

在使用神经网络和深度学习模型时,需要进行数据准备。在更复杂的物体识别任务中,也越来越需要[数据增强]
在这篇文章中,你将发现在用Keras在Python中开发和评估深度学习模型时,如何使用数据准备和数据增强与你的图像数据集。
读完这篇文章后,你会知道。
- 关于Keras提供的图像增强API以及如何将其用于你的模型。
- 如何执行特征标准化。
- 如何对你的图像进行ZCA白化。
- 如何用随机旋转、移位和翻转来增强数据。
- 如何将增强的图像数据保存到磁盘。
让我们开始吧
Keras图像增强API
与Keras的其他部分一样,图像增强API也是简单而强大的。
Keras提供了ImageDataGenerator类,定义了图像数据准备和增强的配置。这包括以下能力。
- 基于样本的标准化。
- 特征化的标准化。
- ZCA白化。
- 随机旋转、移位、剪切和翻转。
- 尺寸重排。
- 将增强的图像保存到磁盘。
一个增强的图像生成器可以被创建如下。
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator()
与其在内存中对你的整个图像数据集进行操作,该API被设计成由深度学习模型拟合过程迭代,为你及时创建增强的图像数据。这减少了你的内存开销,但在模型训练期间增加了一些额外的时间成本。
在你创建和配置了你的ImageDataGenerator之后,你必须在你的数据上进行拟合。这将计算出对你的图像数据实际执行转换所需的任何统计数据。你可以通过调用数据生成器上的**fit()**函数并将你的训练数据集传给它来完成这一工作。
datagen.fit(train)
数据生成器本身实际上是一个迭代器,当被要求时返回成批的图像样本。我们可以配置批次大小,并准备好数据生成器,通过调用**flow()**函数获得成批的图像。
X_batch, y_batch = datagen.flow(train, train, batch_size=32)
最后,我们可以利用数据生成器。我们必须调用**fit()函数,而不是在我们的模型上调用fit_generator()**函数,并传入数据生成器和所需的历时长度,以及用于训练的总历时数。
fit_generator(datagen, samples_per_epoch=len(train), epochs=100)
图像增强的比较点
现在你知道Keras中的图像增强API是如何工作的,让我们看看一些例子。
我们将在这些例子中使用MNIST的手写数字识别任务。首先,让我们看一下训练数据集中的前9张图片。
# Plot images
from tensorflow.keras.datasets import mnist
import matplotlib.pyplot as plt
# load dbata
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# create a grid of 3x3 images
fig, ax = plt.subplots(3, 3, sharex=True, sharey=True, figsize=(4,4))
for i in range(3):
for j in range(3):
ax[i][j].imshow(X_train[i*3+j], cmap=plt.get_cmap("gray"))
# show the plot
plt.show()
运行这个例子提供了以下图像,我们可以把它作为与下面例子中的图像准备和增强的比较点。

例子MNIST图像
特征标准化
也可以对整个数据集的像素值进行标准化。这被称为特征标准化,它反映了在表格数据集中每一列经常执行的标准化类型。
你可以通过将featurewise_center 和featurewise_std_normalization 参数设置为True来执行特征标准化,在ImageDataGenerator 类上。这些参数在默认情况下被设置为False。然而,最近版本的Keras在特征标准化上有一个bug,即平均数和标准差是在所有像素上计算的。如果你使用ImageDataGenerator 类中的fit() 函数,你会看到一个类似于上面的图像。
# Standardize images across the dataset, mean=0, stdev=1
from tensorflow.keras.datasets import mnist
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# reshape to be [samples][width][height][channels]
X_train = X_train.reshape((X_train.shape[0], 28, 28, 1))
X_test = X_test.reshape((X_test.shape[0], 28, 28, 1))
# convert from int to float
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# define data preparation
datagen = ImageDataGenerator(featurewise_center=True, featurewise_std_normalization=True)
# fit parameters from data
datagen.fit(X_train)
# configure batch size and retrieve one batch of images
for X_batch, y_batch in datagen.flow(X_train, y_train, batch_size=9, shuffle=False):
print(X_batch.min(), X_batch.mean(), X_batch.max())
# create a grid of 3x3 images
fig, ax = plt.subplots(3, 3, sharex=True, sharey=True, figsize=(4,4))
for i in range(3):
for j in range(3):
ax[i][j].imshow(X_batch[i*3+j], cmap=plt.get_cmap("gray"))
# show the plot
plt.show()
break
例如,上面打印的批次中的最小值、平均值和最大值是
-0.42407447 -0.04093817 2.8215446
而显示的图像如下。

来自特征标准化的图像
解决办法是手动计算特征标准化。每个像素都应该有一个单独的平均值和标准差,它应该在不同的样本中计算,但与同一样本中的其他像素无关。我们只需要用我们自己的计算方法来取代fit() 函数。
# Standardize images across the dataset, every pixel has mean=0, stdev=1
from tensorflow.keras.datasets import mnist
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# reshape to be [samples][width][height][channels]
X_train = X_train.reshape((X_train.shape[0], 28, 28, 1))
X_test = X_test.reshape((X_test.shape[0], 28, 28, 1))
# convert from int to float
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# define data preparation
datagen = ImageDataGenerator(featurewise_center=True, featurewise_std_normalization=True)
# fit parameters from data
datagen.mean = X_train.mean(axis=0)
datagen.std = X_train.std(axis=0)
# configure batch size and retrieve one batch of images
for X_batch, y_batch in datagen.flow(X_train, y_train, batch_size=9, shuffle=False):
print(X_batch.min(), X_batch.mean(), X_batch.max())
# create a grid of 3x3 images
fig, ax = plt.subplots(3, 3, sharex=True, sharey=True, figsize=(4,4))
for i in range(3):
for j in range(3):
ax[i][j].imshow(X_batch[i*3+j], cmap=plt.get_cmap("gray"))
# show the plot
plt.show()
break
打印出来的最小值、平均值和最大值现在有了更大的范围。
-1.2742625 -0.028436039 17.46127
运行这个例子,你可以看到效果是不同的,似乎是不同数字的变暗和变亮。

标准化特征 MNIST图像
ZCA增白
图像的白化变换是一种线性代数操作,可以减少像素图像矩阵中的冗余。
减少图像中的冗余是为了更好地突出图像中的结构和特征给学习算法。
通常情况下,图像美白是使用主成分分析(PCA)技术进行的。最近,一种被称为ZCA的替代显示出更好的效果,其结果是转换后的图像保留了所有的原始维度,而且与PCA不同,转换后的图像看起来仍然像它们的原件。准确地说,白化是将每张图像转换为白噪声矢量,即矢量中的每个元素的均值为零,标准导数为单位,在统计上相互独立。
你可以通过设置zca_whitening 参数为True来进行ZCA白化转换。但是由于与特征标准化相同的问题,我们必须首先对我们的输入数据分别进行零中心化。
# ZCA Whitening
from tensorflow.keras.datasets import mnist
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# reshape to be [samples][width][height][channels]
X_train = X_train.reshape((X_train.shape[0], 28, 28, 1))
X_test = X_test.reshape((X_test.shape[0], 28, 28, 1))
# convert from int to float
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# define data preparation
datagen = ImageDataGenerator(featurewise_center=True, featurewise_std_normalization=True, zca_whitening=True)
# fit parameters from data
X_mean = X_train.mean(axis=0)
datagen.fit(X_train - X_mean)
# configure batch size and retrieve one batch of images
for X_batch, y_batch in datagen.flow(X_train - X_mean, y_train, batch_size=9, shuffle=False):
print(X_batch.min(), X_batch.mean(), X_batch.max())
# create a grid of 3x3 images
fig, ax = plt.subplots(3, 3, sharex=True, sharey=True, figsize=(4,4))
for i in range(3):
for j in range(3):
ax[i][j].imshow(X_batch[i*3+j].reshape(28,28), cmap=plt.get_cmap("gray"))
# show the plot
plt.show()
break
运行这个例子,你可以看到图像中相同的总体结构,以及每个数字的轮廓是如何被突出的。
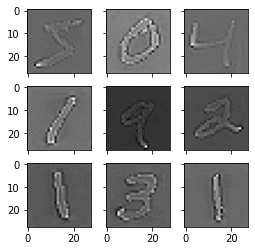
ZCA美白MNIST图像
随机旋转
有时,你的样本数据中的图像在场景中可能有不同的、不同的旋转。
你可以通过在训练期间人为地随机旋转数据集中的图像来训练你的模型以更好地处理图像的旋转。
下面的例子通过设置rotation_range参数创建了MNIST数字的随机旋转,最大旋转角度为90度。
# Random Rotations
from tensorflow.keras.datasets import mnist
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# reshape to be [samples][width][height][channels]
X_train = X_train.reshape((X_train.shape[0], 28, 28, 1))
X_test = X_test.reshape((X_test.shape[0], 28, 28, 1))
# convert from int to float
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# define data preparation
datagen = ImageDataGenerator(rotation_range=90)
# configure batch size and retrieve one batch of images
for X_batch, y_batch in datagen.flow(X_train, y_train, batch_size=9, shuffle=False):
# create a grid of 3x3 images
fig, ax = plt.subplots(3, 3, sharex=True, sharey=True, figsize=(4,4))
for i in range(3):
for j in range(3):
ax[i][j].imshow(X_batch[i*3+j].reshape(28,28), cmap=plt.get_cmap("gray"))
# show the plot
plt.show()
break
运行这个例子,你可以看到图像被左右旋转到了90度的极限。这对这个问题没有帮助,因为MNIST的数字有一个正常化的方向,但是当从照片中学习时,这个变换可能会有帮助,因为在照片中的物体可能有不同的方向。

MNIST图像的随机旋转
随机移位
你的图像中的物体可能不在画面的中心。它们可能以各种不同的方式偏离中心。
你可以通过人为地创建训练数据的移位版本来训练你的深度学习网络,使其能够预期并当前处理偏离中心的物体。Keras支持通过width_shift_range 和height_shift_range 参数对训练数据进行单独的水平和垂直随机移位。
# Random Shifts
from tensorflow.keras.datasets import mnist
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# reshape to be [samples][width][height][channels]
X_train = X_train.reshape((X_train.shape[0], 28, 28, 1))
X_test = X_test.reshape((X_test.shape[0], 28, 28, 1))
# convert from int to float
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# define data preparation
shift = 0.2
datagen = ImageDataGenerator(width_shift_range=shift, height_shift_range=shift)
# configure batch size and retrieve one batch of images
for X_batch, y_batch in datagen.flow(X_train, y_train, batch_size=9, shuffle=False):
# create a grid of 3x3 images
fig, ax = plt.subplots(3, 3, sharex=True, sharey=True, figsize=(4,4))
for i in range(3):
for j in range(3):
ax[i][j].imshow(X_batch[i*3+j].reshape(28,28), cmap=plt.get_cmap("gray"))
# show the plot
plt.show()
break
运行这个例子可以创建数字的移位版本。同样,这对MNIST来说不是必需的,因为手写的数字已经居中了,但是你可以看到这在更复杂的问题领域是多么有用。

随机移位的MNIST图像
随机翻转
对你的图像数据的另一种增强,可以提高大型复杂问题的性能,就是在你的训练数据中创建随机翻转的图像。
Keras支持使用vertical_flip 和horizontal_flip 参数沿垂直和水平轴进行随机翻转。
# Random Flips
from tensorflow.keras.datasets import mnist
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# reshape to be [samples][width][height][channels]
X_train = X_train.reshape((X_train.shape[0], 28, 28, 1))
X_test = X_test.reshape((X_test.shape[0], 28, 28, 1))
# convert from int to float
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# define data preparation
datagen = ImageDataGenerator(horizontal_flip=True, vertical_flip=True)
# configure batch size and retrieve one batch of images
for X_batch, y_batch in datagen.flow(X_train, y_train, batch_size=9, shuffle=False):
# create a grid of 3x3 images
fig, ax = plt.subplots(3, 3, sharex=True, sharey=True, figsize=(4,4))
for i in range(3):
for j in range(3):
ax[i][j].imshow(X_batch[i*3+j].reshape(28,28), cmap=plt.get_cmap("gray"))
# show the plot
plt.show()
break
运行这个例子,你可以看到翻转的数字。翻转数字是没有用的,因为它们总是有正确的左右方向,但这对于场景中物体的照片可能有不同的方向的问题是有用的。

随机翻转的MNIST图像
将增强的图像保存到文件中
数据准备和增强是由Keras及时完成的。
这在内存方面是有效的,但你可能需要在训练期间使用的确切图像。例如,也许你想以后用不同的软件包来使用它们,或者只生成一次,在多个不同的深度学习模型或配置上使用它们。
Keras允许你保存训练期间生成的图像。在训练之前,可以向flow() 函数指定目录、文件名前缀和图像文件类型。然后,在训练期间,生成的图像将被写入文件。
下面的例子演示了这一点,并将9张图像写入一个 "images" 子目录,其前缀为 "aug" ,文件类型为PNG。
# Save augmented images to file
from tensorflow.keras.datasets import mnist
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
# load data
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# reshape to be [samples][width][height][channels]
X_train = X_train.reshape((X_train.shape[0], 28, 28, 1))
X_test = X_test.reshape((X_test.shape[0], 28, 28, 1))
# convert from int to float
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# define data preparation
datagen = ImageDataGenerator(horizontal_flip=True, vertical_flip=True)
# configure batch size and retrieve one batch of images
for X_batch, y_batch in datagen.flow(X_train, y_train, batch_size=9, shuffle=False,
save_to_dir='images', save_prefix='aug', save_format='png'):
# create a grid of 3x3 images
fig, ax = plt.subplots(3, 3, sharex=True, sharey=True, figsize=(4,4))
for i in range(3):
for j in range(3):
ax[i][j].imshow(X_batch[i*3+j].reshape(28,28), cmap=plt.get_cmap("gray"))
# show the plot
plt.show()
break
运行这个例子你可以看到,图像只有在生成时才会被写入。
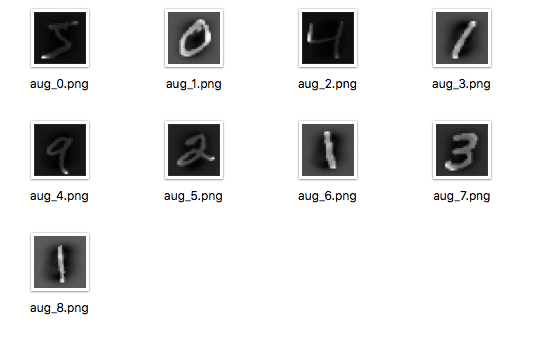
增强的MNIST图像被保存到文件中
使用Keras增强图像数据的提示
图像数据的独特之处在于,你可以查看数据和数据的转换副本,并迅速了解你的模型可能会如何感知它。
下面是一些从图像数据准备和增强深度学习中获得最大收益的提示。
- 审查数据集:花一些时间来详细地审查你的数据集。看看这些图像。注意那些可能有利于你的模型训练过程的图像准备和增强,比如需要处理场景中物体的不同移动、旋转或翻转。
- 审查增强:在进行了增强之后,审查样本图像。从智力上知道你在使用什么图像变换是一回事,看实例则是另一回事。审查你正在使用的单个增强的图像,以及你计划使用的全套增强的图像。你可能会看到简化或进一步加强你的模型训练过程的方法。
- 评估一系列的变换:尝试一个以上的图像数据准备和增强方案。通常情况下,你会对一个你认为没有好处的数据准备方案的结果感到惊讶。
总结
在这篇文章中,你发现了图像数据准备和增强的问题。
