的输出将是32个通道。
为了理解卷积层,我们可以查看其内核。变量model 保持网络,我们可以用下面的方法找到第一个卷积层的内核。
...
print(model.layers[0].kernel)
并打印出来。
<tf.Variable 'conv2d/kernel:0' shape=(3, 3, 3, 32) dtype=float32, numpy=
array([[[[-2.30068922e-01, 1.41024575e-01, -1.93124503e-01,
-2.03153938e-01, 7.71819279e-02, 4.81446862e-01,
-1.11971676e-01, -1.75487325e-01, -4.01797555e-02,
...
4.64215249e-01, 4.10646647e-02, 4.99733612e-02,
-5.22711873e-02, -9.20209661e-03, -1.16479330e-01,
9.25614685e-02, -4.43541892e-02]]]], dtype=float32)>
我们可以通过比较上述输出中的名称conv2d 和model.summary() 的输出来判断model.layers[0] 是正确的层。该层的内核形状为(3, 3, 3, 32) ,分别为高度、宽度、输入通道和输出特征图。
假设内核是一个NumPy数组k 。卷积层将取其核k[:, :, 0, n] (一个3×3的数组)并应用于图像的第一个通道。然后在图像的第二个通道上应用k[:, :, 1, n] ,以此类推。之后,所有通道的卷积结果相加,成为输出的特征图n ,在这种情况下,n ,32个输出特征图将从0到31运行。
在Keras中,我们可以使用一个提取器模型提取每一层的输出。在下文中,我们用一张输入图片创建一个批处理并发送给网络。然后我们看一下第一个卷积层的特征图。
...
# Extract output from each layer
extractor = tf.keras.Model(inputs=model.inputs,
outputs=[layer.output for layer in model.layers])
features = extractor(np.expand_dims(X_train[7], 0))
# Show the 32 feature maps from the first layer
l0_features = features[0].numpy()[0]
fig, ax = plt.subplots(4, 8, sharex=True, sharey=True, figsize=(16,8))
for i in range(0, 32):
row, col = i//8, i%8
ax[row][col].imshow(l0_features[..., i])
plt.show()
上面的代码将打印出如下的特征图。
这是对应于下面的输入图像。
我们可以看到,我们称它们为特征图,因为它们是在突出输入图像的某些特征。一个特征是用一个小窗口来识别的(在本例中,在3×3像素的过滤器上)。输入图像有3个颜色通道。每个通道都有一个不同的过滤器,它们的结果被合并为一个输出特征。
我们可以类似地显示第二卷积层输出的特征图,如下所示。
...
# Show the 32 feature maps from the third layer
l2_features = features[2].numpy()[0]
fig, ax = plt.subplots(4, 8, sharex=True, sharey=True, figsize=(16,8))
for i in range(0, 32):
row, col = i//8, i%8
ax[row][col].imshow(l2_features[..., i])
plt.show()
其中显示如下。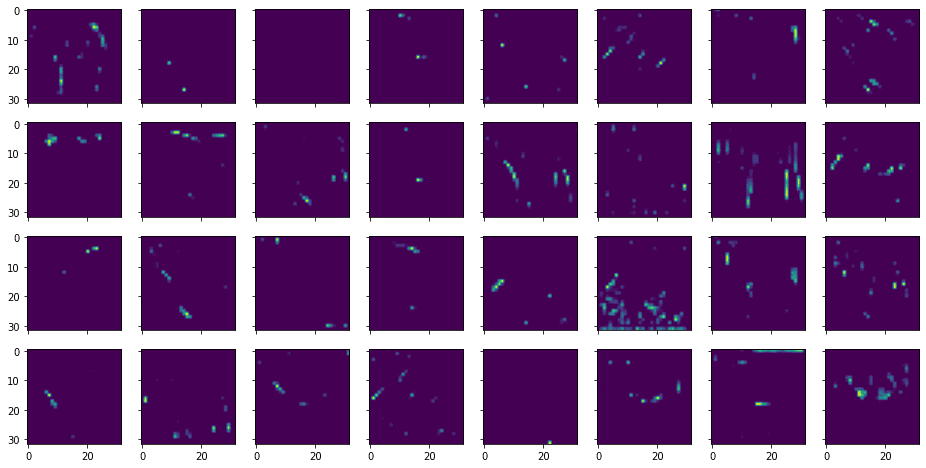
从上面可以看出,提取的特征比较抽象,不容易识别。
卷积层的效果
对卷积层来说,最重要的超参数是过滤器的大小。通常情况下,它是一个正方形,我们可以把它看作是观察输入图像的一个窗口或接受域。因此,图像的分辨率越高,我们就会期望有一个更大的过滤器。
另一方面,一个太大的过滤器会模糊详细的特征,因为所有通过过滤器的感受区的像素都会在输出的特征图中合并成一个像素。因此,对于过滤器的适当大小是有一个权衡的。
堆叠两个卷积层(中间没有任何其他层)相当于一个具有较大滤波器的单一卷积层。但这是现在典型的设计,使用两个带有小过滤器的层堆叠在一起,而不是一个带有较大过滤器的层,因为要训练的参数较少。
1×1的卷积层是个例外。它通常是作为网络的起始层出现的。这种卷积层的目的是将输入通道合并成一个,而不是转换像素。从概念上讲,这可以将彩色图像转换成灰度,但通常我们会进行多种转换方式,为网络创造更多的输入通道,而不仅仅是RGB。
还要注意的是,在上述网络中,我们使用的是Conv2D ,是一个二维过滤器。也有一个Conv3D ,用于三维过滤器。区别在于我们是对每个通道或特征图分别应用滤波器,还是将输入的特征图堆叠起来作为一个三维阵列,并对其全部应用一个滤波器。通常情况下使用前者,因为不考虑特征图堆叠的特定顺序是比较合理的。
摘要
在这篇文章中,你已经看到了我们如何将卷积神经网络的特征图可视化,以及它是如何提取特征图的。
具体来说,你学到了:
- 一个典型的卷积神经网络的结构
- 滤波器的大小对卷积层的影响是什么?
- 在网络中堆叠卷积层的效果是什么?
