本文已参与「新人创作礼」活动,一起开启掘金创作之路。
获取更多资讯,赶快关注《智能制造与智能调度》公众号吧!
【强化学习系列】
- 第一章 强化学习及OpenAI Gym介绍-强化学习理论学习与代码实现(强化学习导论第二版)
- 第二章 马尔科夫决策过程和贝尔曼等式-强化学习理论学习与代码实现(强化学习导论第二版)
- 第三章 动态规划-基于模型的RL-强化学习理论学习与代码实现(强化学习导论第二版)
- 第四章 蒙特卡洛方法-强化学习理论学习与代码实现(强化学习导论第二版)
- 第五章 基于时序差分和Q学习的无模型预测与控制-强化学习理论学习与代码实现(强化学习导论第二版)
- 第六章 函数逼近-强化学习理论学习与代码实现(强化学习导论第二版)
- 第七章 深度强化学习-深度Q网络系列1(Deep Q-Networks,DQN)
- 第八章 深度强化学习-Nature深度Q网络(Nature DQN)
- 第九章 深度强化学习-Double DQN
- 第十章 深度强化学习-Prioritized Replay DQN
- (本文)第十一章 策略梯度(Policy Gradient)-强化学习理论学习与代码实现(强化学习导论第二版)
@[TOC]
“前言”
在前面讲到的 DQN 系列强化学习算法中,我们主要对价值函数进行了近似表示,基于价值来学习策略。这种基于价值的强化学习方法在很多领域都得到比较好的应用,但是也有很多局限性,因此在另一些场景下需要借助其他的方法。
从本片博文开始,我们将进入基于策略的强化学习,该类方法直接对策略进行参数化,从而显式地将策略表示出来,策略的获取不再和值函数有关,并根据期望报酬相对于策略参数的梯度进行更新。
11.1 强化学习分类
强化学习按照学习方式的不同可以分为:基于值函数的强化学习、基于策略的强化学习和两者结合的 Actor-Critic 方法。
- 基于值函数的强化学习:通过学习值函数,隐式地获取策略(如 -贪婪策略);
- 基于策略地强化学习:不需要学习值函数,而是直接通过对策略参数化进行学习,因而是显式的;
- Actor-Critic:既学习值函数又学习策略,集众家之所长。

图1 强化学习分类11.2 基于值函数的强化学习方法的不足
DQN 系列强化学习算法主要的问题主要有三点。
- 对连续动作的处理能力不足。DQN 之类的方法一般都是只处理离散动作,无法处理连续动作,像开车这样的环境中,动作往往是油门大小和方向盘角度,这两个值都是一定范围内的实数,有无数种选择,以 DQN 为代表的基于值函数的方法,需要通过最大化操作确定动作,最大化本质上是一个优化过程,那么强化学习没学习一步都要进行这样的优化势必导致学习过程相当缓慢,但是基于策略的强化学习方法却很容易建模。
- 对受限状态下的问题处理能力不足。在使用特征来描述状态空间中的某一个状态时,有可能因为个体观测的限制或者建模的局限,导致真实环境下本来不同的两个状态却在我们建模后拥有相同的特征描述,进而很有可能导致我们的基于值函数的方法无法得到最优解。此时使用基于策略的强化学习方法也很有效。
- 无法解决随机策略问题。基于值函数的强化学习方法对应的最优策略通常是确定性策略,因为其是从众多动作价值中选择一个最大价值的动作,而有些问题的最优策略却是随机策略,这种情况下同样是无法通过基于值函数的学习来求解的。这时也可以考虑使用基于策略的强化学习方法。
由于上面这些原因,基于值函数的强化学习方法不能通吃所有的场景,我们需要新的解决上述类别问题的方法,这就是今天要讲的基于策略的强化学习方法。
11.3 基于策略的强化学习表示
在之前的部分我们都是使用参数 来近似值函数或动作值函数的:
V_{\theta}(s) & \approx V^{\pi}(s) \\
Q_{\theta}(s, a) & \approx Q^{\pi}(s, a)
\end{aligned}$$
对于基于策略的方法我们采用了同样的思路,不同的是现在直接对策略进行参数化:
$$\pi_{\theta}(s,a) = P(a|s,\theta)\approx \pi(a|s)$$
将策略表示成一个连续的函数后,我们就可以用连续函数的优化方法来寻找最优的策略了。而最常用的方法就是梯度上升法了,那么这个梯度对应的优化目标如何定义呢?
## 11.4 策略目标函数
给定参数为 $\theta$ 的策略 $\pi_{\theta}(s, a)$,目的是要找到最优的 $\theta$,但是如何评价一个策略 $\pi_{\theta}$ 的好坏呢?
在片段环境中我们可以使用**初始值**作为优化目标,即:
$$J_{1}(\theta)=V^{\pi_{\theta}}\left(s_{1}\right)=\mathbb{E}_{\pi_{\theta}}\left[v_{1}\right]$$
但是在连续环境中是没有明确的初始状态的,那么我们的优化目标可以定义**平均价值**,即:
$$J_{a v V}(\theta)=\sum_{s} d^{\pi_{\theta}}(s) V^{\pi_{\theta}}(s)$$
其中 $d^{\pi_{\theta}}(s)$ 是基于策略 $\pi_{\theta}$ 生成的马尔科夫链关于状态的静态分布。
或者定义为每一时间步的**平均奖励**,即:
$$J_{\operatorname{avR}}(\theta)=\sum_{s} d^{\pi_{\theta}}(s) \sum_{a} \pi_{\theta}(s, a) \mathcal{R}_{s}^{a}$$
无论我们是采用 $J_{1}$,$J_{a v V}$ 还是 $J_{\operatorname{avR}}$ 来表示优化目标,最终对 $\theta$ 求导的梯度都可以表示为:
$$\nabla_{\theta} J(\theta)=\mathbb{E}_{\pi_{\theta}}\left[\nabla_{\theta} \log \pi_{\theta}(s, a) Q^{\pi_{\theta}}(s, a)\right]$$
这就是**策略梯度理论**。
当然我们还可以采用很多其他可能的优化目标来做梯度上升,此时我们的梯度式子里面的 $\nabla_{\theta}log \pi_{\theta}(s,a)$ 部分并不改变,变化的只是后面的 $Q_{\pi}(s,a)]$ 部分。对于 $\nabla_{\theta}log \pi_{\theta}(s,a)$,我们一般称为**得分函数**(score function)。
现在梯度的式子已经有了,后面剩下的就是策略函数 $\pi_{\theta}(s,a)$ 的设计了。
## 11.5 策略函数的设计
现在我们回头看一下策略函数 $\pi_{\theta}(s,a)$ 的设计,在前面它一直是一个数学符号。
最常用的策略函数就是**softmax**策略函数了,它主要应用于离散空间中,softmax 策略使用描述状态和动作的特征 $\phi(s,a)$ 与参数 $\theta$ 的线性组合来权衡一个动作发生的几率,即:
$$\pi_{\theta}(s,a) = \frac{e^{\phi(s,a)^T\theta}}{\sum\limits_be^{\phi(s,b)^T\theta}}$$
则通过求导很容易求出对应的得分函数为:
$$\nabla_{\theta}log \pi_{\theta}(s,a) = \phi(s,a) - \mathbb{E}_{\pi_{\theta}}[\phi(s,.)]$$
在连续动作空间中常用的策略为**高斯策略**,该策略对应的动作从高斯分布 $\mathbb{N(\phi(s)^T\theta, \sigma^2)}$ 中产生。高斯策略对应的得分函数求导可以得到为:
$$\nabla_{\theta}log \pi_{\theta}(s,a) = \frac{(a-\phi(s)^T\theta)\phi(s)}{\sigma^2}$$
## 11.6 Monte-Carlo 策略梯度(REINFORCE)
这里我们讨论最简单的策略梯度算法,蒙特卡罗策略梯度 reinforce 算法, 使用价值函数 $v(s)$ 来近似代替策略梯度公式里面的 $Q_{\pi}(s,a)$。算法的流程很简单,如下所示:
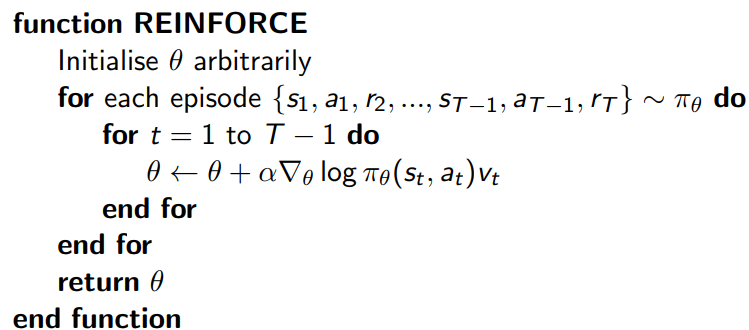
## 11.7 代码实现 REINFORCE
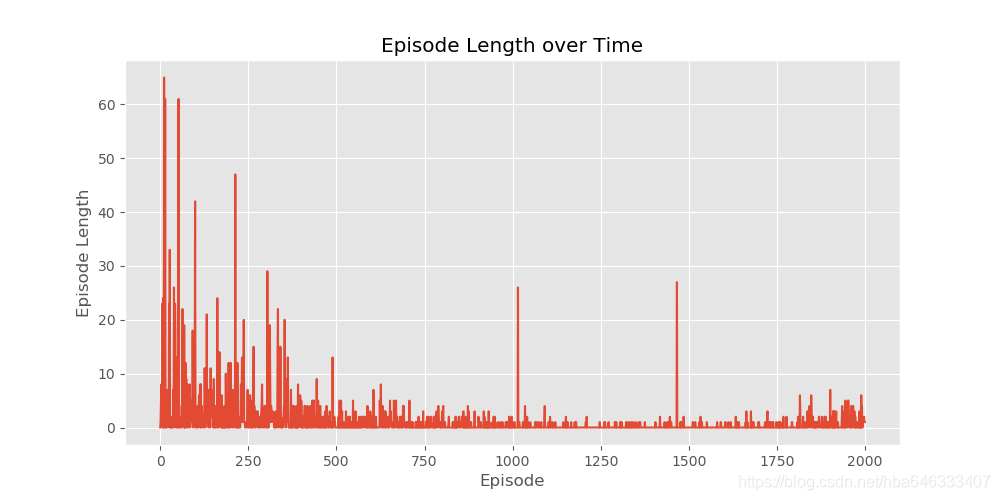
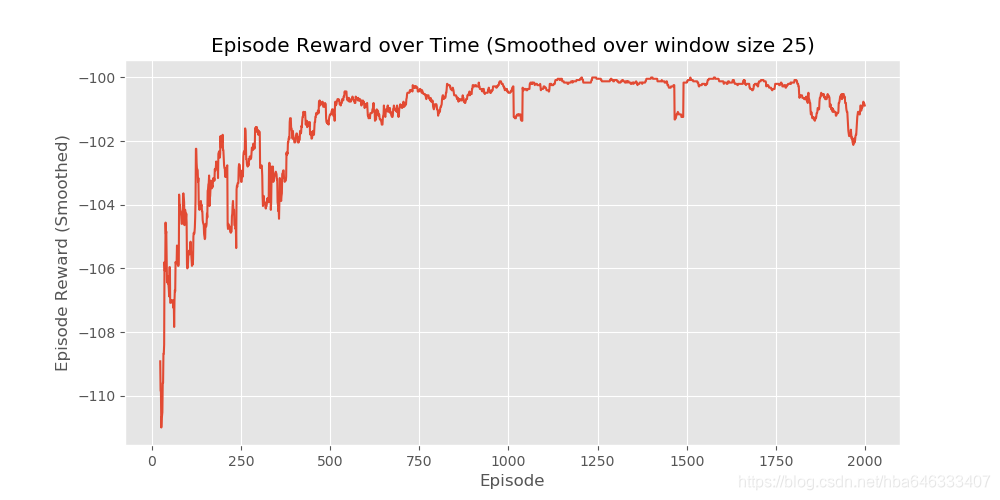
代码针对的环境的是 CliffWalkingEnv,在该环境中智能体在一个 4x12 的网格中移动,状态编号如下所示:
```
[[ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11],
[12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35],
[36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47]]
```
在任何阶段开始时,初始状态都是状态 36,状态 47 是唯一的终止状态,悬崖对应的是状态 37 到 46。智能体有 4 个可选动作(UP = 0,RIGHT = 1,DOWN = 2,LEFT = 3)。智能体每走一步都会得到-1 的奖励,跌入悬崖会得到-100 的奖励并重置到起点,当达到目标时,片段结束。
完整的代码如下:
```
import gym
import itertools
import matplotlib
import numpy as np
import sys
import tensorflow as tf
import collections
if "../" not in sys.path:
sys.path.append("../")
from Lib.envs.cliff_walking import CliffWalkingEnv
from Lib import plotting
matplotlib.style.use('ggplot')
env = CliffWalkingEnv()
class PolicyEstimator():
"""
策略函数逼近器
"""
def __init__(self, learning_rate=0.01, scope="policy_estimator"):
with tf.variable_scope(scope):
self.state = tf.placeholder(tf.int32, [], "state")
self.action = tf.placeholder(dtype=tf.int32, name="action")
self.target = tf.placeholder(dtype=tf.float32, name="target")
# 使用状态的独热形式表达
state_one_hot = tf.one_hot(self.state, int(env.observation_space.n))
self.output_layer = tf.contrib.layers.fully_connected(
inputs=tf.expand_dims(state_one_hot, 0),
num_outputs=env.action_space.n,
activation_fn=None,
weights_initializer=tf.zeros_initializer)
self.action_probs = tf.squeeze(tf.nn.softmax(self.output_layer))
self.picked_action_prob = tf.gather(self.action_probs, self.action)
# 损失
self.loss = -tf.log(self.picked_action_prob) * self.target
self.optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
self.train_op = self.optimizer.minimize(
self.loss, global_step=tf.contrib.framework.get_global_step())
def predict(self, state, sess=None):
sess = sess or tf.get_default_session()
return sess.run(self.action_probs, {self.state: state})
def update(self, state, target, action, sess=None):
sess = sess or tf.get_default_session()
feed_dict = {self.state: state, self.target: target, self.action: action}
_, loss = sess.run([self.train_op, self.loss], feed_dict)
return loss
class ValueEstimator():
"""
Value Function approximator.
"""
def __init__(self, learning_rate=0.1, scope="value_estimator"):
with tf.variable_scope(scope):
self.state = tf.placeholder(tf.int32, [], "state")
self.target = tf.placeholder(dtype=tf.float32, name="target")
# This is just table lookup estimator
state_one_hot = tf.one_hot(self.state, int(env.observation_space.n))
self.output_layer = tf.contrib.layers.fully_connected(
inputs=tf.expand_dims(state_one_hot, 0),
num_outputs=1,
activation_fn=None,
weights_initializer=tf.zeros_initializer)
self.value_estimate = tf.squeeze(self.output_layer)
self.loss = tf.squared_difference(self.value_estimate, self.target)
self.optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
self.train_op = self.optimizer.minimize(
self.loss, global_step=tf.contrib.framework.get_global_step())
def predict(self, state, sess=None):
sess = sess or tf.get_default_session()
return sess.run(self.value_estimate, {self.state: state})
def update(self, state, target, sess=None):
sess = sess or tf.get_default_session()
feed_dict = {self.state: state, self.target: target}
_, loss = sess.run([self.train_op, self.loss], feed_dict)
return loss
def reinforce(env, estimator_policy, estimator_value, num_episodes, discount_factor=1.0):
"""
REINFORCE (Monte Carlo策略梯度)算法.使用策略梯度优化策略函数逼近器.
参数:
env: OpenAI环境.
estimator_policy: 待优化的策略函数
estimator_value: Value function approximator, used as a baseline
num_episodes: 迭代次数
discount_factor: 折扣因子
返回值:
EpisodeStats对象,包含两个numpy数组,分别存储片段长度和片段奖励.
"""
# 统计有用信息
stats = plotting.EpisodeStats(
episode_lengths=np.zeros(num_episodes),
episode_rewards=np.zeros(num_episodes))
Transition = collections.namedtuple("Transition", ["state", "action", "reward", "next_state", "done"])
for i_episode in range(num_episodes):
# 重置环境
state = env.reset()
episode = []
# 环境中的每一步
for t in itertools.count():
# 单步执行
action_probs = estimator_policy.predict(state)
action = np.random.choice(np.arange(len(action_probs)), p=action_probs)
next_state, reward, done, _ = env.step(action)
# 记录转移
episode.append(Transition(
state=state, action=action, reward=reward, next_state=next_state, done=done))
# 更新统计
stats.episode_rewards[i_episode] += reward
stats.episode_lengths[i_episode] = t
print("\rStep {} @ Episode {}/{} ({})".format(
t, i_episode + 1, num_episodes, stats.episode_rewards[i_episode - 1]), end="")
# sys.stdout.flush()
if done:
break
state = next_state
# 遍历每个片段并进行策略更新
for t, transition in enumerate(episode):
# The return after this timestep
total_return = sum(discount_factor ** i * t.reward for i, t in enumerate(episode[t:]))
# Calculate baseline/advantage
# baseline_value = estimator_value.predict(transition.state)
# advantage = total_return - baseline_value
# Update our value estimator
# estimator_value.update(transition.state, total_return)
# 更新策略逼近器
estimator_policy.update(transition.state, total_return, transition.action)
return stats
tf.reset_default_graph()
global_step = tf.Variable(0, name="global_step", trainable=False)
policy_estimator = PolicyEstimator()
value_estimator = ValueEstimator()
with tf.Session() as sess:
sess.run(tf.initialize_all_variables())
# 注意,由于策略存在随机性,为了学习好的策略,一般片段数量为2000~5000
stats = reinforce(env, policy_estimator, value_estimator, 2000, discount_factor=1.0)
plotting.plot_episode_stats(stats, smoothing_window=25)
```