简介
在本教程中,我们将看到在Python Sklearn和Scipy中实现聚类分层的方法。首先,我们将简单了解什么是分层聚类以及聚类的工作原理。然后,我们将创建我们自己的样本数据集,展示在Scipy中创建树状图和在Sklearn中实现聚类的例子。
什么是层次聚类?
层次聚类是一种无监督的聚类算法,用于创建具有树状层次结构的聚类。在这种聚类方法中,不需要向算法提供聚类的数量。 与此相反,其他的算法,如K-Mean,产生的是没有层次的平面聚类,我们也必须选择聚类的数量,开始。
什么是层次聚类中的树状图?
层次聚类创造了一个树状的图形结构,称为树枝图,它显示了表示聚类之间层次关系的合并/拆分序列。
树枝图的一个很好的现实世界的例子是表示动物王国的分类,如下图所示:
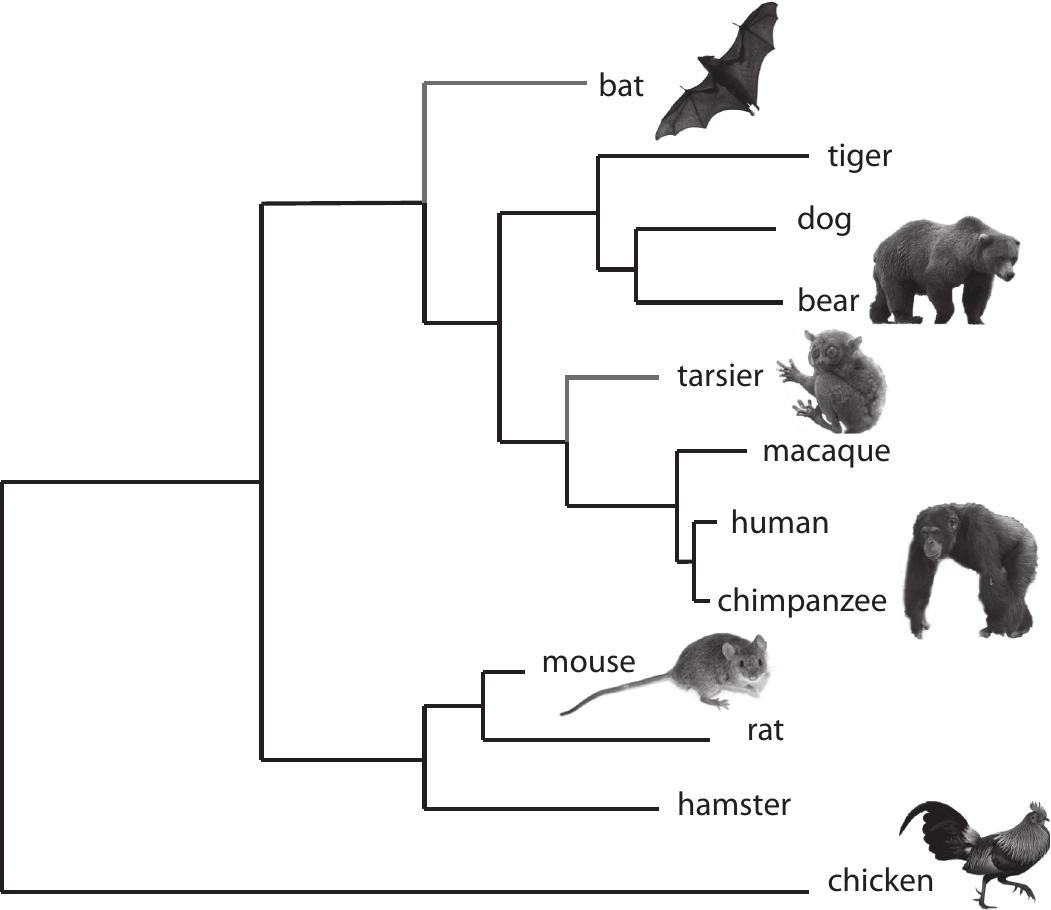
(来源)
层次聚类的类型
分层聚类算法可以分为两种类型
- 分裂聚类--它采取自上而下的方法,在开始时整个数据观察被认为是一个大聚类。然后再把它分成两个聚类,然后是三个聚类,以此类推,直到每个数据最终成为一个独立的聚类。
- 聚合聚类它采取自下而上的方法,在开始时假定单个数据观察是一个聚类。然后,它开始将数据点合并到聚类中,直到最后用所有数据点创建一个最终的聚类。
理想情况下,分化和聚集的分层聚类都会产生相同的结果。然而,聚集聚类的计算速度很快,因此我们将在文章中进一步介绍。
聚合式聚类
正如我们前面所讨论的,聚类遵循一种自下而上的方法,首先将每个数据点放在自己的聚类中。然后,它将这些单独的聚类合并成越来越大的聚类,直到所有的数据点都被归入一个单一的聚类,也称为根,或者直到满足某些终止条件。
这就产生了我们上面讨论过的基于树状图的数据点表示法:
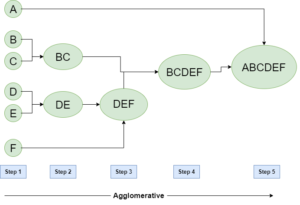
聚合聚类法的算法
1)每个数据点被分配为一个单独的聚类
-
确定距离测量并计算出距离矩阵
-
确定合并聚类的联系标准
-
更新距离矩阵
5)重复这个过程,直到每个数据点成为一个聚类
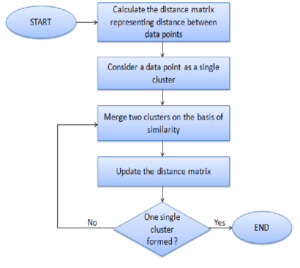
聚合式聚类的参数
聚合分层聚类可以有多种变化,这取决于亲和力和联系。让我们更详细地了解这一点。
亲和力
亲和力指的是计算数据点或聚类之间的距离或相似性所使用的方法。常见的有--
- 欧几里得
- 曼哈顿
- 余弦法
链接
聚类是通过使用不同类型的标准或知识作为链接函数而形成的。联结方法使用我们上面讨论的亲和力。
不同的联结方法产生不同的层次聚类结果,它们列举如下
- 单一的
- 完整的
- 平均值
- 病房
以聚类数量为输入的聚类法
从根本上讲,聚类法不需要输入聚类的数量。然而,使用聚类法产生像K-means那样的平面聚类时,有可能将聚类的数量作为输入。虽然这里没有关于如何确定聚类数量的明确规则,但有一个很好的技巧,可以通过使用树状图来估计什么是好的聚类数量。我们将在下面的实际例子中看到这一点。
用Scipy和Sklearn进行聚类划分
现在让我们看看我们如何通过使用Python的Scipy和Sklearn包来实现聚类分级聚类。为了这个目的,我们将创建我们自己的玩具数据集样本,以便更好地进行可视化和理解。
导入库
首先,让我们导入所需的库,如下所示。
在[0]中:
import pandas as pd
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import make_blobs
数据集
这里我们使用Scikit Learn的sklearn.datasets包中的make_blobs模块来创建一个有两个特征的50个数据点的自定义玩具数据集。
在[1]中:
X, y = make_blobs(n_samples=50, centers=2, n_features=2,random_state=3)
df=pd.DataFrame(X,y)
df=df.rename(columns={0: "X1", 1:"X2"})
df.head()
输出[1]:
| X1 | X2 | |
|---|---|---|
| 1 | -3.336072 | -1.644337 |
| 0 | 0.092166 | 3.139081 |
| 1 | -5.552574 | 0.455115 |
| 0 | -0.297907 | 5.047579 |
| 0 | 0.419308 | 3.574362 |
在[2]:
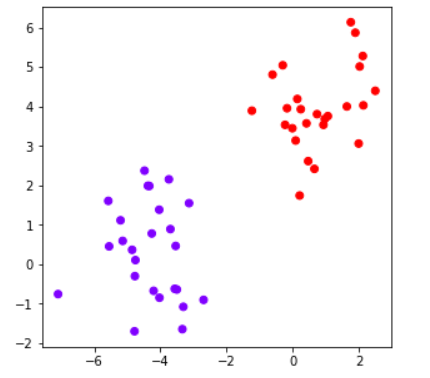
plt.scatter(X[:, 0], X[:, 1], label=y)
plt.xlabel("$x_1$")
plt.ylabel("$x_2$")
输出[2]:
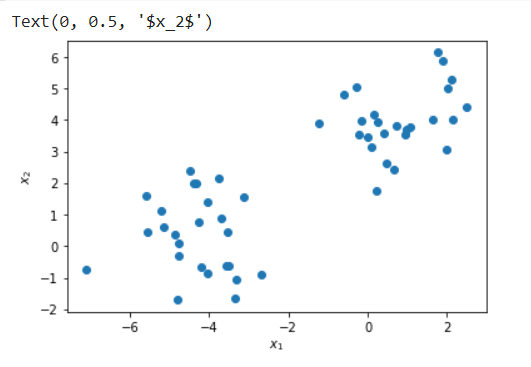
用Python Scipy创建树状图
Python Scipy在scipy.cluster.hierarchy包中有endrogram和linkage模块,可以用来创建聚类的endrogram图。
在这里,我们首先创建一个链接对象,方法为ward,亲和度量为euclidean,然后用它来创建树状图。
在[3]中:
#Dendrogram plot
输出[3]:
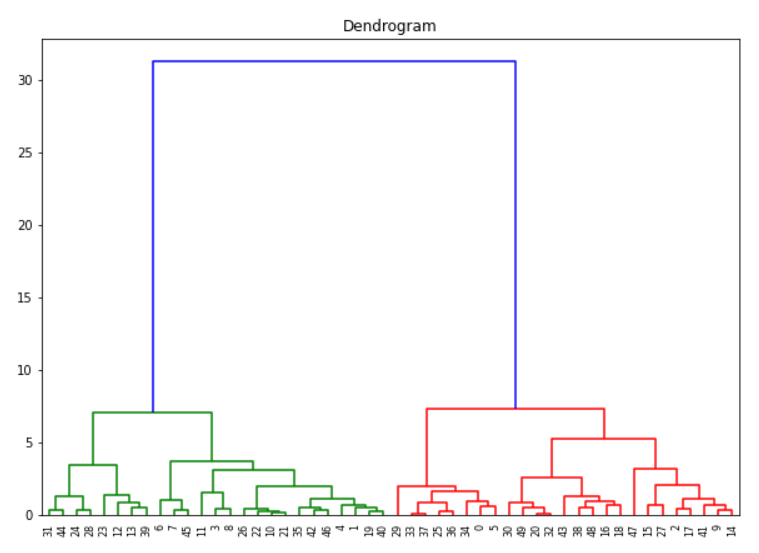
用树状图确定聚类的数量
如果你想创建平坦的聚类,我们可以通过分析上述树状图来确定聚类的数量。我们首先假设水平线向两边延伸,因此,它们也会与垂直线相交。现在我们必须找出没有任何水平线穿过的最高的垂直线。
在上面的树状图中,这样的垂直线就是蓝线。现在我们在这条垂直线上画一条水平线,如下图所示。这条水平线在两个地方切断了垂直线,这意味着最优的集群数量是2。
另一种方法是直观地看到哪条垂直线显示出最大的跳跃。因为垂直线表示两个集群之间的距离或相似度,大跳表示这两个集群不是很相似。再一次通过这条垂直线画出水平线,它的切口数量就是最佳的集群数量。同样在我们的例子中,它是蓝色的线,水平线在两个地方切割,所以集群的数量是2。
(然而,应该注意的是,这些方法并不总是能保证最优的集群数量,它只是一个指导原则。)
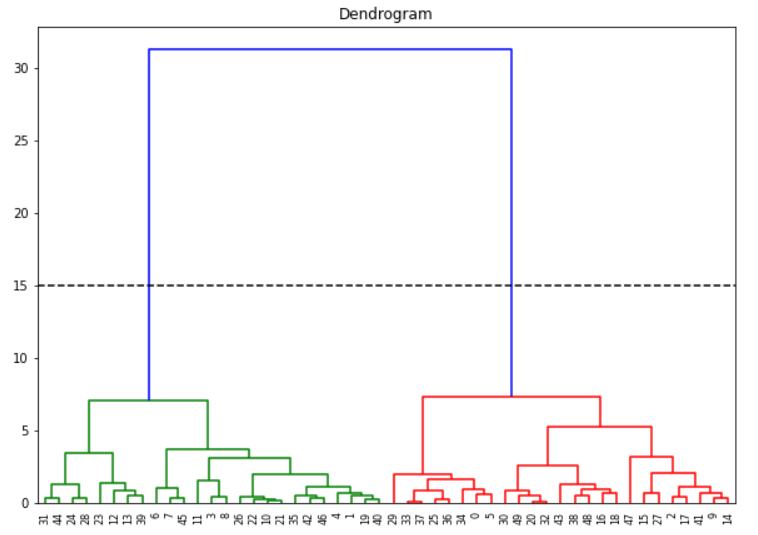
用Sklearn进行聚类分析
我们现在使用sklearn.cluster包中的AgglomerativeClustering模块,通过传递集群数量为2(在上一节中确定)来创建平面集群。我们再次使用euclidean和ward作为参数。
这样就产生了两个聚类,从视觉上我们可以说,结果是好的,符合预期。
In[4]:
cluster_ea = AgglomerativeClustering(n_clusters=2, linkage='ward',affinity='euclidean')
Out[4]: