

缺失值是很常见的,发生的原因可能是人为错误、仪器错误、来自另一个团队的处理,或者其他方面只是缺少某个观察点的数据。
在这个字节中,我们将看看如何在
DataFrame,如果你选择通过填充NaN来处理的话。
首先,让我们创建一个模拟的DataFrame ,并丢掉一些随机值:
import numpy as np
array = np.random.randn(25, 3)
mask = np.random.choice([1, 0], array.shape, p=[.3, .7]).astype(bool)
array[mask] = np.nan
df = pd.DataFrame(array, columns=['Col1', 'Col2', 'Col3'])
Col1 Col2 Col3
0 -0.671603 -0.792415 0.783922
1 0.207720 NaN 0.996131
2 -0.892115 -1.282333 NaN
3 -0.315598 -2.371529 -1.959646
4 NaN NaN -0.584636
5 0.314736 -0.692732 -0.303951
6 0.355121 NaN NaN
7 NaN -1.900148 1.230828
8 -1.795468 0.490953 NaN
9 -0.678491 -0.087815 NaN
10 0.755714 0.550589 -0.702019
11 0.951908 -0.529933 0.344544
12 NaN 0.075340 -0.187669
13 NaN 0.314342 -0.936066
14 NaN 1.293355 0.098964
让我们绘制一下,比如说,第三列:
plt.plot(df['Col3'])
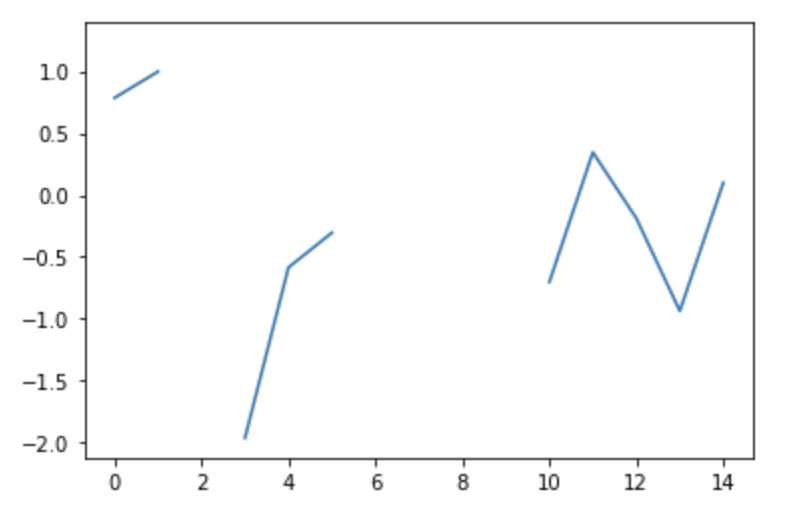
当用各种技术填充时--这个充满NaN的图形可以被替换成。

fillna() - 平均数、中位数、模式
你可以把这些值填充到一个新的列中,然后把它分配给你想填充的列,或者使用inplace 参数在原地填充。在这里,我们将在一个新的列中提取填充的值,以方便检查:
mean = df['Col3'].fillna(df['Col3'].mean(), inplace=False)
median = df['Col3'].fillna(df['Col3'].median(), inplace=False)
mode = df['Col3'].fillna(df['Col3'].mode(), inplace=False)
这一列的中位数、平均值和模式是-0.187669,-0.110873 和0.000000 ,这些值将分别用于每个NaN。这实际上是用常量值进行填充,输入的值取决于该列的属性。
首先,用中值填充的结果是:

使用平均值:

有了模式值:

fillna() - 常量值
你也可以用一个常量值来代替填充:
constant = df['Col3'].fillna(0, inplace=False
这导致一个常量值(0)被放入,而不是每个NaN。0 ,接近我们的中位数和平均值,并等于模式,所以对于我们的模拟数据集,填充的值将与该方法非常相似:
0 0.783922
1 0.996131
2 0.000000
3 -1.959646
4 -0.584636
5 -0.303951
6 0.000000
7 1.230828
8 0.000000
9 0.000000
10 -0.702019
11 0.344544
12 -0.187669
13 -0.936066
14 0.098964

fillna() - 前向和后向填充
在每一行--你可以做一个向前或向后的填充,从之前或之后的行中取值。
ffill = df['Col3'].fillna(method='ffill')
bfill = df['Col3'].fillna(method='bfill')
在前向填充中,由于我们在第2行缺失,所以从第1行取值来填充第二行。这些值会向前传播:
0 0.783922
1 0.996131
2 0.996131
3 -1.959646
4 -0.584636
5 -0.303951
6 -0.303951
7 1.230828
8 1.230828
9 1.230828
10 -0.702019
11 0.344544
12 -0.187669
13 -0.936066
14 0.098964

在后向填充的情况下,情况正好相反。第2行用第3行的值来填充:
0 0.783922
1 0.996131
2 -1.959646
3 -1.959646
4 -0.584636
5 -0.303951
6 1.230828
7 1.230828
8 -0.702019
9 -0.702019
10 -0.702019
11 0.344544
12 -0.187669
13 -0.936066
14 0.098964

不过,如果在一个序列中有多个NaN ,这些就不会做得很好,而且会进一步串联NaN,使数据发生偏移,并删除实际记录的值。
插值()
interpolate() 方法将数值的插值委托给SciPy用于插值的一套方法。它接受各种各样的参数,包括:nearest,zero,slinear,quadratic,cubic,spline,barycentric,polynomial,krogh,piecewise_polynomial,spline,pchip,akima,cubicspline 等。
内插法比以前的方法只是用常数或半变量填充数值要灵活和 "聪明 "得多。
插值可以正确地填充一个序列,这是其他方法所不能做到的,比如说:
s = pd.Series([0, 1, np.nan, np.nan, np.nan, 5])
s.fillna(s.mean()).values
# array([0., 1., 2., 2., 2., 5.])
s.fillna(method='ffill').values
# array([0., 1., 1., 1., 1., 5.])
s.interpolate().values
# array([0., 1., 2., 3., 4., 5.])
默认的插值是线性的,假设1...5 ,很可能是一个1, 2, 3, 4, 5 的序列并不牵强(但不保证)。常数填充和前向或后向填充在这里都惨遭失败。一般来说--当涉及到填补嘈杂信号中的NaN或损坏的数据集时,插值通常会是一个好朋友。
实验一下插值的类型可能会产生更好的结果。
这里有两种插值方法(splice 和polynomial 需要一个order 参数):
nearest = df['Col3'].interpolate(method='nearest')
polynomial = df['Col3'].interpolate(method='polynomial', order=3)
这些结果是:

和:

