

01.概述
这是我参与「第四届青训营」笔记创作活动的的第5天
1.1大数据与OLAP的演进
-
什么是大数据?
-
大数据=大规模的数据量?
-
关于大数据这里我们参考马丁·希尔伯特的总结:大数据其实是在2000年后,因为信息化的快速发展。信息交换、信息存储、信息处理三个方面能力的大幅增长而产生的数据。
-
Hadoop:基于廉价机器的存算分离的大规模分布式处理系统
- 1.谷歌在2003、2004年发布Google File System论文、MapReduce论文。
- 2.2008年,Hadoop成为apache顶级项目
OLAP(OnLine Analytical Processing) 对业务数据执行多维分析,并提供复杂计算,趋势分析和复杂数据建模的能力。是许多商务智能(BI)应用程序背后的技术。
OLAP VS MapReduce
- OLAP vs MaRed..1.MapReduce代表了抽象的物理执行模型,使用门槛较高
- 与Mapreduce Job相比,OLAP引擎常通过SQL的形式,为数据分析、数据开发人员提供统一的逻辑描述语言,实际的物理执行由具体的引擎进行转换和优化。
OLAP核心概念∶
- 维度
- 度量
常见的OLAP引擎:
- 预计算引擎:Kylin,Druid
- 批式处理引擎:Hive, Spark
- 流式处理引擎:Flink
- 交互式处理引擎:Presto,Clickhouse, Doris
Presto设计思想
Presto最初是由Facebook研发的构建于HadoopHDFS系统之上的PB级交互式分析引擎,其具有如下的特点:
- 多租户任务的管理与调度
- 多数据源联邦查询
- 支持内存化计算
- Pipeline式数据处理
基础概念介绍-服务相关
-
Coordinator
- 解析SQL语句生成执行计划
- 分发执行任务给Worker节点
-
Worker
- 执行Task处理数据
- 与其他Worker交互传输数据
2.1基础概念介绍-Query相关
-
Query
- 基于SQL parser后获得的执行计划
-
stage
- 根据是否需要shuffle将Query拆分成不同的subplan,每一个subplan便是一个stage
-
Fragment
- 基本等价于Stage,属于在不同阶段的称呼,在本门课程可以认为两者等价
-
Task
- 单个Worker节点上的最小资源管理单元:在一个节点上,一个Stage只有一个Task,一个Query可能有多个Task
-
Pipeline
- Stage按照LocalExchange 切分为若干Operator集合,每个Operator集合定义一个Pipeline.
-
Driver
- Pipeline的可执行实体,Pipeline和Driver的关系可类比程序和进程,是最小的执行单元,通过火山迭代模型执行每一个Operator.
-
split
- 输入数据描述(数据实体是 Page),数量上和Driver ——对应,不仅代表实际数据源split,也代表了不同stage间传输的数据。
-
Operator
- 最小的物理算子。
数据传输相关
Exchange & LocalExchange:
-
Exchange:
- √表示不同Stage 间的数据传输,大多数意义下等价于Shuffle
-
LocalExchange:
- √Stage内的rehash 操作,常用于提高并行处理数据的能力(Task在Presto中只是最小的容器,而不是最小的执行单元)
-
LocalExchange的默认数值是16。
-
Q:如何衡量某个任务某个Stage的真实并行度?
- A:在不同Pipeline 下Split (Driver)的数目之和。
2.2核心组件架构介绍
Presto架构图
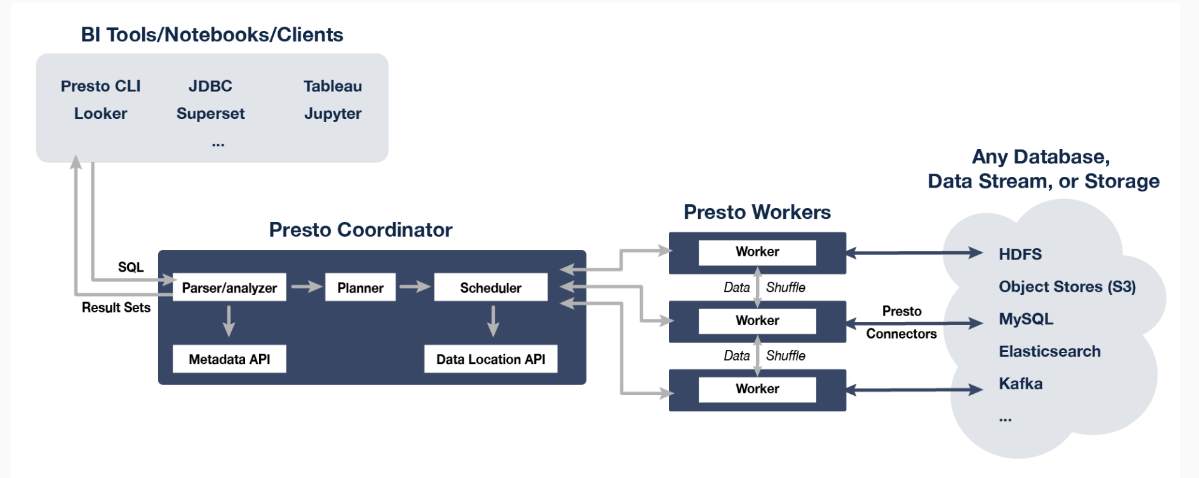
-
Discovery Service:
- Worker 配置文件配置Discovery Service地址
- Worker节点启动后会向Discovery Service注册
- Coordiantor 从Discovery Service获取Worker的地址
通信机制
- Presto Client / JDBC Client 与Server 间通信
- Http
- Coordinator 与 Worker 间的通信.
- Thrift / Http
- Worker 与Worker间的通信
- Thrift / Http
- Http 1.1 VS Thrift
- Thrift具有更好的数据编码能力,Http 1.1还不支持头部信息的压缩,Thrift具有更好的数据压缩率
节点状态:
-
ACTIVE
-
INACTIVE
-
SHUTDOWN
- Graceful shutdown(优雅的扩缩容)
Presto重要机制
多租户资源管理
Case介绍
假设某个用户提交一个sql:
- 提交方式:Presto-cli
- 提交用户:zhangyanbing
- 提交SQL: select customer type, avg (cost)as a from test_table group by customer type order by a limit 10;
Resource Group
-
类似Yarn多级队列的资源管理方式
-
基于CPU、MEMORY、SQL执行数进行资源使用量限制
-
优点:
- 轻量的Query级别的多级队列资源管理模式
-
缺点
- 存在一定滞后性,只会对Group中正在运行的 SQL进行判断
物理计划生成
- Antlr4解析生成AST
- 转换成Logical Plan
- 按照是否存在Shuffle (Exchange),切分成不同的Stage (Fragment)
多租户下的任务调度
Stage调度
-
Stage的调度策略
-
AllAtOnceExecutionPolicy 同时调度
- 延迟点,会存在任务空跑
-
PhasedExecutionPolicy 分阶段调度
-
不代表每个stage都分开调度
-
典型的应用场景(join查询)
- √Build端:右表构建用户join的hashtable
- √Probe端:对用户左表数据进行探查,需要等待build端完成
- √Build端构建hashtable端时,probe端是一直在空跑的
-
-
Task调度
Task 的数量如何确定
- source:根据数据meta决定分配多少个节点
- Fixed: hash partition count确定,如集群节点数量
- Sink:汇聚结果,一台机器
- Scaled:无分区限制,可拓展,如write数据
- Coordinator_Only:只需要coordinator参与
选择什么样的节点
- HARD_AFFINITY:计算、存储Local模式,保障计算与存储在同一个节点,减少数据传输
- SOFT_AFFINITY:基于某些特定算法,如一致性HASH函数,常用于缓存场景,保证相似的Task调度到同一个Worker
- NO_ PREFERENCE:随机选取,常用于普通的纯计算Task
Split调度
- Query A大SQL先提交
- Query B小sQL后提交
- 是否应该等Query A执行完了再执行Query B ?
FIFO:顺序执行,绝对公平
优先级调度:快速响应
- 按照固定的时间片,轮训split处理数据,处理1s,再重新选择一个Split执行
- Split间存在优先级
MultilevelSplitQueue
-
5个优先级level理论上分配的时间占比为16:8:4:2:1 (2-based)
-
优势:
- 优先保证小Query快速执行
- 保障大Query存在固定比例的时间片,不会被完全饿死
内存计算
- Pipeline 化的数据处理
- Back Pressure Mechanism
Pipeline 化数据处理
- Pipeline的引入更好的实现算子间的并行
- 语义上保证了每个Task 内的数据流式处理
内存计算
Back Pressure Mechanism
- 控制split生成流程
- 控制operator的执行
targetConcurrency auto-scale-out
- 定时检查,如果OutputBuffers使用率低于0.5(下游消费较快,需要提高生产速度),并发度+1
"sink.max-buffer-size"写入buffer的大小控制
- "exchange.max-buffer-size"读取buffer的大小控制达到最大值时Operator会进入阻塞状态
多数据源联邦查询
局限性:
- 1.元数据管理与映射(每个connector管理一套元数据服务)
- 2.谓词下推
- 3.数据源分片
Java相关指令
- Jstack查看Java线程栈信息,排查是否有 死锁,或者异常线程存在
- JMX(Java Management Extensions)是一个为应用程序植入管理功能的框架,常用来做一些监控指标的统计收集
- JMAP & GC日志等等内存分析工具
03关键设计
NameNode目录树维护
fsimage
- 文件系统目录树
- 完整的存放在内存中
- 定时存放到硬盘上
- 修改是只会修改内存中的目录树
EditLog
- 目录树的修改日志
- client更新目录树需要持久化EditLog后才能表示更新成功
- EditLog可存放在本地文件系统,也可存放在专用系统上
- NameNode HA方案一个关键点就是如何实现EditLog共享
数据块信息维护
- 目录树保存每个文件的块id
- NameNode维护了每个数据块所在的节点信息
- NameNode根据DataNode汇报的信息动态维护位置信息
- NameNode不会持久化数据块位置信息
数据放置策略
- 新数据存放到哪写节点
- 数据均衡需要怎么合理搬迁数据
- 3个副本怎么合理放置
DataNode
数据块的硬盘存放
- 文件在NameNode已分割成block
- DataNode以block为单位对数据进行存取
启动扫盘
- DataNode需要知道本机存放了哪些数据块
- 启动时把本机硬盘上的数据块列表加载在内存中
HDFS写异常处理:
Lease Recovery
-
租约:Client要修改一个文件时,需要通过NameNode上锁,这个锁就是租约(Lease)。
-
情景∶文件写了一半,client自己挂掉了。可能产生的问题:
- 副本不一致
- Lease无法释放
-
解决方法:Lease Recovery
Pipeline Recovery
-
情景:文件写入过程中,DataNode侧出现异常挂掉了。
-
异常出现的时机:
- 创建连接时
- 数据传输时
- complete阶段
-
解决方法:Pipeline Recovery
-
Client 读异常处理
- 情景:读取文件的过程,DataNode侧出现异常挂掉了
- 解决方法:节点 Failover
- 增强情景:节点半死不过,读取很慢
旁路系统
- Balancer:均衡DataNode的容量
- Mover:确保副本放置符合策略要求
控制面建设
可观测性设施
- 指标埋点
- 数据采集
- 访问日志
- 数据分析
运维体系建设
- 运维操作需要平台化
- NameNode操作复杂
- DataNode机器规模庞大
- 组件控制面API
