

如果你正在编写Ruby代码,你很可能正在使用Sidekiq来处理后台处理。如果你来自ActiveJob 或其他背景,请继续关注,其中涉及的一些技巧也可以应用于此。
人们在不同情况下利用(Sidekiq)后台作业。无论你的情况如何,你最终可能会遇到避免重复作业的要求。我所说的重复作业,是指两个做了完全相同事情的作业。让我们深入了解一下这个问题。
为什么要去掉重复的工作?
想象一下,你的工作看起来像下面这样的情况:
class BookSalesWorker
include Sidekiq::Worker
def perform(book_id)
crunch_some_numbers(book_id)
upload_to_s3
end
...
end
BookSalesWorker 总是做同样的事情--根据book_id 查询数据库中的书,并获取最新的销售数据来计算一些数字。然后,它把它们上传到一个存储服务。请记住,每当你的网站上卖出一本书,你就会有这个工作被排队。
现在,如果你一次有100笔销售呢?你会有100个这样的工作,做完全相同的事情。也许你对这一点没有意见。你并不关心S3的写入量,而且你的队列也没有那么拥挤,所以你可以处理这个负载。 但是,"它可以扩展吗?" ™️
嗯,肯定不行。如果你开始收到更多书籍的销售,你的队列会很快堆满不必要的工作。如果你有100个工作为一本书做同样的事情,而你有10本书在平行销售,你现在在你的队列里有1000个工作,而实际上,你可以只为每本书准备10个工作。
现在,让我们来看看如何防止重复作业堆积在队列中的几个选项。
1.DIY方式
如果你不喜欢外部依赖和复杂的逻辑,你可以在你的代码库中添加一些自定义解决方案。我创建了一个样本 repo,以亲身尝试我们的例子。在每个方法中都会有一个指向例子的链接。
1.1 一个标志的方法
你可以添加一个标志,决定是否排队作业。人们可能会在他们的Book表中添加一个sales_enqueued_at ,并维护那一个比如说:
module BookSalesService
def schedule_with_one_flag(book)
# Check if the job was enqueued more than 10 minutes ago
if book.sales_enqueued_at < 10.minutes.ago
book.update(sales_enqueued_at: Time.current)
BookSalesWorker.perform_async(book.id)
end
end
end
这意味着没有新的工作将被排队,直到从上一个工作被排队的时间起10分钟过去。10分钟过后,我们再更新sales_enqueued_at ,排队等候新的工作。
你可以做的另一件事是设置一个布尔值的标志,例如:crunching_sales 。在第一个作业被排队之前,你将crunching_sales 设置为 "true"。然后,一旦作业完成,你就把它设置为假。所有其他试图被安排的作业将被拒绝,直到crunching_sales 为假。
1.2 两面旗子的方法
如果 "锁定 "一个作业10分钟,听起来太吓人了,但你仍然对代码中的额外标志感到满意,那么下一个建议可能会让你感兴趣。
你可以在现有的sales_enqueued_at ,添加另一个标志--sales_calculated_at 。然后我们的代码将看起来像这样:
module BookSalesService
def schedule_with_two_flags(book)
# Check if sales are being calculated right now
if book.sales_enqueued_at <= book.sales_calculated_at
book.update(sales_enqueued_at: Time.current)
BookSalesWorker.perform_async(book.id)
end
end
end
class BookSalesWorker
include Sidekiq::Worker
def perform(book_id)
crunch_some_numbers(book_id)
upload_to_s3
# New adition
book.update(sales_calculated_at: Time.current)
end
...
end
要想试一试,请查看例子 repo 中的说明。
现在,我们控制了作业被排队和完成之间的一部分时间。在这部分时间里,没有作业可以被排队。当作业正在运行时,sales_enqueued_at 将比sales_calculated_at 大。当作业运行结束时,sales_calculated_at 将比sales_enqueued_at 大(更近),新的作业将被排队。
使用两个标志可能很有趣,所以你可以在用户界面中显示这些销售数字最后一次被更新的时间。然后,阅读这些数据的用户就可以知道这些数据有多新。一个双赢的局面。
旗帜总结
在需要的时候创建这样的解决方案可能是很诱人的,但对我来说,它们看起来有点笨拙,而且会增加一些开销。如果你的用例很简单,我会推荐你使用这种方法,但一旦证明它很复杂或不够用,我会敦促你尝试其他的选择。
标志方法的一个巨大的缺点是,你会失去所有在这10分钟内试图排队的工作。一个巨大的优点是,你没有带入依赖关系,而且会很快缓解队列中的作业数量。
1.3 穿越队列
你可以采取的另一种方法是创建一个自定义的锁定机制,以防止相同的作业被排队。我们将检查我们感兴趣的Sidekiq队列,看看作业(工作者)是否已经在那里。代码看起来会是这样的。
module BookSalesService
def schedule_unique_across_queue(book)
queue = Sidekiq::Queue.new('default')
queue.each do |job|
return if job.klass == BookSalesWorker.to_s &&
job.args.join('') == book.id.to_s
end
BookSalesWorker.perform_async(book.id)
end
end
class BookSalesWorker
include Sidekiq::Worker
def perform(book_id)
crunch_some_numbers(book_id)
upload_to_s3
end
...
end
在上面的例子中,我们要检查'default' 队列中是否有一个类名为BookSalesWorker 的作业。我们还要检查作业参数是否与书的ID相符。如果队列中有相同书籍ID的BookSalesWorker 工作,我们将提前返回,不安排另一个工作。
注意,如果你因为队列是空的而过快地安排作业,其中一些可能被安排。我在本地用测试时发生了确切的事情。
100.times { BookSalesService.schedule_unique_across_queue(book) }
你可以在例子 repo中尝试一下。
这种方法的好处是,如果你需要的话,你可以遍历所有队列来搜索一个现有的作业。缺点是,如果你的队列是空的,而你一次安排了大量的工作,你仍然可能有重复的工作。 而且,你有可能在安排一个工作之前遍历队列中的所有工作,所以这可能是昂贵的,取决于你的队列的大小。
2.升级到Sidekiq企业版
如果你或你的组织有一些钱,你可以升级到Sidekiq的企业版。它的起价是每月179美元,而且它有一个很酷的功能,可以帮助你避免重复工作。不幸的是,我没有Sidekiq企业版,但我相信他们的文档是足够的。你可以通过以下代码轻松地拥有独特的(非重复的)作业:
class BookSalesWorker
include Sidekiq::Worker
sidekiq_options unique_for: 10.minutes
def perform(book_id)
crunch_some_numbers(book_id)
upload_to_s3
end
...
end
就这样了。你有一个类似于我们在"一个标志方法 "部分描述的作业实现。该作业在10分钟内是唯一的,这意味着在该时间段内没有其他具有相同参数的作业可以被安排。
很酷的一句话,是吧?好吧,如果你有Enterprise Sidekiq,而且你刚发现这个功能,我真的很高兴我帮了忙。我们大多数人都不会使用它,所以让我们跳到下一个解决方案。
3. sidekiq-unique-jobs的救援
是的,我知道我们要提到的是一个宝石。是的,它里面有一些Lua文件,这可能会让一些人不喜欢。但请忍耐一下,你将得到一个非常甜蜜的交易。sidekiq-unique-jobgem带有大量的锁定和其他配置选项--可能比你需要的要多。
为了快速入门,把sidekiq-unique-jobs gem放到你的Gemfile中,做bundle ,然后如图所示配置你的工作者:
class UniqueBookSalesWorker
include Sidekiq::Worker
sidekiq_options lock: :until_executed,
on_conflict: :reject
def perform(book_id)
book = Book.find(book_id)
logger.info "I am a Sidekiq Book Sales worker - I started"
sleep 2
logger.info "I am a Sidekiq Book Sales worker - I finished"
book.update(sales_calculated_at: Time.current)
book.update(crunching_sales: false)
end
end
有很多选项,但我决定简化并使用这个选项:
sidekiq_options lock: :until_executed, on_conflict: :reject
lock: :until_executed 将锁定第一个UniqueBookSalesWorker 工作,直到它被执行。使用on_conflict: :reject ,我们是说我们希望所有其他试图被执行的作业都被拒绝在死队列中。我们在这里取得的成果与我们在上面的主题中的DIY例子相似。
与那些DIY例子相比,有一点改进的是,我们有一种发生了什么的日志。为了了解它的情况,让我们试试下面的方法。
5.times { UniqueBookSalesWorker.perform_async(Book.last.id) }
只有一个作业会完全执行,其他四个作业会被送入死队列,在那里你可以重试它们。这种方法与我们的例子不同,我们只是忽略了重复的作业。
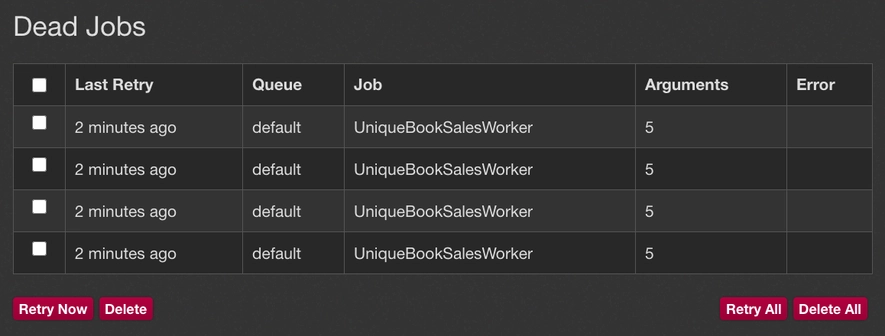
当涉及到锁定和冲突解决时,有很多选项可以选择。我建议你针对你的具体使用情况查阅该宝石的文档。
伟大的洞察力
这个工具的好处是,你可以查看锁和队列中发生的历史。你所需要做的就是在你的config/routes.rb 。
# config/routes.rb
require 'sidekiq_unique_jobs/web'
Rails.application.routes.draw do
mount Sidekiq::Web, at: '/sidekiq'
end
它将包括原始的Sidekiq客户端,但它也会给你提供两个页面--一个是作业锁,另一个是变更日志。这就是它的样子:
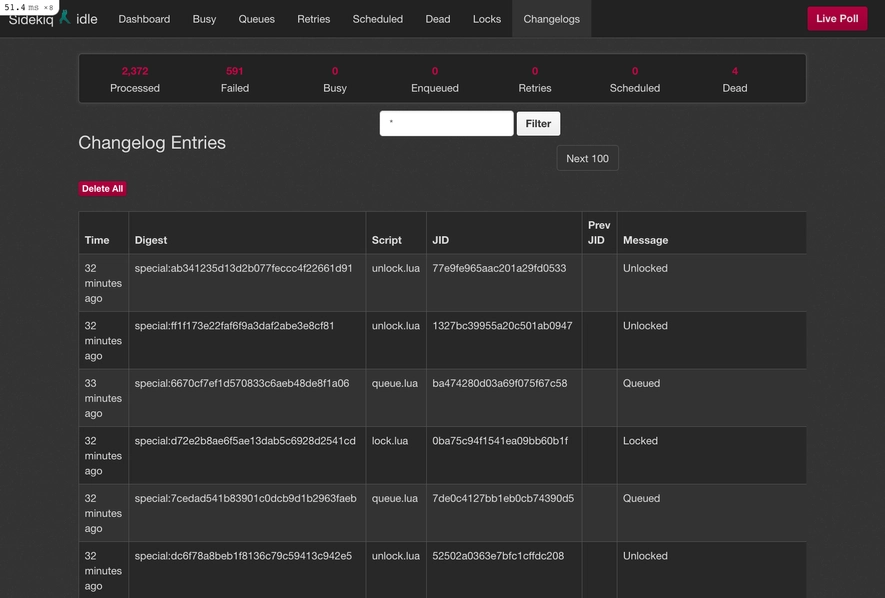
注意我们有两个新的页面,"锁 "和 "更新日志"。很酷的功能。
你可以在示例项目中尝试这一切,那里的gem已经安装并准备就绪。
为什么是Lua?
首先,我不是这个gem的作者,所以我在这里只是假设一下。 我第一次看到这个gem时,我想知道:为什么要在Ruby的gem中使用Lua?一开始可能看起来很奇怪,但Redis支持运行Lua脚本。我猜测该 gem 的作者有这样的想法,想在 Lua 中做更灵活的逻辑。
如果你看一下gem repo 中的 Lua 文件,它们并不复杂。所有的Lua脚本都是后来从这里的Ruby代码中调用的SidekiqUniqueJobs::Script::Caller 。请看一下源代码,阅读和弄清事情的工作原理是很有趣的。
备选宝石
如果你广泛使用ActiveJob ,你可以试试这里的 active-job-uniqueness gem。想法是类似的,但它使用Redlock来锁定Redis中的项目,而不是自定义Lua脚本。
为了有一个独特的工作使用这个宝石,你可以想象一个像这样的工作:
class BookSalesJob < ActiveJob::Base
unique :until_executed
def perform
...
end
end
语法不那么冗长,但与sidekiq-unique-jobs gem非常相似。如果你高度依赖ActiveJob ,它可能解决你的问题。
最后的思考
我希望你在如何处理你的应用程序中的重复工作方面获得一些知识。我在研究和玩弄不同的解决方案方面肯定很有乐趣。如果你最终没有找到你想要的东西,我希望其中的一些例子能启发你创造你自己的东西。
这里是包含所有代码片段的项目实例。
我们在下一节课上见,谢谢。
