

简介
在这篇文章中,我们将介绍新的物体检测模型YOLOv6,自从它的GitHub几天前被公开后,它就在计算机视觉界引起了轰动。我们将简要介绍它的结构和它的作者声称的改进。然后我们将通过一步一步的教程和例子来解释如何使用YOLOv6。
什么是YOLOv6?
YOLOv6是由中国电子商务平台公司美团网的一个团队创建的物体检测模型。它的实际名称是MT-YOLOv6,但创造者为了简洁起见使用了YOLOv6这个名字。在其核心部分,他们在YOLO(You Look Only Once)架构的基础上建立了这个模型,并声称比YOLO系列的其他模型有一些改进和新方法。这个框架是用PyTorch编写的。
关于YOLOv6名称的争论
应该指出的是,YOLO的原作者--Joseph Redmon在发表了YOLOv1(2016)、YOLOv2(2017)和YOLOv3(2018)之后,离开了这个领域。 Alexey Bochkovskiy是Joseph Redmon的原始YOLO工作的维护者,后来在2020年出版了YOLOv4,这是原始团队的最后一部作品。
YOLOv5是在YOLOv4发布几天后,由Ultranytics的一个独立团队在2020年发布的。YOLOv5只是YOLOv3的PyTorch实现,具有极大的易用性。但是,他们使用YOLO品牌而没有发布任何文件或进行任何改进,这在社区中并不顺利。人们普遍认为,它不配被称为YOLO的第五个版本。
一场类似的辩论也开始在YOLOv6上展开,社区对美团使用他们的模型品牌作为YOLO的第六个版本表示关注,认为这是不道德的。然而,美团团队在GitHub页面上解释说,他们的工作受到了YOLO的启发,他们在现有版本的基础上实施了一些新技术和改进。此外,他们还声称,他们正试图与YOLO的原作者就YOLOv6的品牌问题进行接触。
- 同时阅读 - 从YOLOv1到YOLOv5的YOLO物体检测模型简史
YOLOv6研究论文
美团网团队没有发表任何研究论文供同行评审,然而,他们在其网站上发表了一份技术报告。在那里我们可以深入了解YOLOv6的架构和性能。
YOLOv6的架构
YOLOv6的架构集中在3个主要的改进上,即
- 硬件友好的骨干和颈部设计
- 去耦头以提高效率
- 有效的训练策略
1.硬件友好的骨干和颈部设计
YOLOv6的颈部和骨干架构
YOLOv6的骨干和颈部是通过从硬件感知的神经网络设计中获得灵感而设计的。这个想法是考虑到硬件方面,如计算能力、内存带宽等,以实现高效推理。为了实现这一目标,YOLOv6中的颈部和骨干已经分别通过使用Rep-Pan和EfficientRep结构进行了重新设计。
美团网团队进行的实验表明,通过YOLOv6的这种设计,硬件的延迟大大降低,同时检测效果也得到了改善。例如:与YOLOv5-Nanao相比,YOLOv6-Nono的速度提高了21%,AP提高了3.6%。
2.去耦头,提高效率
YOLOv6的解耦头架构
直到YOLOv5的早期版本的YOLO架构曾经有一个分类和箱体回归的共同特征。YOLO的另一个变体,即YOLOX,首先提出了解耦头架构,并被YOLOv6采用和改进。这再次帮助YOLOv6提高了它的速度和检测精度,超过了它的前辈们。
3.有效的训练策略
为了提高检测精度,YOLOv6使用了无锚范式、SimOTA标签分配策略和SIOU Bounding Box回归损失。
不同的YOLOv6模型
目前,YOLOv6的创造者只发布了三种变体--Nano、Tiny和Small,他们在GitHub页面上提到,Medium、Large、X-Large将很快发布。以下是这些变化的细节
| 类型 | 名称 | 规模 | 参数 |
| 纳米级 | YOLOv6n | 9.8 MB | 4.3M |
| 微型 | YOLOv6t | 33 MB | 15M |
| 小型 | YOLOv6s | 38.1MB | 17.2M |
| 中型 | 即将推出 | ||
| 大号 | 即将推出 | ||
| 超大号 | 即将推出 | ||
YOLOv6的性能
YOLOv6的创造者在其技术报告中分享了与YOLOv5和YOLOX的性能比较。
-
YOLOv6-nano在COCO val上获得了35.0%的AP准确率,在T4上利用TRT FP16 batchsize=32进行推理,获得了1242FPS的性能。这意味着与YOLOv5-nano相比,准确度提高了%AP,速度提高了85%。
-
当在T4上使用TRT FP16 batchsize=32进行推理时,YOLOv6-tiny在COCO val上实现了41.3%的AP准确性和602FPS的性能。与YOLOv5-s相比,精度提高了3.9%,速度提高了29.4%。
-
当利用TRT FP16 batchsize=32对T4进行推理时,YOLOv6-s可以获得520FPS的速度,比YOLOX-s快2.6%的AP和38.6%。它在COCO val上也取得了43.1%的AP准确性。与PP-YOLOE-s相比,精度提高了0.4%AP。在T4的TRT FP16上进行单批推理时,速度提高了71.3%。
-
另请阅读 - YOLOv5物体检测教程
-
同时阅读 - 教程 - YOLOv5在Colab中的自定义对象检测
YOLOv6推理语法
命令
我们可以通过在命令提示符下使用以下命令轻松地使用YOLOv6进行推理
python tools/infer.py --weights <weight_name> --source <img_path>
参数
有许多参数可以使用,如下所示,其中许多是可选的----。
- **weights -用于推理的模型的路径。默认是"weights/yolov6s.pt"。
- **source -执行物体检测的源图像的路径。默认是'data/images'。
- **yaml -**它是数据的yaml文件。
- **img-size -**是推理中的image-size(h,w)的大小。默认为640。
- **conf-thres -**它是推理中的信心值的阈值。默认值是0.25
- **iou-thres -**它是用于推理的NMS IoU阈值。默认为0.45
- **max-det -**它是每个图像的最大推断值。默认值是1000
- **device -**它表示运行模型的设备,即0或0、1、2、3或CPU。默认值是0。
- **save-txt -**它用于将结果保存为*.txt。
- **save-img -**它用于保存可视化的推理结果。
- **classes -**用于按类别过滤,例如:-classes 0,或-classes 0 2 3。
- **agnostic-nms -**标志着类别无关的NMS。
- **project -用于保存推理结果到项目/名称。默认是"runs/inference"。
- **name -用于将推理结果保存到项目/名称中。默认为'exp'。
- **hide-labels -**用于隐藏推理结果中的标签。缺省是'False'。
- **hide-conf -**它用于隐藏推理结果中的置信度值。缺省是 "False"。
- **half -**标志着是否使用FP16半精度推理。
YOLOv6教程 - 在Colab中逐步进行
在本节中,我们将通过实例来展示YOLOv6的逐步教程。为此,我们将使用谷歌Colab笔记本和它的免费GPU。
Google Colab的设置
进入Google Colaboratory,在其设置中选择硬件加速器为 "GPU",如下面的截图所示。
Google Colab GPU运行时间
克隆YOLOv6资源库
我们先从GitHub克隆YOLOv6仓库,在Colab笔记本单元中运行以下命令。(如果你没有使用Colab并从命令提示符下运行它,请在开始时删除!)。
In [0]:
!git clone https://github.com/meituan/YOLOv6
输出[0]。
Cloning into 'YOLOv6'...
remote: Enumerating objects: 911, done.
remote: Counting objects: 100% (38/38), done.
remote: Compressing objects: 100% (29/29), done.
remote: Total 911 (delta 11), reused 23 (delta 9), pack-reused 873
Receiving objects: 100% (911/911), 1.73 MiB | 31.56 MiB/s, done.
Resolving deltas: 100% (461/461), done.
安装依赖项
接下来,我们改变路径到我们在上面第一步克隆的YOLOv6目录。在那里我们安装YOLOv6的requirement.txt文件中列出的所有依赖项。
在[1]中。
%cd YOLOv6
!pip install -r requirements.txt
下载权重
现在我们将用下面的命令下载YOLOv6 Nano、Tiny和small的权重。请注意,GitHub仍在积极开发中,所以权重的下载链接在未来可能会改变。
在[2]中。
# Download Nano Weight
上传和显示样本图片
在所有的YOLOv6例子中,我们将使用下面的图片'sample.jpg',我们手动上传至Google Colab VM。
我们可以使用PIL包的显示功能来查看Colab笔记本中的图片。
In[3]:
from PIL import Image
img = Image.open('/content/YOLOv6/sample.jpg')
display(img)
输出[3]。
使用yolov6n.pt进行推理
让我们首先使用nano权重yolov6n.pt进行推理,如下图所示。
在[4]中。
#Inferencing
Out[4]:
Namespace(agnostic_nms=False, classes=None, conf_thres=0.25, device='0', half=False, hide_conf=False, hide_labels=False, img_size=640, iou_thres=0.45, max_det=1000, name='exp', project='runs/inference', save_img=True, save_txt=False, source='/content/YOLOv6/sample.jpg', weights='yolov6n.pt', yaml='data/coco.yaml')
Loading checkpoint from yolov6n.pt
Fusing model...
/usr/local/lib/python3.7/dist-packages/torch/functional.py:568: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:2228.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
Switch model to deploy modality.
100% 1/1 [00:00<00:00, 7.82it/s]
Results saved to runs/inference/exp
从上面的输出中,我们可以看到有很多误报,例如,西瓜和橙子被标记为苹果,南瓜被标记为热狗。为了产生更好的结果,让我们再次推断,但使用conf-thres参数为0.50,这样它就只检测那些高置信度值大于0.50的对象。
在[5]中。
#Inferencing
Out[5]:
Namespace(agnostic_nms=False, classes=None, conf_thres=0.5, device='0', half=False, hide_conf=False, hide_labels=False, img_size=640, iou_thres=0.45, max_det=1000, name='exp', project='runs/inference', save_img=True, save_txt=False, source='/content/YOLOv6/sample.jpg', weights='yolov6n.pt', yaml='data/coco.yaml')
Save directory already existed
Loading checkpoint from yolov6n.pt
Fusing model...
/usr/local/lib/python3.7/dist-packages/torch/functional.py:568: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:2228.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
Switch model to deploy modality.
100% 1/1 [00:00<00:00, 23.49it/s]
Results saved to runs/inference/exp
这一次,我们可以看到它只检测了那些高置信度值高于0.50的对象,从而消除了错误的检测。
使用yolov6t.pt进行推理
接下来,我们使用yolov6t.pt的微小模型和conf-thres值0.35来产生更好的结果。
在[6]中。
#Inferencing
Out[6]:
Namespace(agnostic_nms=False, classes=None, conf_thres=0.35, device='0', half=False, hide_conf=False, hide_labels=False, img_size=640, iou_thres=0.45, max_det=1000, name='exp', project='runs/inference', save_img=True, save_txt=False, source='/content/YOLOv6/sample.jpg', weights='yolov6t.pt', yaml='data/coco.yaml')
Save directory already existed
Loading checkpoint from yolov6t.pt
Fusing model...
/usr/local/lib/python3.7/dist-packages/torch/functional.py:568: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:2228.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
Switch model to deploy modality.
100% 1/1 [00:00<00:00, 22.84it/s]
Results saved to runs/inference/exp
从输出结果可以看出,它产生了比纳米模型更好的结果。这一次,它也检测到了橙子和苹果后面的人的头部。
使用yolov6s.pt进行推断
接下来,我们使用yolov6s.pt的小模型和0.35的conf-thres值来产生更好的结果。
在[7]中。
#Inferencing
Out[7]:
Namespace(agnostic_nms=False, classes=None, conf_thres=0.35, device='0', half=False, hide_conf=False, hide_labels=False, img_size=640, iou_thres=0.45, max_det=1000, name='exp', project='runs/inference', save_img=True, save_txt=False, source='/content/YOLOv6/sample.jpg', weights='yolov6s.pt', yaml='data/coco.yaml')
Save directory already existed
Loading checkpoint from yolov6s.pt
Fusing model...
/usr/local/lib/python3.7/dist-packages/torch/functional.py:568: UserWarning: torch.meshgrid: in an upcoming release, it will be required to pass the indexing argument. (Triggered internally at ../aten/src/ATen/native/TensorShape.cpp:2228.)
return _VF.meshgrid(tensors, **kwargs) # type: ignore[attr-defined]
Switch model to deploy modality.
100% 1/1 [00:00<00:00, 22.81it/s]
Results saved to runs/inference/exp
这一次的结果比小模型要好。可以看出,左边靠后的苹果也被识别。
- 还可以阅读 - YOLOv4物体检测教程与图像和视频。初学者指南
- 同时阅读 - 在Google Colab中训练自定义YOLOv4模型进行物体检测
更多YOLOv6物体检测的例子
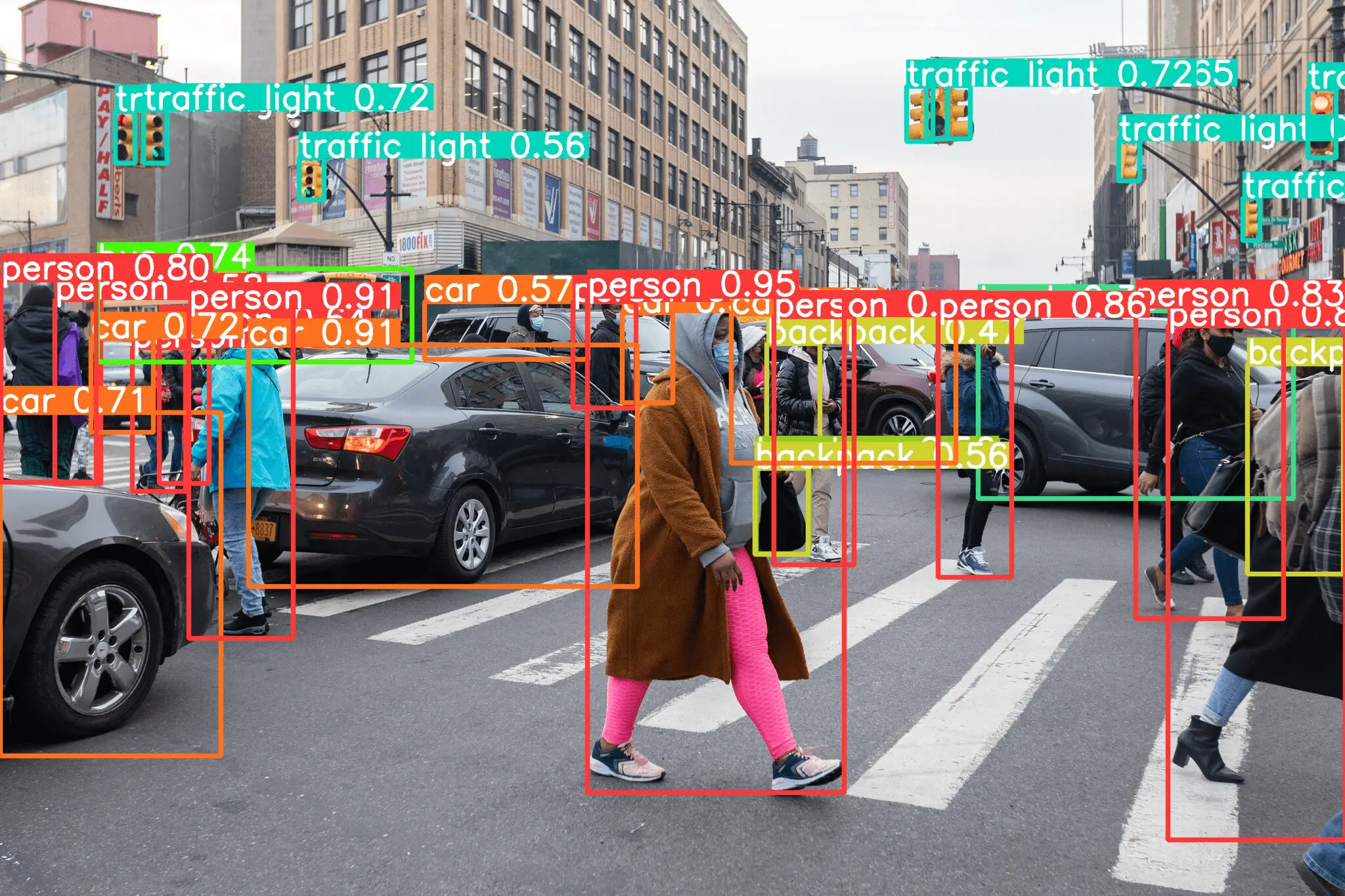
希望你喜欢我们上面的YOLOv6教程的步骤。下面是一些用YOLOv6检测物体的例子,表明它在检测物体方面确实很出色。

The postYOLOv6 Explained with Tutorial and Exampleappeared first onMLK - Machine Learning Knowledge.
