

简介
2006年,Clive Humby说:"数据是新的石油",此后,业界一直在高呼 "钻探,宝贝,钻探"。就像石油一样,数据需要被提炼/处理/转化以释放其全部价值。俗话说,"必要性是发明之母",所以这个行业已经围绕着数据(科学、工程、平台、仓库)孕育了整个专业,以提取这种价值。这个比喻仍然很贴切,因为就像石油一样,数据现在正被当作一种潜在的危险材料来尊重。随着GDPR、CCPA以及它们未来的兄弟,我们已经明白了正确包装和安全保存数据资产的重要性。在我的道奇霓虹灯的后备箱里不再有密封袋装的数据胶浆。在24小时监控下,用大挂锁整齐堆放的铁箱,可以在一瞬间被加密粉碎,这是数据管理的未来。通过Auth0的这个新平台计划,我们有机会将一些现代的做法应用到我们的数据基础设施中,并向这个乌托邦式的数据未来迈出了另一步。
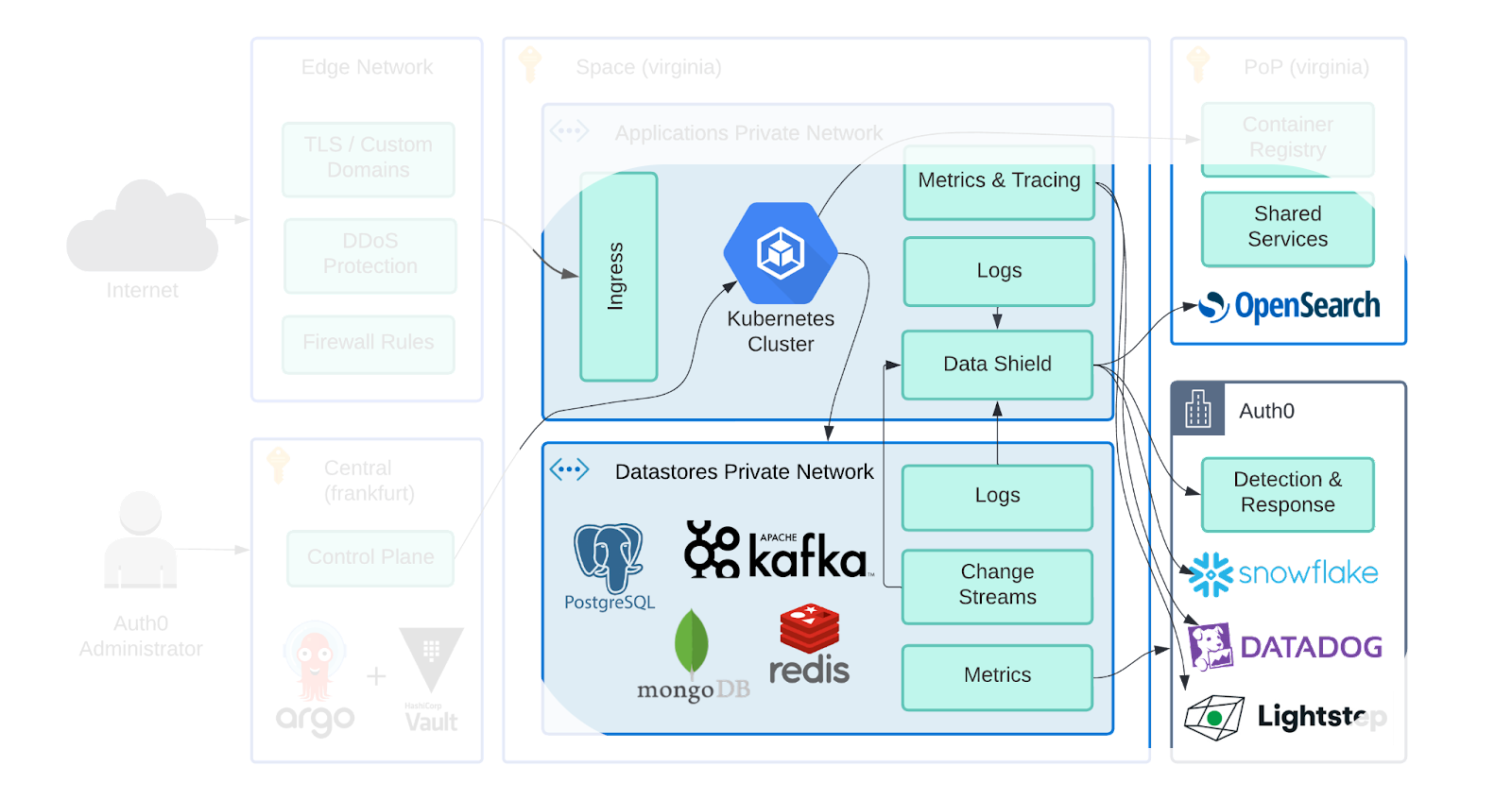
从Leo在 "新平台的架构"中的10k英尺视角出发,我们将在这篇文章中讨论该平台的重点部分。我们将从一些介绍性的背景开始,讨论我们的指导原则,深入研究我们选择的工具,然后用一些在Auth0常见的示例场景来锻炼它们。
放下那一袋数据,让我们开始吧!
什么是数据管道?
*"在一个SaaS和微服务已经占领的世界里......"-*电影配音员
环顾四周
"嘿,他说的是我们!"
软件正处于复杂性的曲棍球式增长曲线上。我们有越来越多的不同的系统囤积数据,而对我们从这些数据中解锁价值的要求甚至更高:
- "向我展示凭证填充攻击的源头地区" - 一个客户的仪表盘
- "让我在用户被删除后立即在Auth0行动中运行自定义代码" - 一个功能请求
- "向我展示过去60天内所有在性能级别上的租户的失败登录次数,这些租户已经成为一年以上的付费客户" - 一个追加销售的机会
在我们开始实际回答这些问题之前,我们需要一个连接组织,将数据从A点运送到B点,用E来充实,并通过T来转换,这就是数据管道的作用。
这并不是说,数据管道只是承载简单的领域/产品事件。应用程序日志、异常堆栈跟踪、Stripe采购订单、Salesforce计费更新等,都是可以被发射并流经管道的事件。
*"数据管道是一系列的管道"。-*迈克尔-斯科特
嗯,足够接近了。
我们的指导原则
在开始实施之前,重要的是要了解我们的要求不一定是你的要求。我们所做的决定对你来说可能不是正确的决定。在评估解决方案和讨论权衡时,这些是帮助指导我们的一些关键点。
活动的持久性
事件的持久性对我们来说是一个极其重要的要求;缺失和失序的事件是不可取的。
如果我们设想发射一个简单的事件,例如 "UserCreated",有几种方法:
- 来自应用程序代码的集成/域事件
- 发件箱模式
- 变更数据捕获(CDC)
讨论这些方法之间的权衡本身就是一篇博文,所以我只想说,它们是互补的,适合不同的需求,主要的权衡是耐久性与耦合性。
由应用程序代码发出的事件可能会在双重写入过程中因故障而丢失。如果你选择的数据库没有强大的交易保证,Outbox模式就会陷入困境,并使你的写入负荷翻倍。变更数据捕获(CDC)是三种模式中最持久的,但在每个事件中 "运送 "数据库表模式,促进了不必要的紧密耦合,并且只能对修改的行进行有限的访问。
数据治理 (O Data, Where art thou?)
数据管线有不同的形状和大小:
- 消息是否被序列化为Avro、JSON或Protobuf?XML吗?蛐蛐儿。
- 它们是加密的还是纯文本的?
- 预期的吞吐量是多少?是持续的还是突发的?
- 流动还是批量处理?
- 生产者在停机期间是重试还是放弃事件?
- 我们需要应用哪些丰富的内容/转换?
在讨论管道的这些技术细节之前,我们必须首先考虑什么是 在管线。
- 管道内的消息是否包含客户数据?
- 管道内的消息是否需要离开它们的发源地?
如果你对前面的一个或多个问题回答 "是",请冷静地到外面去把你的电脑点着。开玩笑,通过询问和回答这些问题,你可以开始了解你必须采取的安全/合规姿态。这很可能会导致你提出更多的问题:
- 相对于数据产生的地方,数据被运送到哪个地区?
- 我们是在发送综合数据还是单个记录?
- 这些数据在运输途中和休息时是如何加密的?
- 我们正在处理哪些客户数据(精确到每个单独的字段)?
- 是否有足以使每个字段符合规定的处理方法,同时还能满足业务需要?屏蔽、部分编辑、散列、加密,等等。
请记住,数据是一种宝贵的资源,但也可能是一种危险的材料,必须妥善处理。如果你发现有处理客户数据并跨地域运输的情况,给自己找一个合规部门的伙伴来帮助解决这个问题。
惯性
事件流技术是一个活跃的发展领域,许多新的公司和产品进入这一领域。这很好,因为我们可以站在巨人的肩膀上,但如果你不小心,它可能会让你容易出现痛苦的流失、废弃、不兼容或整个产品破产。
虽然我们不想完全跳进无聊技术俱乐部的池子里,但我们确实想建立在强大的工具上,使其在炒作周期中幸存下来。如果一个项目没有足够的惯性和社区购买力,无法在最初的管理者离开后继续生存下去,那么最好的办法就是考虑换一个项目。
构成
生活中唯一不变的是变化,尤其是技术和商业需求。我们需要考虑我们的技术选择是如何组成、合并、弯曲、破碎和涂抹在一起以完成工作的。如果我们选择的解决方案过于死板,它就会经常被重写。一个太灵活的解决方案不太可能被完全理解。我们应该尝试使用能提供健康平衡的工具。
孤军奋战是很危险的!拿着这个
值得庆幸的是,我们不是唯一一家建立在数据管道技术上的公司。我们可以站在前人的肩膀上。利用我们上述的指导原则,以下是我们选择的开放源码技术的字母汤,以使我们的数据得到发展。
卡夫卡
最初的Auth0平台只在AWS上运行,并大量利用Kinesis、SQS和RabbitMQ。在评估新平台的云计算解决方案时,我们很难拒绝Kafka。随着大多数云供应商提供托管解决方案(或API兼容层),它正在成为耐用事件后端的通用语言。通过相对合理的方法来实现静态或飞行中的加密,它可以满足我们大部分的需求。
Kafka Connect
Kafka Connect有一个坚实的集成生态系统,相对来说是即插即用的(尽管模式与无模式的对比可能是个问题)。AWS S3的水槽连接器对我们来说是可用的,而在Elasticsearch许可分叉事件后,一个开源的Opensearch连接器很快就出现了。
连接器内的单一消息转换(SMT)是对所有消息进行无状态转换/强化的简单机制。这对我们注入新平台的静态元数据很有效,如空间、POP、云、当前部署版本等。
模式注册表
Kafka Connect大量利用 Confluent Schema Registry进行消息序列化和验证。虽然有些连接器支持 "无模式 "的消息,但如果你不利用这些工具的注册表,你会发现自己和我们一样,在上游游走。我们还没有完全实现我们的愿景,并计划在未来几个季度进一步投资。
债务
正如我之前提到的,事件的持久性对我们来说是一个非常重要的要求,所以我们开始使用由Debezium提供的变更数据捕获(CDC)。有了他们的MongoDB和Postgres源连接器,我们马上就可以插入到Kafka Connect生态系统中。
数据保护
当涉及到流媒体消息的数据策略执行时,似乎没有很多免费/开源的解决方案,我们可以从货架上拿下来。为此,我们用golang编写了自己的内部解决方案。
Data Shield通过模式、数据突变和主题混合来处理数据策略的执行。有了它,我们可以使用类似protobuf的IDL来定义流经一个主题的事件。该IDL与主题中的序列化格式无关,例如,我们可以对JSON事件使用protobuf IDL。
让我们走过一个快速的例子。比方说,我们发出的公司记录事件有一个EIN字段:
message Company {
string name = 1;
string address = 2;
string ein = 3;
string url = 4;
}
默认情况下,字段的执行是零信任的,所以任何没有在IDL中定义的字段都被自动排除。这对我们来说是一个重要的能力,因为我们收到很多基于JSON/BSON的事件,这些事件的模式很松散,字段很容易被上游的生产者添加/删除。这最大限度地减少了上游服务意外地或有意地在离开该地区的流中产生新的客户数据字段的爆炸半径。
使用IDL,我们用政策细节注释字段,如分类和处理规则。从我们公司的例子来看,让我们假设这个 因字段被分类为个人身份信息(PII)。我们可以将其建模为:
string ein = 3 [
json_name = "ein",
(auth0.proto.options.fields.v1.classification) = {
classification: PII,
},
(auth0.proto.options.fields.v1.transform) = {
processor: {
name: OPENSEARCH,
transforms: [
{ mask: { length: 4, character: "*", reverse: true } }
]
},
processor: {
name: FRAUD_DETECTION,
transforms: []
},
processor: {
name: EU_DATA_LAKE,
transforms: [
{ drop: { } }
]
},
}
}
];
流的每个独立的数据处理器可以根据他们的业务功能应用他们自己的独立规则。在这种情况下,我们在Opensearch的Observability堆栈的最后四个字符被屏蔽了,我们的欺诈检测功能以纯文本形式接收该值,而欧盟的数据湖处理器根本不接收。
通过这个IDL定义和一些小的服务配置,我们可以告诉Data Shield在一个或多个主题上执行政策。在简单的情况下,它将接收传入的 "脏 "主题并输出 "干净 "主题,每个数据处理器都有一个,并应用其特定规则:
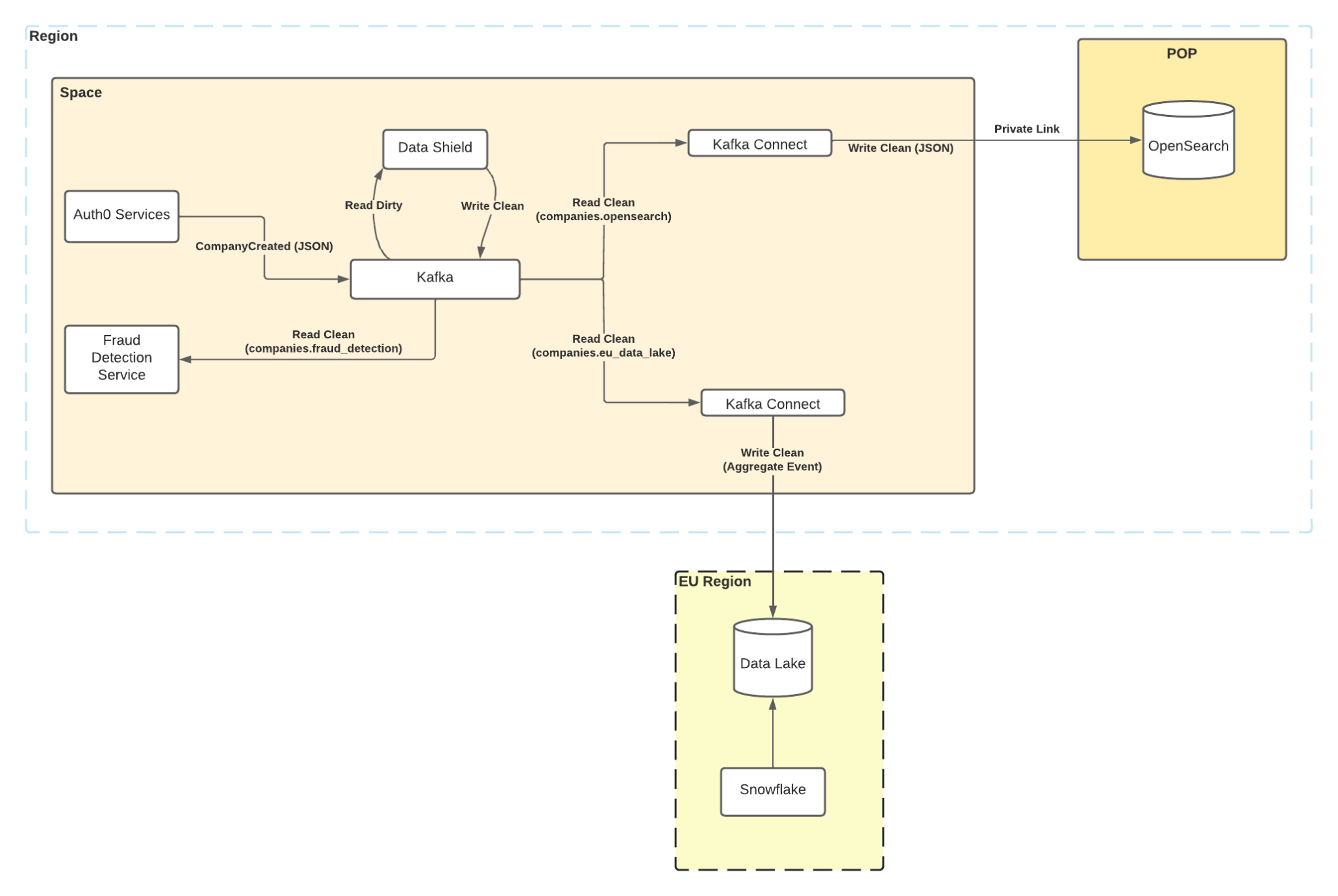
这种多路复用增加了我们的存储成本,但允许我们利用不同的保留策略和Kafka ACL,所以消费者只能从他们指定的主题中访问数据。虽然这是我们(目前)愿意为严格的数据隔离支付的成本,但这是一个未来投资的领域,有可能采取 "阅读时解密和模式强制 "策略。
随着我们对数据保护概念的迭代,我们又增加了一些功能,使我们的生活更容易。
- 一对多主题到IDL模式的映射,用于具有异质消息类型的主题。这对于包含应用/服务日志的主题非常有帮助。
- 模式格式转换,例如,读取JSON,写入Avro
- 扩展IDL以支持用生成的运行时值丰富字段
- Golang API用于可插拔动作,在事件流过时修改处理管道
- 对可能被淹没的汇的基于速率的采样
场景
有了这些工具的指导原则,让我们描绘一下我们在新的Auth0平台上运行的几个简化的场景。
用于事件响应的应用日志
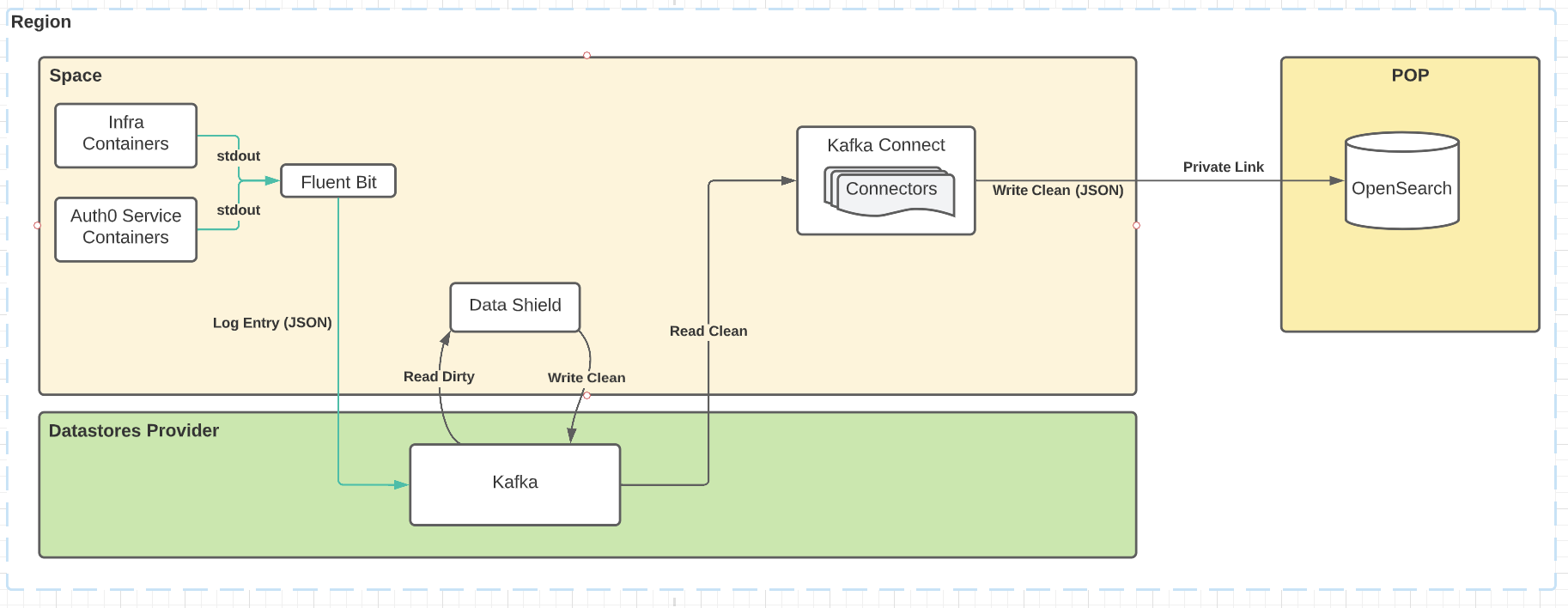
在这个场景中,我们使用Fluent Bit来消费来自Space Kubernetes集群内所有pod的服务日志。它们被运送到Kafka,在那里,Data Shield消费原始日志信息,应用其执行规则,并将它们生产回Kafka。它们被Opensearch连接器消耗,后者将它们通过私有链路运送到POP,在那里,运营团队可以访问它们以进行事件响应。
自动完成搜索的事件
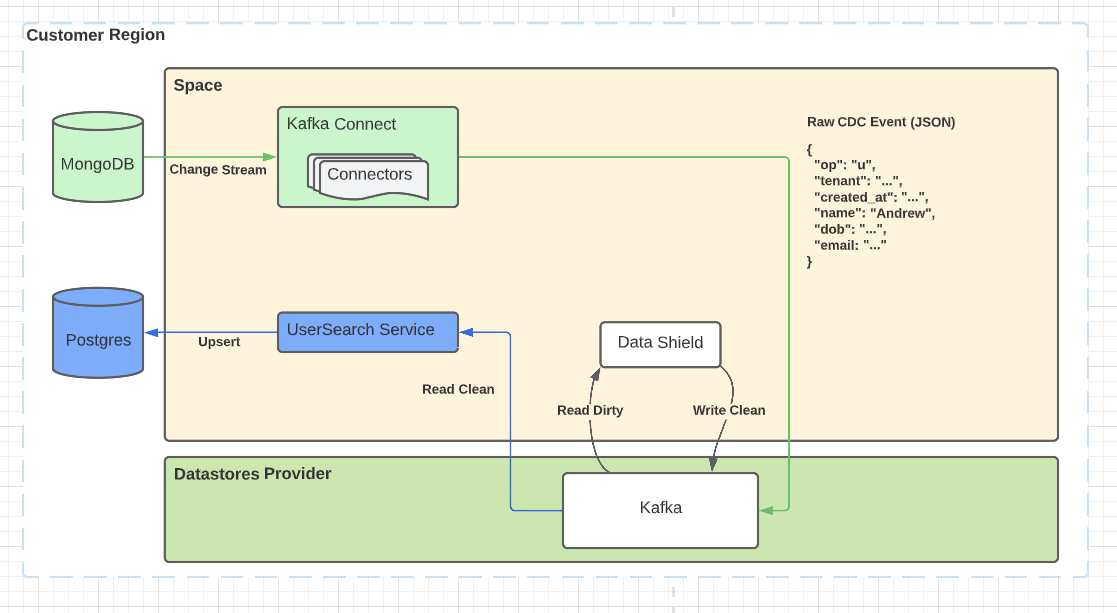
在这种情况下,我们使用Debezium来消费MongoDB的变化流,将Auth0用户的事件发射到Kafka。Data Shield消耗它们,应用它的执行规则,转换结构,并将它们产生回Kafka。它们被另一个服务所消耗,该服务处理它们并将它们写入运行在同一区域的Postgres中。
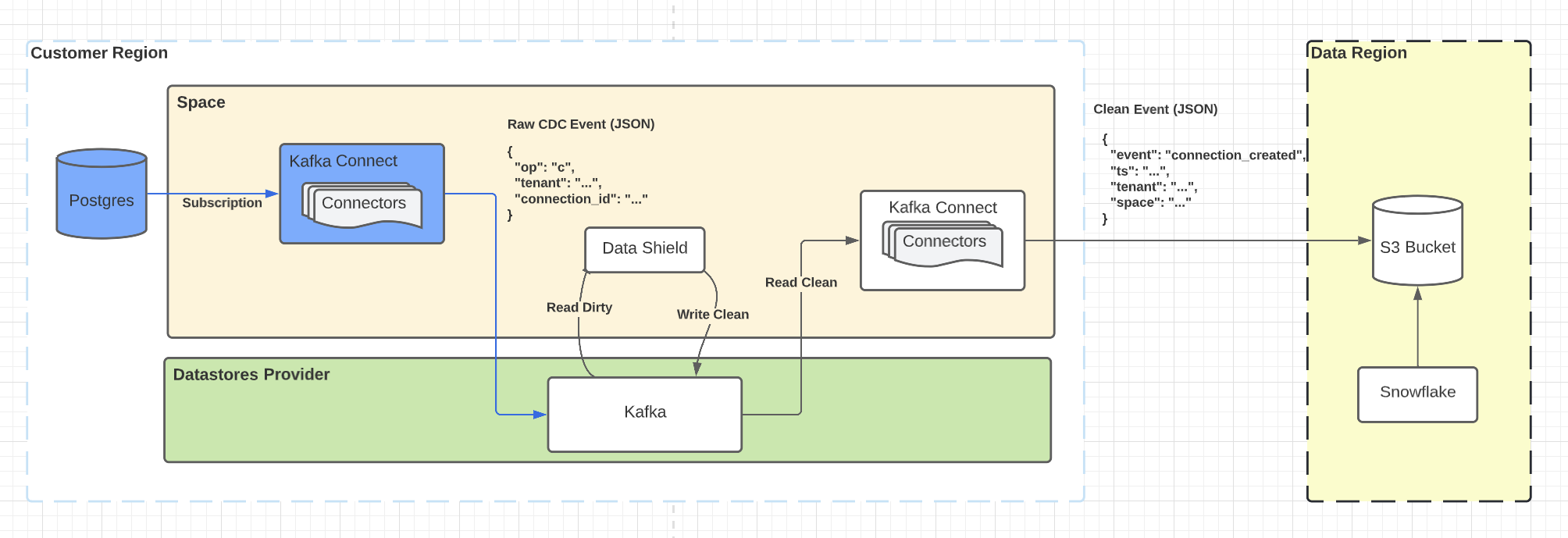
事件计数到数据湖
在这个场景中,我们使用Debezium来消费Postgres的逻辑复制协议,将Auth0连接的事件发射到Kafka。Data Shield消费它们,应用其执行规则,并将它们送回Kafka。它们被S3连接器所消耗,这些连接器将它们运送到运行在不同地区的S3桶。
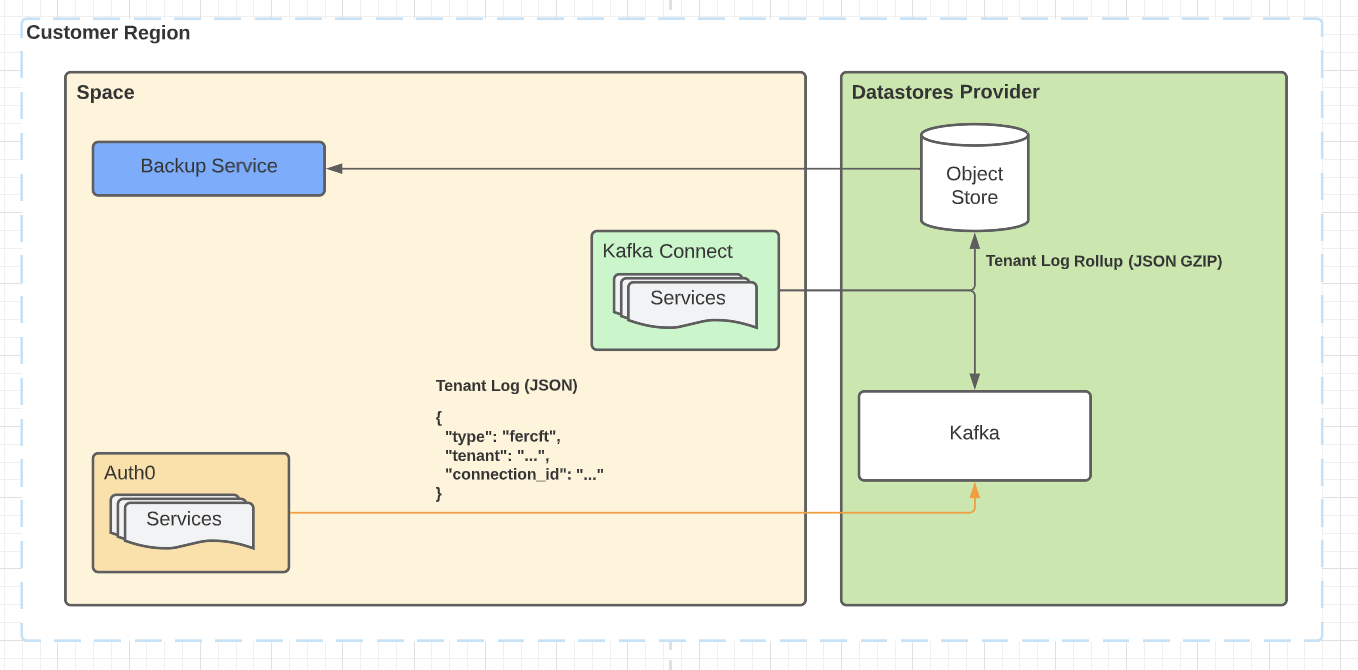
用户要求的备份
在这种情况下,我们将Auth0租户的产品事件发射到Kafka。在由Data Shield处理之前,它们在区域内被备份到对象存储。然后,这些备份会定期滚动起来,并根据用户的要求在仪表板上以数据下载的方式提供。
我们才刚刚开始
尽管这些示例场景并不十分复杂,但它们确实显示了可组合性的力量。我们可以将一些Kafka连接器与Data Shield混合在一起,以满足我们客户的需求,同时提供我们所需要的数据控制。随着更多需要流处理和OLAP数据库的数据密集型用例的出现,这种可组合性意味着我们的管道可以轻松发展以支持它们。更重要的是,即使有一个在流处理和OLAP数据库方面经验丰富的团队,我们仍然会计划一个研发阶段,以确保我们的选择再次符合我们的指导原则。
有兴趣听到更多关于流式连接、窗口化和OLAP数据库的信息吗?好吧,那你就等着看我的下一篇博文吧!Muahaha。
