

Node.js中的错误处理综合指南
错误在每个应用程序中都会发生。开发人员必须决定:你是否编写代码来处理错误?抑制它?通知用户?向团队报告?在这篇文章中,我将带领你了解JavaScript错误系统的各个方面。我将向你展示如何处理错误,并讨论现实世界中的适当选择。
如果你一直在写 "Hello world "以上的程序,你可能对编程中的错误概念很熟悉。它们是你代码中的错误,通常被称为 "bug",会导致程序失败或出现意外的行为。与Go和Rust等一些语言不同的是,在这些语言中,你不得不与潜在的错误进行每一步的互动,而在JavaScript和Node.js中,没有一个连贯的错误处理策略也是可能的。
不过也不必如此,因为一旦你熟悉了用于创建、传递和处理潜在错误的模式,Node.js的错误处理就会相当简单。本文旨在向你介绍这些模式,这样你就可以使你的程序更加健壮,确保在将你的应用程序部署到生产中之前发现潜在的错误并进行适当的处理!
什么是Node.js中的错误
Node.js中的错误是Error 对象的任何实例。常见的例子包括内置的错误类,如ReferenceError,RangeError,TypeError,URIError,EvalError, 和SyntaxError 。用户定义的错误也可以通过扩展基础Error 对象、内置错误类或其他自定义错误来创建。当以这种方式创建错误时,你应该传递一个描述错误的消息字符串。这个消息可以通过对象上的message 属性访问。Error 对象还包含一个name 和一个stack 属性,分别表示错误的名称和代码中创建错误的点。
const userError = new TypeError("Something happened!");
console.log(userError.name); // TypeError
console.log(userError.message); // Something happened!
console.log(userError.stack);
/*TypeError: Something happened!
at Object.<anonymous> (/home/ayo/dev/demo/main.js:2:19)
<truncated for brevity>
at node:internal/main/run_main_module:17:47 */
一旦你有了一个Error 对象,你就可以把它传递给一个函数或从一个函数中返回它。你也可以throw ,这将导致Error 对象成为一个异常。一旦你抛出一个错误,它就会在堆栈中冒泡,直到它被某个地方捕获。如果你没有捕捉到它,它就会变成一个未捕捉的异常,这可能会导致你的应用程序崩溃
如何传递错误
从一个JavaScript函数中传递错误的适当方式是不同的,这取决于该函数是执行同步还是异步操作。在本节中,我将详细介绍从Node.js应用程序中的函数传递错误的四种常见模式。
1.异常
函数传递错误的最常见方式是抛出错误。当你抛出一个错误时,它就成为一个异常,需要在堆栈的某个地方用try/catch 块来捕获。如果错误被允许在堆栈上冒泡而不被捕获,它就会变成一个uncaughtException ,从而导致应用程序过早退出。例如,内置的JSON.parse() 方法在其字符串参数不是有效的JSON对象时抛出一个错误。
function parseJSON(data) {
return JSON.parse(data);
}
try {
const result = parseJSON('A string');
} catch (err) {
console.log(err.message); // Unexpected token A in JSON at position 0
}
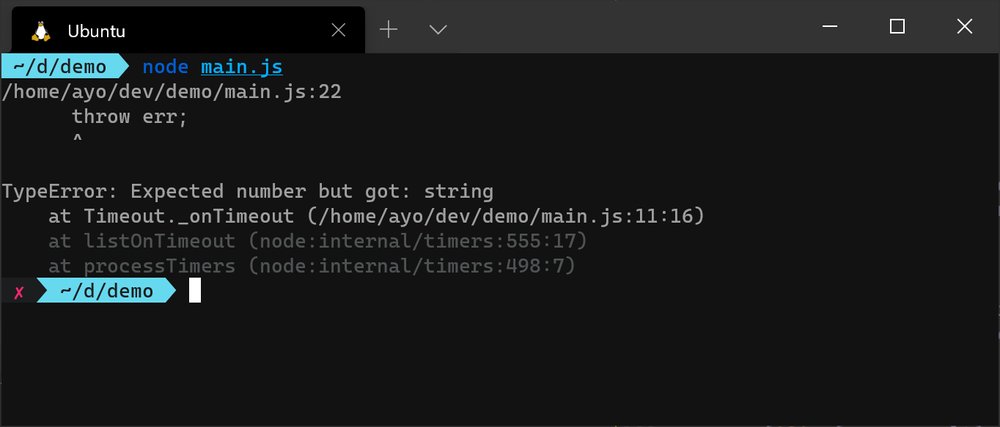
要在你的函数中利用这种模式,你所需要做的就是在一个错误的实例前添加throw 关键字。这种错误报告和处理的模式对于执行同步操作的函数来说是习以为常的。
function square(num) {
if (typeof num !== 'number') {
throw new TypeError(`Expected number but got: ${typeof num}`);
}
return num * num;
}
try {
square('8');
} catch (err) {
console.log(err.message); // Expected number but got: string
}
2.错误优先的回调
由于其异步性,Node.js在错误处理方面大量使用回调函数。回调函数作为参数传递给另一个函数,并在该函数完成其工作后执行。如果你写过很长一段时间的JavaScript代码,你可能知道回调模式在整个JavaScript代码中被大量使用。
Node.js在其大多数异步方法中使用错误优先的回调约定,以确保在使用操作结果之前正确检查错误。这个回调函数通常是启动异步操作的函数的最后一个参数,当发生错误或操作的结果可用时,它被调用一次。它的签名如下所示。
function (err, result) {}
第一个参数是为错误对象保留的。如果在异步操作的过程中发生了错误,它将通过err 参数获得,result 将是undefined. 然而,如果没有发生错误,err 将是null 或undefined ,而result 将包含操作的预期结果。这种模式可以通过使用内置的fs.readFile() 方法读取一个文件的内容来证明。
const fs = require('fs');
fs.readFile('/path/to/file.txt', (err, result) => {
if (err) {
console.error(err);
return;
}
// Log the file contents if no error
console.log(result);
});
正如你所看到的,readFile() 方法期望一个回调函数作为它的最后一个参数,这遵守了前面讨论的错误优先的函数签名。在这种情况下,如果没有发生错误,result 参数包含读取的文件内容。否则,它是undefined ,而err 参数被填充为一个错误对象,包含有关问题的信息(例如,未找到文件或权限不足)。
一般来说,利用这种回调模式来传递错误的方法不能知道他们产生的错误对你的应用程序有多重要。它可能是严重的或微不足道的。错误不是由它自己决定的,而是由你来处理的。重要的是要控制回调函数的内容流,在试图访问操作结果之前总是要检查是否有错误。忽视错误是不安全的,在检查错误之前,你不应该相信result 的内容。
如果你想在自己的异步函数中使用这种错误优先的回调模式,你所需要做的就是接受一个函数作为最后一个参数,并以下面所示的方式调用它。
function square(num, callback) {
if (typeof callback !== 'function') {
throw new TypeError(`Callback must be a function. Got: ${typeof callback}`);
}
// simulate async operation
setTimeout(() => {
if (typeof num !== 'number') {
// if an error occurs, it is passed as the first argument to the callback
callback(new TypeError(`Expected number but got: ${typeof num}`));
return;
}
const result = num * num;
// callback is invoked after the operation completes with the result
callback(null, result);
}, 100);
}
这个square 函数的任何调用者都需要传递一个回调函数来访问其结果或错误。注意,如果回调参数不是一个函数,就会发生运行时异常。
square('8', (err, result) => {
if (err) {
console.error(err)
return
}
console.log(result);
});
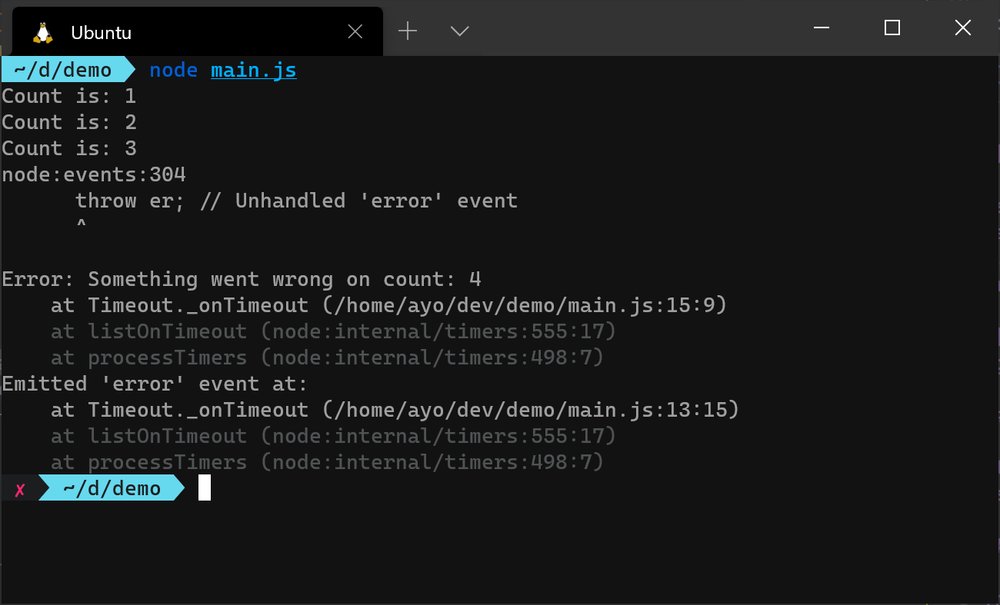
你不需要直接在回调函数中处理错误。你可以通过把它传递给一个不同的回调函数来在堆栈中传播它,但要确保不要从函数中抛出一个异常,因为它不会被捕获,即使你把代码包围在一个try/catch 块中。一个异步异常是无法捕捉的,因为周围的try/catch 块在回调执行之前就已经退出。因此,异常会传播到堆栈顶部,导致你的应用程序崩溃,除非为process.on('uncaughtException') 注册了一个处理程序,这将在后面讨论。
try {
square('8', (err, result) => {
if (err) {
throw err; // not recommended
}
console.log(result);
});
} catch (err) {
// This won't work
console.error("Caught error: ", err);
}
3.诺言拒绝
答应是在Node.js中执行异步操作的现代方式,现在一般比回调更受欢迎,因为这种方法有更好的流程,符合我们分析程序的方式,特别是async/await 模式。任何利用错误优先回调进行异步错误处理的Node.js API都可以使用内置的util.promisify() 方法转换为诺言。例如,这里是如何使fs.readFile() 方法利用承诺的。
const fs = require('fs');
const util = require('util');
const readFile = util.promisify(fs.readFile);
readFile 变量是fs.readFile() 的承诺版本,其中承诺拒绝被用来报告错误。这些错误可以通过链上的catch 方法来捕获,如下图所示。
readFile('/path/to/file.txt')
.then((result) => console.log(result))
.catch((err) => console.error(err));
你也可以在一个async 函数中使用承诺化的API,比如下图所示。这是现代JavaScript中使用承诺的主要方式,因为代码读起来像同步代码,而且可以使用熟悉的try/catch 机制来处理错误。在异步方法之前使用await 是很重要的,这样在函数恢复执行之前,承诺就会被解决(实现或拒绝)。如果承诺被拒绝,await 表达式会抛出被拒绝的值,随后在周围的catch 块中被捕获。
(async function callReadFile() {
try {
const result = await readFile('/path/to/file.txt');
console.log(result);
} catch (err) {
console.error(err);
}
})();
你可以在你的异步函数中利用承诺,从函数中返回一个承诺并将函数代码放在承诺回调中。如果有一个错误,reject ,用一个Error 对象。否则,resolve 诺言与结果,这样它就可以在链式.then 方法中访问,或者在使用async/await 时直接作为异步函数的值。
function square(num) {
return new Promise((resolve, reject) => {
setTimeout(() => {
if (typeof num !== 'number') {
reject(new TypeError(`Expected number but got: ${typeof num}`));
}
const result = num * num;
resolve(result);
}, 100);
});
}
square('8')
.then((result) => console.log(result))
.catch((err) => console.error(err));
4.事件发射器
在处理可能产生多个错误或结果的长期运行的异步操作时,可以使用的另一种模式是,从函数中返回一个EventEmitter,并为成功和失败的情况发射一个事件。下面是这个代码的一个例子。
const { EventEmitter } = require('events');
function emitCount() {
const emitter = new EventEmitter();
let count = 0;
// Async operation
const interval = setInterval(() => {
count++;
if (count % 4 == 0) {
emitter.emit(
'error',
new Error(`Something went wrong on count: ${count}`)
);
return;
}
emitter.emit('success', count);
if (count === 10) {
clearInterval(interval);
emitter.emit('end');
}
}, 1000);
return emitter;
}
emitCount() 函数返回一个新的事件发射器,报告异步操作中的成功和失败事件。该函数增加了count 变量,每秒钟发射一个success 事件,如果count 能被4 整除,则发射一个error 事件。当count 达到10时,会发出一个end 事件。这种模式允许在结果到来时进行流式处理,而不是等到整个操作完成。
下面是你如何监听和响应从emitCount() 函数中发出的每个事件。
const counter = emitCount();
counter.on('success', (count) => {
console.log(`Count is: ${count}`);
});
counter.on('error', (err) => {
console.error(err.message);
});
counter.on('end', () => {
console.info('Counter has ended');
});
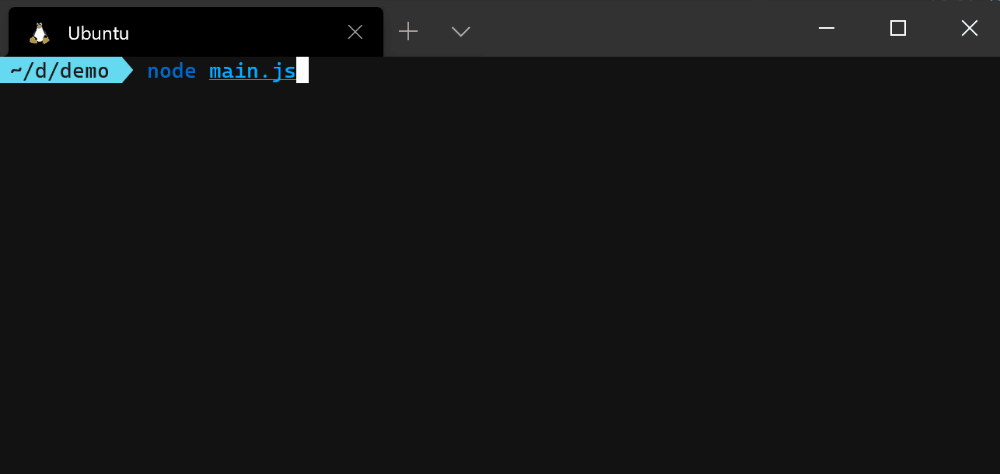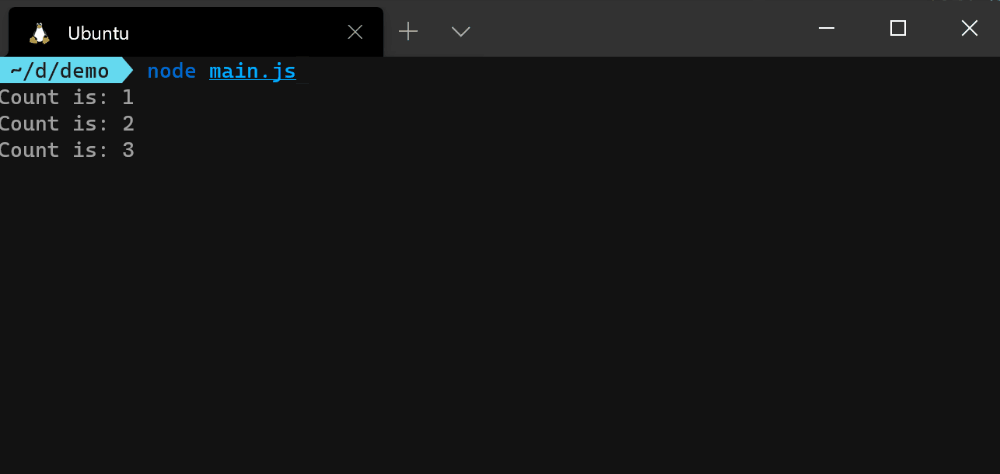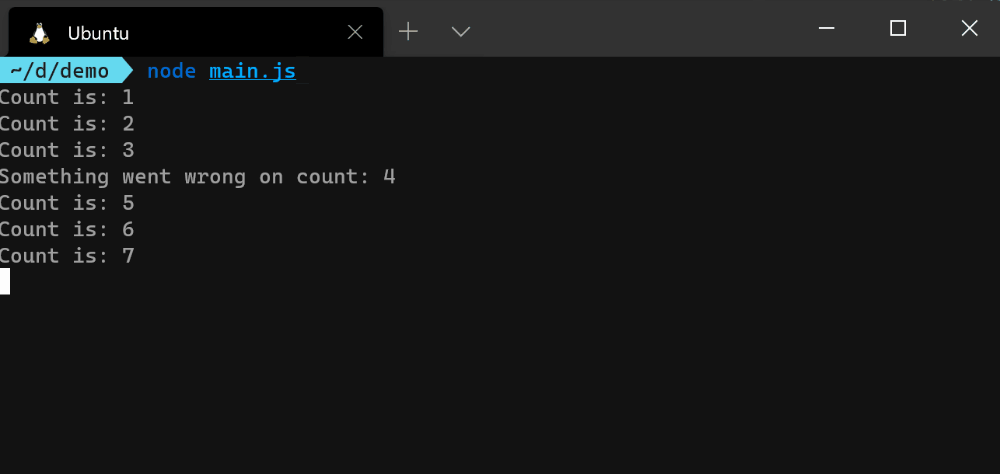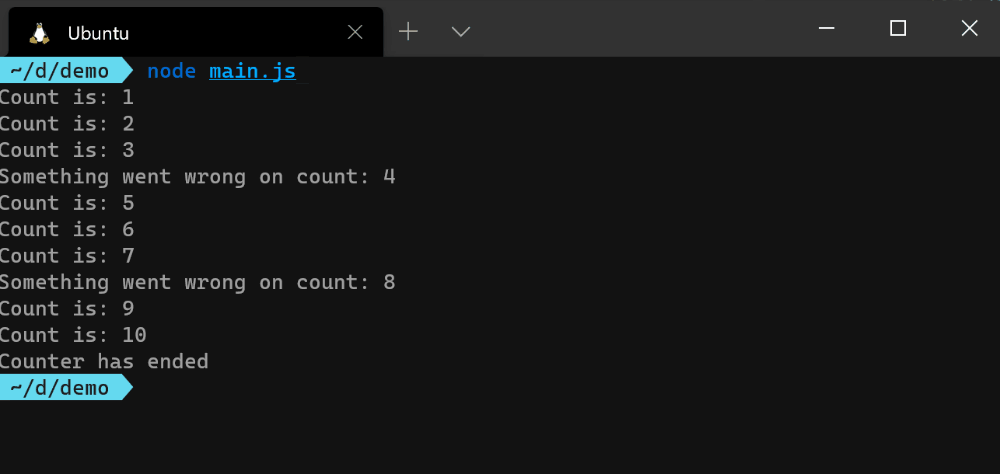
正如你从上面的图片中看到的,每个事件监听器的回调函数在事件发出后就被独立执行。error 事件在Node.js中是一个特殊情况,因为,如果没有它的监听器,Node.js进程就会崩溃。你可以注释掉上面的error 事件监听器,然后运行程序,看看会发生什么。
扩展错误对象
使用内置的错误类或Error 对象的通用实例,通常不够精确,无法传达所有不同的错误类型。因此,有必要创建自定义的错误类来更好地反映你的应用程序中可能发生的错误类型。例如,你可以有一个ValidationError ,用于验证用户输入时发生的错误,DatabaseError ,用于数据库操作,TimeoutError ,用于超过指定超时的操作,等等。
扩展了Error 对象的自定义错误类将保留基本的错误属性,如message,name, 和stack ,但它们也可以有自己的属性。例如,一个ValidationError ,可以通过添加有意义的属性来增强,比如导致错误的输入部分。基本上,你应该包括足够的信息,以便错误处理程序正确处理错误或构建自己的错误信息。
下面是如何在Node.js中扩展内置的Error 对象。
class ApplicationError extends Error {
constructor(message) {
super(message);
// name is set to the name of the class
this.name = this.constructor.name;
}
}
class ValidationError extends ApplicationError {
constructor(message, cause) {
super(message);
this.cause = cause
}
}
上面的ApplicationError 类是应用程序的通用错误,而ValidationError 类代表验证用户输入时发生的任何错误。它继承自ApplicationError 类,并通过一个cause 属性来指定触发错误的输入。你可以在你的代码中使用自定义错误,就像你使用普通错误一样。例如,你可以throw 。
function validateInput(input) {
if (!input) {
throw new ValidationError('Only truthy inputs allowed', input);
}
return input;
}
try {
validateInput(userJson);
} catch (err) {
if (err instanceof ValidationError) {
console.error(`Validation error: ${err.message}, caused by: ${err.cause}`);
return;
}
console.error(`Other error: ${err.message}`);
}
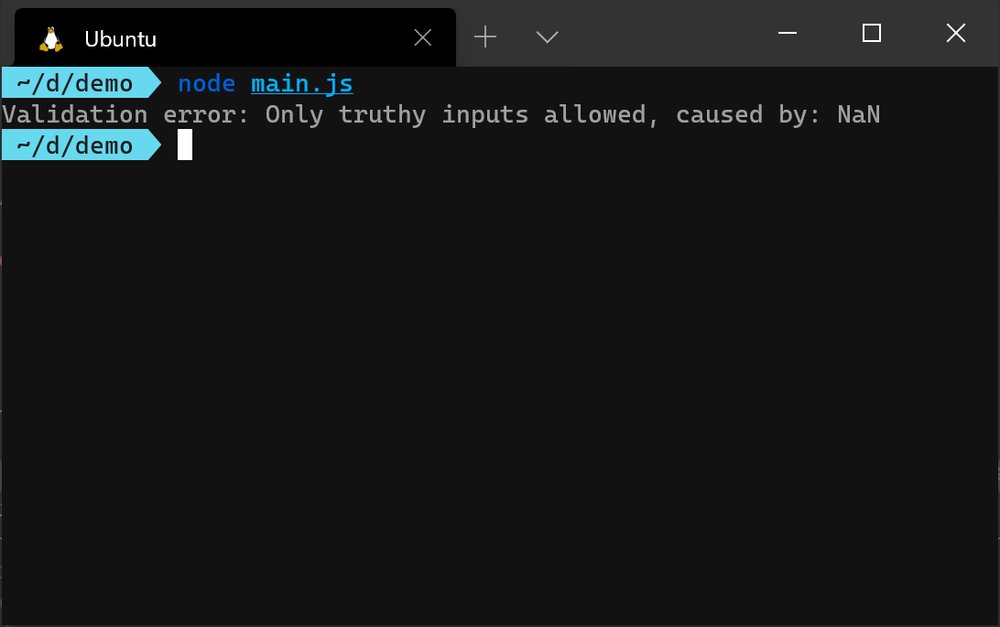
instanceof 关键字应被用来检查特定的错误类型,如上所示。不要使用错误的名称来检查类型,如err.name === 'ValidationError' ,因为如果错误是由ValidationError 的子类派生出来的,它就不起作用。
错误的类型
区分Node.js应用程序中可能出现的不同类型的错误是有益的。一般来说,错误可以归纳为两大类:程序员错误和操作问题。一个函数的错误或不正确的参数是第一种问题的例子,而在处理外部API时出现的瞬时故障则坚决属于第二类。
1.操作性错误
操作性错误主要是指在应用程序执行过程中可能发生的预期错误。它们不一定是bug,而是会扰乱程序执行流程的外部环境。在这种情况下,错误的全部影响可以被理解并得到适当的处理。Node.js中的一些操作错误的例子包括如下。
- 一个API请求由于某种原因而失败(例如,服务器宕机或超过了速率限制)。
- 数据库连接丢失,可能是由于网络连接出现故障。
- 操作系统不能满足你打开一个文件或向其写入的请求。
- 用户向服务器发送了无效的输入,例如无效的电话号码或电子邮件地址。
这些情况并不是由于应用程序代码中的错误而产生的,但必须正确处理这些情况。否则,它们可能导致更严重的问题。
2.程序员错误
程序员错误是程序的逻辑或语法错误,只能通过改变源代码来纠正。这些类型的错误不能被处理,因为根据定义,它们是程序中的错误。程序员错误的一些例子包括。
- 语法错误,例如没有关闭大括号。
- 类型错误,当你试图做一些非法的事情时,例如对类型不匹配的操作数进行操作。
- 调用函数时的错误参数。
- 当你拼错了一个变量、函数或属性的名称时,出现参考错误。
- 试图访问一个超过数组末端的位置。
- 未能处理一个操作错误。
操作性错误处理
操作性错误大多是可以预测的,所以在开发过程中必须对它们进行预测和说明。基本上,处理这些类型的错误需要考虑一个操作是否会失败,为什么会失败,以及如果失败了应该怎么办。让我们考虑一下在Node.js中处理操作错误的一些策略。
1.向栈上报告错误
在许多情况下,适当的行动是停止程序的执行流程,清理任何未完成的进程,并在堆栈上报告错误,以便适当地处理它。当发生错误的函数在堆栈的下方,没有足够的信息来直接处理错误时,这通常是处理错误的正确方法。报告错误可以通过本文前面讨论的任何一种错误传递方法进行。
2.重试操作
对外部服务的网络请求有时可能会失败,即使该请求完全有效。这可能是由于暂时性的故障,如果出现网络故障或服务器过载,就会出现这种情况。这样的问题通常是短暂的,所以与其立即报告错误,不如重试几次,直到请求成功或达到最大重试次数为止。首先要考虑的是确定重试请求是否合适。例如,如果初始响应的HTTP状态码是500、503或429,在短暂延迟后重试请求可能是有利的。
你可以检查响应中是否存在Retry-AfterHTTP头。这个头表示在提出后续请求之前需要等待的确切时间。如果Retry-After 标头不存在,你需要延迟后续请求,并逐步增加每次连续重试的延迟。这就是所谓的[指数式回退]策略。你还需要决定最大的延迟间隔以及在放弃之前重试多少次请求。在这一点上,你应该通知呼叫者,目标服务不可用。
3.向客户端发送错误信息
在处理来自用户的外部输入时,应该假定输入的内容默认是坏的。因此,在启动任何流程之前,首先要做的是验证输入,并及时向用户报告任何错误,以便纠正和重新发送。在传递客户错误时,要确保包括客户需要的所有信息,以构建一个对用户有意义的错误信息。
4.中止程序
在无法恢复的系统错误的情况下,唯一合理的做法是记录错误并立即终止程序。如果异常在JavaScript层无法恢复,你甚至可能无法优雅地关闭服务器。在这一点上,可能需要一个系统管理员来研究这个问题,并在程序再次启动之前修复它。
防止程序员错误
由于其性质,程序员错误不能被处理;它们是程序中由于代码或逻辑被破坏而产生的错误,随后必须被纠正。然而,有几件事你可以做,以大大减少它们在你的应用程序中出现的频率。
1.采用TypeScript
TypeScript是JavaScript的一个强类型超集。它的主要设计目标是静态地识别可能出现错误的结构,而不会有任何运行时的惩罚。通过在你的项目中采用TypeScript(使用最严格的编译器选项),你可以在编译时消除一大类程序员错误。例如,在对错误进行事后分析后,估计Airbnb代码库中38%的错误是可以用TypeScript预防的。
当你把整个项目迁移到TypeScript时,像 "undefined 不是一个函数 "这样的错误、语法错误或引用错误应该在你的代码库中不再存在。值得庆幸的是,这并不像听起来那么令人生畏。将你的整个Node.js应用程序迁移到TypeScript可以逐步完成,这样你就可以在代码库的关键部分立即开始收获成果了。如果你打算一次性完成迁移,你也可以采用ts-migrate这样的工具。
2.定义不良参数的行为
许多程序员的错误都是由传递不良参数造成的。这不仅可能是由于明显的错误,比如传递一个字符串而不是数字,也可能是由于细微的错误,比如当一个函数参数的类型正确,但超出了函数可以处理的范围。当程序运行时,函数被这样调用,它可能会无声地失败,产生一个错误的值,如NaN 。当失败最终被注意到时(通常是在穿越了其他几个函数之后),可能很难找到它的源头。
你可以通过定义它们的行为来处理坏的参数,要么抛出一个错误,要么返回一个特殊的值,如null,undefined, 或-1 ,当问题可以在本地处理时。前者是JSON.parse() 使用的方法,如果要解析的字符串不是有效的JSON,它会抛出一个SyntaxError 异常,而string.indexOf() 方法是后者的一个例子。无论你选择哪种方法,都要确保记录函数如何处理错误,以便调用者知道该怎么做。
3.自动测试
就其本身而言,JavaScript语言并不能帮助你发现程序逻辑中的错误,所以你必须运行程序来确定它是否按预期工作。自动化测试套件的存在使你更有可能发现并修复各种程序员的错误,尤其是逻辑错误。它们也有助于确定一个函数如何处理非典型值。使用测试框架,如Jest或Mocha,是开始对Node.js应用程序进行单元测试的一个好方法。
未捕获的异常和未处理的拒绝承诺
未捕获的异常和未处理的承诺拒绝是由程序员的错误造成的,这些错误分别是由于未能捕获抛出的异常和承诺拒绝。当应用程序中某处抛出的异常在到达事件循环之前没有被捕获时,就会发出uncaughtException 事件。如果检测到一个未捕获的异常,应用程序将立即崩溃,但你可以为这个事件添加一个处理程序来覆盖这个行为。事实上,许多人把这作为最后的手段,吞下错误,以便应用程序可以继续运行,就像什么都没有发生一样。
// unsafe
process.on('uncaughtException', (err) => {
console.error(err);
});
然而,这是对该事件的不正确使用,因为未捕获异常的存在表明应用程序处于未定义状态。因此,试图在没有从错误中恢复的情况下恢复正常被认为是不安全的,可能会导致进一步的问题,如内存泄漏和挂起的套接字。uncaughtException 处理程序的适当使用是清理任何分配的资源,关闭连接,并在退出进程之前记录错误,以便以后评估。
// better
process.on('uncaughtException', (err) => {
Honeybadger.notify(error); // log the error in a permanent storage
// attempt a gracefully shutdown
server.close(() => {
process.exit(1); // then exit
});
// If a graceful shutdown is not achieved after 1 second,
// shut down the process completely
setTimeout(() => {
process.abort(); // exit immediately and generate a core dump file
}, 1000).unref()
});
同样地,当一个被拒绝的承诺没有被catch 块处理时,unhandledRejection 事件就会被发出。与uncaughtException 不同,这些事件不会导致应用程序立即崩溃。然而,在未来的Node.js版本中,未处理的拒绝承诺已经被弃用,并可能立即终止进程。你可以通过一个unhandledRejection 事件监听器来跟踪未处理的承诺拒绝,如下图所示。
process.on('unhandledRejection', (reason, promise) => {
Honeybadger.notify({
message: 'Unhandled promise rejection',
params: {
promise,
reason,
},
});
server.close(() => {
process.exit(1);
});
setTimeout(() => {
process.abort();
}, 1000).unref()
});
你应该始终使用一个进程管理器来运行你的服务器,在崩溃的情况下自动重启它们。一个常见的是PM2,但你在Linux上也有systemd 或upstart ,Docker用户可以使用其重启策略。一旦这样做了,可靠的服务就会几乎立即恢复,而且你还会有未捕获异常的细节,这样就可以及时调查和纠正了。你可以更进一步,运行一个以上的进程,并采用一个负载平衡器来分配进入的请求。这将有助于防止在其中一个实例暂时丢失的情况下出现停机。
集中的错误报告
任何错误处理策略,如果没有一个强大的日志策略,对你正在运行的应用程序来说都是不完整的。当故障发生时,通过记录尽可能多的问题信息来了解故障发生的原因是很重要的。集中这些日志使你很容易获得你的应用程序的全部可见性。你可以对你的错误进行分类和过滤,看到最主要的问题,并订阅警报以获得新的错误通知。
Honeybadger提供了你所需要的一切,以监控你的生产应用中发生的错误。按照下面的步骤,将它集成到你的Node.js应用程序中。
1.安装软件包
使用npm 来安装该软件包。
$ npm install @honeybadger-io/js --save
2.导入库
导入库,用你的API密钥配置它,开始报告错误。
const Honeybadger = require('@honeybadger-io/js');
Honeybadger.configure({
apiKey: '[ YOUR API KEY HERE ]'
});
3.报告错误
你可以通过调用notify() 方法来报告错误,如以下例子所示。
try {
// ...error producing code
} catch(error) {
Honeybadger.notify(error);
}
摘要
Error 类(或子类)应始终用于交流代码中的错误。从技术上讲,你可以在JavaScript中throw 任何东西,而不仅仅是Error 对象,但不建议这样做,因为这大大降低了错误的实用性,并使错误处理容易出错。通过持续使用Error 对象,你可以可靠地期望在处理或记录错误的地方访问error.message 或error.stack 。你甚至可以用与错误发生的环境相关的其他有用的属性来增强错误类。
操作错误是不可避免的,在任何正确的程序中都应该被考虑到。大多数情况下,应该采用可恢复的错误策略,以便程序能够继续顺利运行。然而,如果错误足够严重,终止程序并重新启动它可能是合适的。如果出现这种情况,尽量优雅地关闭,以便程序可以在干净的状态下再次启动。
程序员的错误是无法处理或恢复的,但可以通过自动测试套件和静态类型化工具来缓解。在编写函数时,要定义不良参数的行为,一旦检测到就采取适当的行动。如果检测到一个uncaughtException 或unhandledRejection ,允许程序崩溃。不要试图从这种错误中恢复!
使用错误监控服务,如Honeybadger,来捕获和分析你的错误。这可以帮助你极大地提高调试和解决的速度。
结论
如果你的目标是写出好的和可靠的软件,正确的错误处理是一个不可商量的要求。通过采用本文所描述的技术,你将会很好地做到这一点。
谢谢你的阅读,并祝你编码愉快
