

介绍
在Wingify,我们遵循基于微服务的架构,以利用其巨大的可扩展性优势。我们有很多的微服务,以及它们之间复杂的网络设置。目前,所有的服务都部署在云上的虚拟机上。我们希望改善这种架构设置,并使用最新的技术。为了避免这一切,我们正在向Docker和Kubernetes世界迈进。
为什么是Docker和Kubernetes?
我们在现有的基础设施上所面临的问题:
-
标准化和一致性
- 在生产和开发之间总是存在一个一致/标准的环境问题。
- 在开发过程中,我们的大部分时间都花在创建一个类似于生产的环境,以推出错误修复或创建任何新功能。
- 有了新的架构,现在我们更有能力有效地分析和修复应用程序中的错误。它大大减少了浪费在 "本地环境问题 "上的时间,反过来又增加了可用来修复实际问题和开发新功能的时间。
- Docker提供了一个可重复的类似于生产的开发环境,一劳永逸地消除了 "它在我的机器上能用 "的问题。
-
本地开发
- 在本地开发和调试一个服务并将其与运行在本地环境中的其他服务连接起来并不容易。
- 不断地在本地环境中重新部署以测试变化是非常耗时的。
-
自动扩展
- 服务上的负载不可能一直都是一样的。
- 为了处理节日期间的高峰负荷而全年保持服务,是对资源的一种浪费。
- 定期对负载进行基准测试,以便随着时间的推移扩展服务,这不是一个最佳方式。
-
自动服务重启
- 如果服务处于挂起状态,或者由于内存泄漏、资源轮询死锁、文件描述符问题或其他原因而终止,它如何自动重启?
- 虽然有不同的工具可用于多种语言,但为每台服务器上的每项服务设置这些工具并不理想。
-
负载平衡
- 添加和维护一个额外的入口点,如nginx,只是为了提供负载平衡,这是一个开销。
我们正试图使用Docker、Kubernetes和一些开源工具,以一种自动化和简单的方式解决所有这些问题。
我们的旅程
我们从头开始。阅读了大量的文章、文档、教程,并浏览了一些现有的测试和生产级别的开源项目。其中有些项目解决了我们的一些问题,有些项目我们找到了自己的方法,剩下的问题还没有解决。
下面是我们发现的解决许多问题的所有想法和方法的简要想法,我们最终采取的方法和它们之间的比较。
常见的存储库方法
每一个docker化的服务都以一个Docker文件开始。但最初的问题是把它们放在哪里?会有很多Dockerfiles结合所有的服务。
有两种方法来放置它们:
-
每个服务都包含它自己的dockerfile
- 所有的资源库都有特定于该服务的单独的dockerfile。
-
一个所有dockerfiles的公共资源库
- 每个服务的所有dockerfiles都被添加到一个共同的资源库。
下面是它们之间的比较:
| 通用仓库 | 单独的存储库 | |
|---|---|---|
| 1. | 需要一个适当的结构来区分dockerfiles | 分离关注点 |
| 2. | 共同的研磨器和格式化器 | 每个 repo 都必须重复添加相同的 linter 和 formatter。 |
| 3. | 共同的githooks来管理提交信息、预提交、预推送等任务。 | 每个服务中都有相同的githooks |
| 4. | 可以包含可重复使用的Docker基础文件 | 没有集中的地方来放置可重用的docker文件 |
| 5. | 为DevOps管理所有dockerfiles的权限提供一个中心位置。 | Devops很难单独管理dockerfiles |
你可能在想,在单独的存储库方法中使用卷来进行本地开发是很容易的。我们稍后会回到这个问题上,并说明在共同仓库方法中会有多容易。
所以,公共资源库方法是他们中明显的赢家。但是它的文件夹结构如何呢?我们考虑了很多,最后,这就是我们的Docker资源库的文件夹结构。
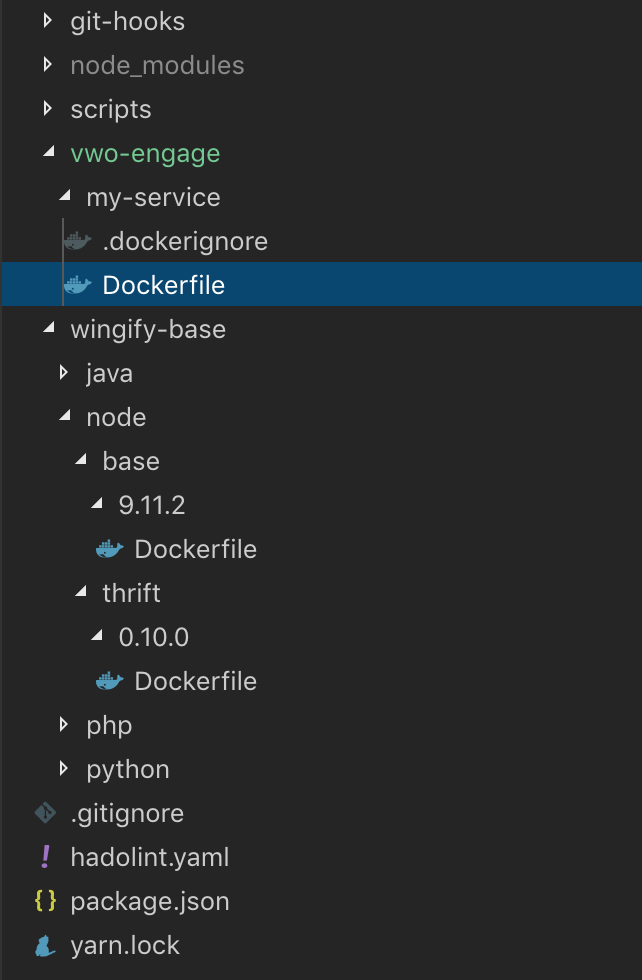
文件夹结构大致分为两部分: * **服务目录:** - 它包含所有服务的目录,每个服务都有自己的 "dockerfile "和".dockerignore "文件。 - 只包含语言的Dockerfiles被放置在 "base "文件夹中。 - 上述基础镜像的所有扩展、插件、工具等被放置在同一个目录中,如node.js的 "thrift"。比如,一个服务可能需要MySQL 5.6,另一个可能需要5.7。因此,每个目录在版本的基础上被进一步嵌套。
使用这种文件夹结构有多种优势:
- 所有的服务和可重用的基础dockerfiles都被隔离开来。
- 哪个dockerfile是为哪个服务、语言或插件准备的,这一点变得非常清楚。
- 可以很容易地提供多个版本。
接下来,我们将讨论可重用的基础镜像概念。
Dockerfile Linter
有许多开源的linters可用于Docker文件。我们发现hadolint符合Docker推荐的大部分标准。因此,要对所有的文件进行润色,我们只需要发布一个简单的命令,可以很容易地集成到githooks中。
hadolint **/*Dockerfile
Dockerfile格式化器
我们搜索并尝试了多个格式化器,但没有一个能满足我们的要求。我们发现dockfmt接近我们的要求,但它也有一些问题,比如它从dockerfile中删除了所有的注释。所以,我们还没有找到一个更好的格式。
可重复使用的Docker基础镜像
很多服务都需要相同的操作系统、工具、库等,这是非常常见的,比如所有的node服务都可能需要安装了node.js和yarn的特定版本的Debian stretch操作系统。因此,我们可以创建一些可重复使用的、可插拔的Docker基础镜像,而不是在所有这些Docker文件中添加它们。
下面是一个Node.js服务的例子,它需要:
- 蝶变操作系统
- Node.js版本9.11.2+Yarn
- Apache thrift 0.10.0版本
Node.js基础镜像
FROM debian:stretch-slim
# Install Node 9.11.x
# Defining builDeps as an argument in alphabetical order for better readability and avoiding duplicacy.
ARG buildDeps=" \
curl \
g++ \
make"
# It causes a pipeline to produce a failure return code if any command results in an error.
SHELL ["/bin/bash", "-o", "pipefail", "-c"]
# hadolint ignore=DL3008,DL3015
RUN apt-get update && apt-get install -y —- no-install-recommends $buildDeps \
# Use --no-install-recommends to avoid installing packages that aren't technically dependencies but are recommended to be installed alongside packages.
&& curl -sL https://deb.nodesource.com/setup_9.x | bash - && apt-get install -y nodejs=9.11.* \
&& npm i -g yarn@1.19.1 \
&& apt-get clean \
# Remove apt-cache to make the image smaller.
&& rm -rf /var/lib/apt/lists/*
让我们考虑一下,我们用'wingify-node-9.11.2:1.0.5'的名字来构建它。其中'wingify-node-9.11.2'代表docker镜像类型,'1.0.5'是镜像标签。
Apache thrift基础镜像
# Default base image
ARG BASE=wingify-node-9.11.2:1.0.5
# hadolint ignore=DL3006
FROM ${BASE}
# Declaring argument to be used in dockerfile to make it reusable.
ARG THRIFT_VERSION=0.10.0
# Referred from https://github.com/ahawkins/docker-thrift/blob/master/0.10/Dockerfile
# hadolint ignore=DL3008,DL3015
RUN apt-get update \
&& curl -sSL "http://apache.mirrors.spacedump.net/thrift/$THRIFT_VERSION/thrift-$THRIFT_VERSION.tar.gz" -o thrift.tar.gz \
&& mkdir -p /usr/src/thrift \
&& tar zxf thrift.tar.gz -C /usr/src/thrift --strip-components=1 \
&& rm thrift.tar.gz \
# Clean the apt cache on.
&& apt-get clean \
# Remove apt cache to make the image smaller.
&& rm -rf /var/lib/apt/lists/*
WORKDIR /usr/src/thrift
RUN ./configure --without-python --without-cpp \
&& make \
&& make install \
# Removing the souce code after installation.
&& rm -rf /usr/src/thrift
这里,默认情况下,我们使用上述创建的节点的Docker镜像。但我们可以通过任何其他环境的基础镜像作为参数来安装thrift。所以,它在任何地方都是可插拔的。
最后,实际的服务可以使用上述基础镜像作为它的dockerfile。
访问私有资源库的依赖性
我们有多个服务都有一些从私人仓库获取的依赖项。就像我们的node服务,我们有一个依赖项在package.json中列出:
{
"my-dependency": "git+ssh://git@stash/link/of/repo:v1.0.0",
}
通常情况下,我们需要ssh密钥来获取这些依赖,但Docker容器不会有这种情况。以下是解决这个问题的几种方法。
-
选项1:从外部安装依赖项(本地或Jenkins),Docker会直接复制它们。
-
优点是:
- docker不需要SSH密钥
-
缺点:
- 依赖关系的安装不会自动缓存,因为它发生在docker之外
- 一些模块,如bcrypt,如果不直接安装在同一台机器上,会有绑定问题
-
-
选项2:在dockerfile中传递SSH密钥作为参数,或者从系统中复制到工作目录中,让dockerfile复制它。然后,Docker容器可以安装依赖性。
-
优点:
- 实现了缓存
- 没有模块绑定问题
-
缺点是:
- 如果处理不当,SSH密钥会暴露在Docker容器中
- 单个SSH密钥会有安全问题,不同的SSH密钥会很难管理
-
-
选项3:像我们自己的私有npm一样在全球范围内托管私有仓库(如果是node.js),并在系统中添加它的主机条目。然后,Docker容器可以通过从我们的私有npm获取来安装依赖性。
-
优点:
- 实现了缓存
- 不需要SSH密钥
-
劣势:
- 一次性设置主机
- 每次创建新标签时,我们都需要发布私人仓库
-
事实证明,方法3在我们的案例中要好得多,所以我们采用了它。
服务Dockerfile
实现上述所有服务的最终docker文件将是这样的:
ARG BASE=wingify-node-9.11.2-thrift-0.10.0:1.0.5
# hadolint ignore=DL3006
FROM ${BASE}
RUN mkdir -p /opt/my-service/
WORKDIR /opt/my-service
# Dependency installation separately for caching
COPY ./package.json ./yarn.lock ./.npmrc ./
RUN yarn install
COPY . .
CMD ["yarn", "start:docker"]
这里'.npmrc'包含了指向我们自己的私有npm的注册表。我们复制它是为了让Docker容器能够从它那里获取我们的私有仓库。
缓存
每次我们改变我们的代码时,我们不希望Docker容器再次安装依赖项(除非改变)。为此,我们将上述dockerfile中的 "复制 "步骤分为两部分:
# Here we are copying the package.json and yarn.lock files and doing dependencies installation.
# This step will always be cached in Docker unless there is change in any of these files
COPY ./package.json ./yarn.lock ./.npmrc ./
RUN yarn install
COPY . .
做到这一点,Docker镜像的构建时间就会缩短到几秒钟
自动标记和回滚
标记对于任何回滚的制作都是很重要的。幸运的是,这在docker中很容易做到。在Kubernetes上构建和推送镜像时,我们可以用冒号指定标签的版本。然后我们可以在Kubernetes的YAML文件中使用这个标签来部署在pod上:
docker build -t org/my-service .
docker build -t org/my-service:1.2.3 .
docker push org/my-service .
docker push org/my-service:1.2.3 .
这样做很好,但每次我们构建新版本的镜像时,仍然需要一个新的标签。这可以手动传递给一个作业。但如果有自动标签呢?
首先,让我们找出最新的标签。这里是查找GCP的最新图像标签的命令:
gcloud container images list-tags image-name --sort-by=~TAGS --limit=1 --format=json
我们可以在一个自定义节点脚本中使用这个命令,它将返回新的增量版本。我们只需将图像名称和发布类型,即major/minor/patch传递给它:
// Usage: node file-name image-name patch
const exec = require('child_process').execSync;
const TAG_TYPES = {
PATCH: 'patch',
MINOR: 'minor',
MAJOR: 'major'
};
// Referenced from https://semver.org/
const VERSONING_REGEX = /^(v)?(0|[1-9]\d*)\.(0|[1-9]\d*)\.(0|[1-9]\d*)(?:-((?:0|[1-9]\d*|\d*[a-zA-Z-][0-9a-zA-Z-]*)(?:\.(?:0|[1-9]\d*|\d*[a-zA-Z-][0-9a-zA-Z-]*))*))?(?:\+([0-9a-zA-Z-]+(?:\.[0-9a-zA-Z-]+)*))?$/m;
class Autotag {
constructor(imageName = '', tagType = TAG_TYPES.PATCH) {
this._validateParams(imageName, tagType);
this.imageName = imageName;
this.tagType = tagType.toLowerCase();
}
// Private functions
_validateParams(imageName, tagType) {
if (!imageName) {
throw new Error('Image name is mandatory.');
}
if (!Object.values(TAG_TYPES).includes(tagType)) {
throw new Error(
`Invalid tag type specified. Possible values are ${Object.values(
TAG_TYPES
).join(', ')}.`
);
}
}
_fetchTagsFromGCP() {
return exec(
`gcloud container images list-tags ${
this.imageName
} --sort-by=~TAGS --limit=1 --format=json`
).toString();
}
// Public functions
increment() {
const stringifiedTags = this._fetchTagsFromGCP();
if (stringifiedTags) {
try {
const { tags } = JSON.parse(stringifiedTags)[0];
for (let i = tags.length - 1; i >= 0; i--) {
const tag = tags[i];
if (VERSONING_REGEX.test(tag)) {
let [
prefix = '',
major = 0,
minor = 0,
patch = 0
] = VERSONING_REGEX.exec(tag).slice(1);
switch (this.tagType) {
case TAG_TYPES.PATCH:
patch++;
break;
case TAG_TYPES.MINOR:
patch = 0;
minor++;
break;
case TAG_TYPES.MAJOR:
patch = 0;
minor = 0;
major++;
break;
}
return `${prefix}${major}.${minor}.${patch}`;
}
}
} catch (e) {}
}
// Return default tag if none already exists.
return '0.0.1';
}
}
try {
console.log(new Autotag(...process.argv.slice(2)).increment());
} catch (e) {
console.log(e.toString());
}
感谢Gaurav Nanda提供的上述脚本。
生产阶段性推出
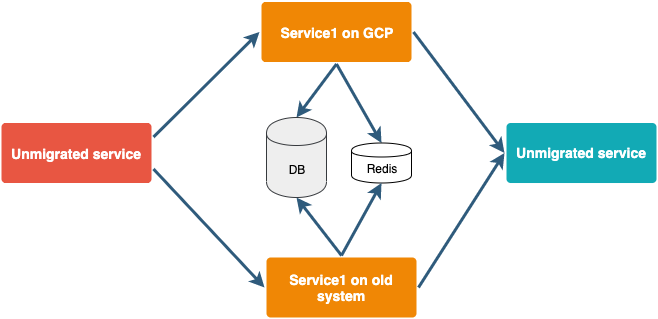
我们的最终目标是用Docker和Kubernetes将所有东西从现有设置迁移到GCP。在生产中一次性迁移整个系统是很耗时的,也是有风险的。
为了避免这种情况,我们正逐一针对个别服务。最初,一个服务将在GCP以及现有的服务器上运行,其数据库指向旧的设置。我们将在一开始就为几个账户开放它们。其余的账户将像以前一样工作。这将确保如果在新的设置中出现任何问题,我们可以轻松地切换到旧的设置,同时修复它。
接下来的步骤
- 将健康检查API与Kubernetes结合起来。
- 使用远程呈现的开发环境。
- 增加像consul这样的服务发现工具。
- 为秘密添加一个保险库系统。
- 更好的日志记录。
- 集成Helm来管理Kubernetes集群。
- Docker镜像大小管理。
- 增加对蓝绿部署的支持。
我们可能以不同的方式使用一些东西,可以加以改进。可以有更好的工具,我们还没有探索。我们愿意接受任何可以帮助我们改进我们已经在做的事情和未来需要的事情的建议。这只是一个开始,我们会在每一次迭代中努力改进,解决新的挑战。
