public static void main(String[] args){
Class clzzz = Class.forName("com.itheima.bean.User");
Object obj = clazz.newInstance();
Method method = clazz.getMethod("setUsername",String.class);
method.invoke(obj,"jack");
}
1.XML文档声明格式:<?xml version="1.0" encoding="UTF-8"?>
(2)文档声明必须从文档的0行0列位置开始
元素必须自己闭合
元素命名
(1)区分大小写
(2)不能使用空格,不能使用冒号:
(3)不建议以XML、xml、Xml开头
5.格式化良好的XML文档,必须只有一个根元素
<bean id="" className="">
属性名不能使用空格、冒号等特殊字符,且必须以字母开头
属性值,可以使用""或者'' 建议使用""
CDATA
因为很多符号已经被XML文档结构所使用,所以在元素体或属性值中想使用这些符号就必须使用转义字符。
例如:“<”、“>”、“’”、“””、“&”。
必须有
<!ATTLIST bean id CDATA #REQUIRED
className CDATA #REQUIRED
>
<?xml version="1.0" encoding="UTF-8" ?>
<!--
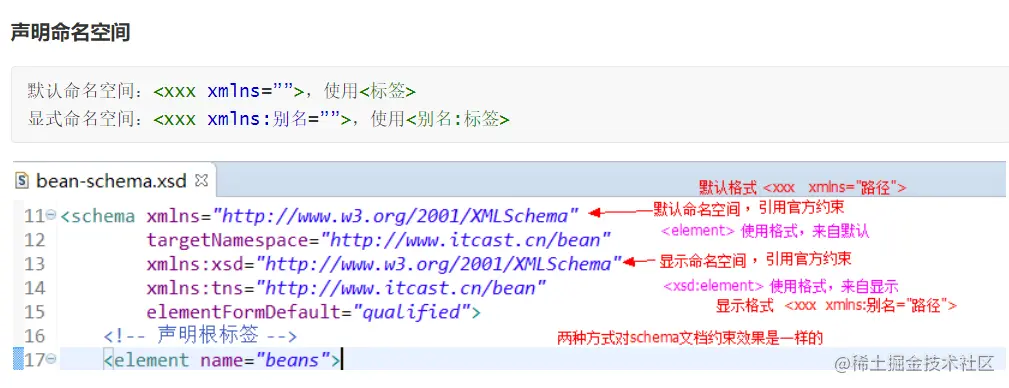
xmlns="schema约束文件的名称空间的名字" W3C要求名字要唯一 网址
xmlns的取值来自于schema文件的targetNamespace的值
xmlns:xsi="": 这个xml文件是XMLSchema约束的一个实例
xsi:schemaLocation="": schema约束文件的位置
http:
xmlns的值: http:
bean-schema.xsd: schema约束的文件名
-->
<beans xmlns="http://www.itcast.cn/bean"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.itcast.cn/bean bean-schema.xsd"
>
<import resource=""></import>
</beans>
1.SaxReader对象
read(…) 加载执行xml文档
2.Document对象
getRootElement() 获得根元素
3.Element对象
elements(…) 获得指定名称的所有子元素。可以不指定名称
element(…) 获得指定名称第一个子元素。可以不指定名称
getName() 获得当前元素的元素名
attributeValue(…) 获得指定属性名的属性值
elementText(…) 获得指定名称子元素的文本值
getText() 获得当前元素的文本内容
第三方工具(jar包)XPath:
作用: 快速查找xml文件中的一个/多个节点
注意: 必须依赖于dom4j
public List<Node> selectNodes("xpath表达式"),用来获取多个节点
public Node selectSingleNode("xpath表达式"),用来获取一个节点