

如果你不喜欢阅读(2020年2月 - Indy.rb Meetup)。
在每一个非琐碎的应用中,你都要做一些就是很慢的事情。你需要把一个大的数据集导出到CSV文件。一个分析员需要一个复杂的Excel报告。或者你必须连接到一个外部的API并处理一大堆数据。
那么,你怎么知道什么时候该使用后台作业了?
如果你尝试在普通的Rails控制器动作中构建这类报告,你会看到这些症状。
- 请求超时:一旦响应时间开始爬升到10秒以上,你就会有超时的风险。你可能有一个报告很慢,但只是勉强完成,但你知道它的规模与数据量成线性关系,很快就会中断。像Heroku这样的平台会在30秒后杀死请求,与此同时,你的整个应用程序会变慢,因为工作者/ynos会被长时间运行的动作所束缚。
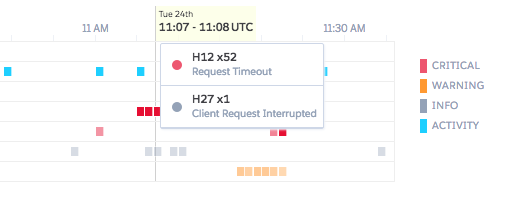
- 内存峰值:最直接的文件导出实现在向用户提供文件之前在内存中生成一个文件。对于小文件来说,这很好;但如果你在内存中创建100多MB的文件,你的内存使用量会急剧上升和下降。如果甚至有几个用户同时进行导出,你就会触及你的资源上限,看到失败的请求和Heroku "R14 - 内存配额超标 "的错误。
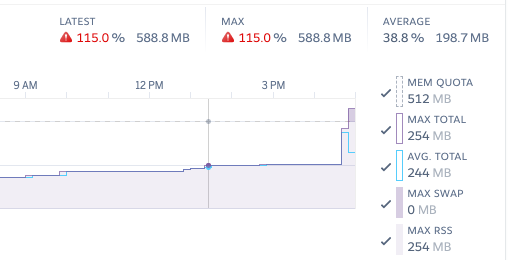
- 糟糕的用户体验:即使你的服务器经受住了缓慢行动的额外负载,用户也可能没有那么多耐心。浏览器标签中永远没有尽头的加载指示器,或者更糟的是,20秒内没有任何事情发生,这不是一个好的体验。你可以抛出一个 "加载中...... "的旋转器,但我们能做得更好吗?
第一步是通过优化查询或修复任何明显的性能问题来争取一些呼吸空间。花上一个小时查看Speedshop Rails性能博客,看看是否有低垂的水果。
但一旦你开始看到这类问题,就该为后台工作建立基础设施了。
选择你的工具
添加第一个后台作业总是最难的。你已经有了沮丧的用户或愤怒的客户(用商业术语来说,这叫急性需求!),但你不知道你的长期需求是什么,只知道这个第一个用例。
在Rails中设置后台作业时,有两个最初的决定要做。
活跃工作或不活跃工作?
早在Rails 4.2中,Active Job就作为后台作业处理的通用抽象而发布。跟随其他RailsActiveX gems的脚步,Active Job是一个API,允许你将后台作业添加到队列中,然后使用Sidekiq、Delayed Job或Resque等工具来 "工作 "或处理这些作业。
Active Job定义了一套核心功能,应该可以很好地服务于大多数应用程序:你可以(很明显)创建作业,但也可以将作业放入单独的队列(优先级),安排作业在未来运行,并处理异常情况。这些都是你想要的后台作业的基本基元。
就像所有的Rails抽象一样,需要权衡利弊:标准接口允许更深入的框架集成,但必须使用最低的共同标准。
使用Active Job为你提供了一个更简单的开发环境。在开发中,你可以将队列适配器设置为:async ,用进程中的线程池运行作业。在本地运行bin/rails server ,作业就会被运行,而不需要运行单独的worker命令或使用类似foreman 的工具。
缺点是,如果你需要更强大的功能或想利用适配器的特定模式,你就会逆流而上。
你当然可以将你的应用程序设置为直接使用Sidekiq,而完全放弃Active Job。如果你需要使用高级功能(特殊重试策略、批处理、推送大量作业、速率限制等),使用后台处理器 "更接近金属 "是有好处的(而且有些功能可能根本无法与Active Job一起工作)。
根据Sidekiq的wiki,跳过Active Job也可以给你带来非直接的性能提升。
我建议一开始就使用Active Job;当你对你的长期需求有清晰的认识时,你可以随时移植。如果你遇到了限制或不能使其正常工作,你可以证明花更多的时间来调整和离开标准的Rails路径。
延迟作业还是Sidekiq?
第二个考虑因素是在生产中使用哪种队列适配器。除非你有一些非常特殊的需求,否则只有两个选择。Sidekiq或Delayed Job。这两个都是成熟的库,有最好的教程、文章和扩展。
Sidekiq是目前许多开发者的 "默认 "选项。它的扩展性很好,而且Sidekiq Pro/Enterprise选项对于项目的持续稳定和改进非常令人放心。Mike Perham(和其他贡献者)在Sidekiq的文档和维基上做得非常好。
如果你打算每天有成千上万的作业在运行,Sidekiq是一个不二选择。
Sidekiq的一个小缺点是,你必须依赖Redis来存储作业队列和元数据。如果你的基础设施中已经有了Redis(很可能是用于缓存),那么这就是一个没有意义的问题。大多数Rails开发者对他们的技术栈中有Redis感到满意,你可以在所有主要的云平台上在5分钟内启动托管实例。

Delayed Job是一个较老的、不那么闪亮的选择。虽然近年来它已经失去了社区的青睐,但它仍然是一个非常坚实的宝石。延迟作业最初是从Shopify的内部代码库中提取出来的,所以它已经经过了大规模的战斗测试。
Delayed Job与ActiveRecord一起工作,并使用你的PostgresQL数据库来存储工作。不需要额外的基础设施或Heroku附加组件。它真的很容易设置,而且少了一个移动部分。
如果你想偷看底层表进行调试或查看工具的工作情况,共享你的应用程序的数据库也很方便;它只是另一个表而已。
因为Delayed Job是单线程的(与Sidekiq的多线程模式相比),所以不建议每天处理10万个作业。这就是说,许多应用程序永远不会达到这个规模!延迟作业可以让你在没有额外基础设施的情况下走得很远。
当你感觉到扩展的痛苦时,你可能已经准备好了更大的工程投资--或者有一整个团队来调整和管理后台处理。
如果你有一个(实际的)大型网络服务(Shopify/GitHub/Basecamp-esque负载),有一系列 "最先进 "的模式和工具可以考虑(见Kir Shatrov从Shopify的战壕中写下的伟大文章),但我们其他人将最好的选择是一个无聊的。
归根结底,决定权在于你是否已经将Redis作为你的基础设施的一部分。这两个库都很好用,而且设置时间相似。
Sidekiq可以让你扩大规模,但要承担一点基础设施的费用;如果你想以每秒5000个作业的速度运行,Delayed Job就会倒下,但这不应该是中小型应用的首要问题。两种选择都不会出错。
在最近的一个项目中,由于团队规模小,作业量小(每天10s-100s),我们选择了延迟作业,因为它简单,移动的部件少。这很好。
背景作业的基本原理
在最高层次上,使用后台作业意味着将你的慢速代码移到一个Job 类中。与其在控制器中运行慢速代码,你还不如对作业进行排队,并将它所需的任何输入数据传递给它。
Active Job指南很好地解释了一般的概念,但有一些最佳实践,如果你遵循它们,会给你带来巨大的好处。
为避免作业带来的麻烦,你可以做的前三件事是:使用全局 ID,检查预设条件,以及拆分大型作业。
全局ID
你可能会看到其他工具的建议与这个提示完全相反,但在Rails中,你可以将ActiveRecord 模型作为参数传递给你的作业,它们就能正常工作。在引擎盖下,Rails 使用一个叫做 "全局 ID "的概念来序列化对模型对象的引用。如果你有一个带有id=5 的Company 模型,Rails 将为该模型生成一个应用范围内的唯一 ID(在本例中:gid://YourApp/Company/5 )。
不要通过 ID 手动查询模型:
class CloseListingJob < ApplicationJob
def perform(user_id, listing_id)
listing = Listing.find(listing_id)
listing.archive!
listing.notify_followers
user = User.find(user_id)
listing.notify(user)
end
end
在其他情况下,将对象传递给后台作业被认为是一种反模式,因为当你以后去运行作业时,你可能会序列化一个 "过时 "的对象。Rails会在你的作业运行前获得一个新的对象副本,所以你不必担心这个问题。
如果你曾处理过来自序列化/marshaled对象的奇怪行为*(不寒而栗*),你可能有战斗的伤痕,但你不需要再传递ID和手动重新获取数据了。
这样做使用全局ID来自动处理常见的序列化:
class CloseListingJob < ApplicationJob
def perform(user, listing)
listing.archive!
listing.notify_followers
listing.notify(user)
end
end
检查先决条件
检查作业(尤其是破坏性动作)的前置条件有两个原因:世界可能已经改变,以及双重排队的问题。
既然你已经把一个任务卸载到了后台,那就确认从我们排队的时候到代码实际运行的时候,没有什么重大变化。
想象一下这样的情况:你准备给客户发送一封逾期发票的电子邮件,需要几分钟的时间来处理这个任务,而在这段时间里,客户正好提交了他们的逾期付款。这项工作已经在队列中了,如果不防备发票被支付,你就会发送一封混乱的电子邮件出去。
另一个问题是当同一作业的多个副本被排队时。也许两个用户触发了同一个作业,也许你的代码中有一个错误,或者当你的测功机重新启动时,一个作业被运行了两次。对此有一个花哨的计算机科学术语:同位素。确保同一作业可以运行多次而不产生负面的副作用。
不要盲目地发射破坏性的行动:
class NotifyLateInvoiceJob < ApplicationJob
def perform(user, invoice)
# Fire off a scary email
InvoiceMailer.with(user: user, invoice: invoice).late_reminder_email
end
end
有一些插件和工具可以尝试强制执行idempotence(见sidekiq-unique-jobs ),但一般来说,在你自己的应用代码中采取预防措施。
做到这一点确保当作业运行时,导致你排队的条件是真的:
class NotifyLateInvoiceJob < ApplicationJob
def perform(user, invoice)
# Confirm that nothing has changed since the job was scheduled
if invoice.late? && !invoice.notified?
InvoiceMailer.with(user: user, invoice: invoice).late_reminder_email
# Track state for things that should only happen once
invoice.update(notified: true)
end
end
end
分割大型作业
除了将工作从 "主线程 "上移开之外,后台队列还允许你将工作拆分和并行化。但是,仅仅把一些东西放在后台作业中并不能使其运行得更快。
宁愿选择许多小工作,也不要选择一个大工作--这有助于提高性能(让多个工人完成任务),也有助于在工作中断的情况下(动力装置重启、意外错误、太阳耀斑导致的随机比特翻转)。
不要在一个作业中运行过慢的循环:
class ComputeCompanyMetricsJob < ApplicationJob
def perform(company)
company.employees.each do |employee|
# A bunch of slow work
employee.compute_hours
employee.compute_productivity
employee.compute_usage
end
end
end
你可能听说过这个概念,叫做"fanning out":你把一个可能有100个循环迭代的作业,分成100个小作业。
如果你有10个工人,你可以以10倍的速度完成工作(忽略开销),如果第62次循环迭代失败,你可以重试那一小段工作(而不是重新开始整个工作)。
做从另一个作业中排队等候较小的作业:
class ComputeCompanyMetricsJob < ApplicationJob
def perform(company)
company.employees.each do |employee|
# Fan-out with parallel jobs for each employee
ComputeEmployeeMetricsJob.perform_later(employee)
end
end
end
class ComputeEmployeeMetricsJob < ApplicationJob
def perform(employee)
employee.compute_hours
employee.compute_productivity
employee.compute_usage
end
end
不要太过分:不建议将每个循环的工作分解成子工作。有时候,这不值得额外的复杂性,或者你想把所有的工作都包在同一个事务中。
但是,如果你发现自己创建的作业是循环的,并且做了一两个以上的查询,请考虑将作业分割开来。
将数据返回给用户
大多数关于后台作业的指南都有一个错误的假设,即所有的工作都是 "即用即走"。当然,对于发送重置密码的电子邮件来说,可以将作业排队并完成请求。它不太可能失败,只需要几秒钟,而且你不需要作业的结果来通知用户去检查他们的收件箱。
但是,如果生成一个20,000行的Excel文件或一个需要5分钟才能完成的后台进程呢?我们经常需要一种方法来报告进度,并在工作完成后发回信息。
最根本的问题是,当你把工作转移到后台作业时,代码的执行并没有停止,你需要一种方法来 "连接 "回导致作业被创建的用户。这是在一个单一的请求-响应的生命周期之外,所以你不能依靠正常的Rails控制器。
有两种方法非常适用于绝大多数作业:稍后发送电子邮件和轮询+进度。
稍后发送电子邮件
转达作业已完成的一种方式是发送电子邮件。它的好处是很简单。你运行一个任务,然后关闭一个ActionMailer ,其中包含任何相关的状态("你的联系人现在已经被导入!"或 "同步日历事件失败了。联系支持")或链接回你的应用程序("现在查看你的年度税务文件")。
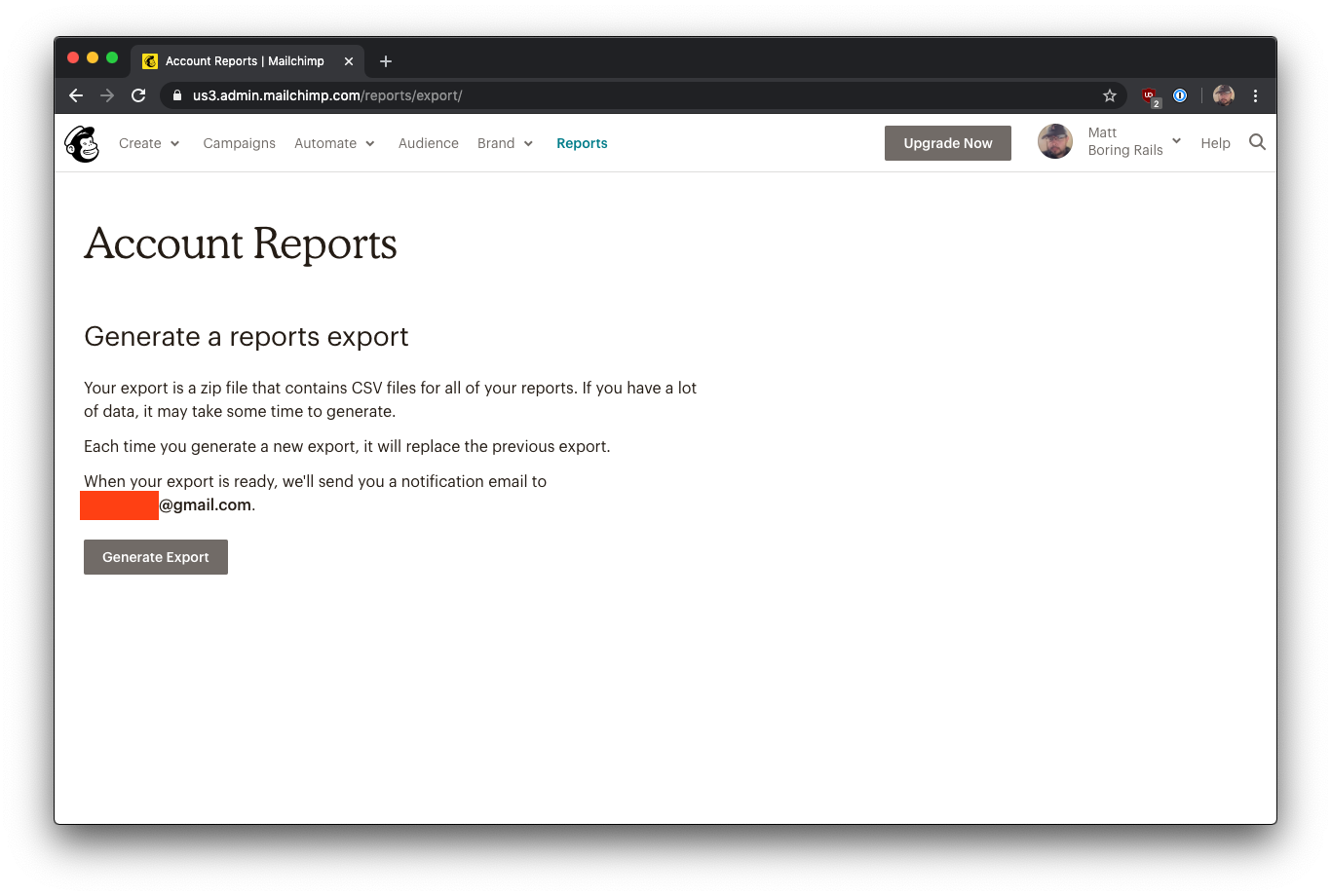
你可以在Mailchimp看到这种模式的一个例子:
对于可能需要很长时间的报告(例如,导出你曾经发送过的每封电子邮件的活动统计),你首先要点击 "生成报告"
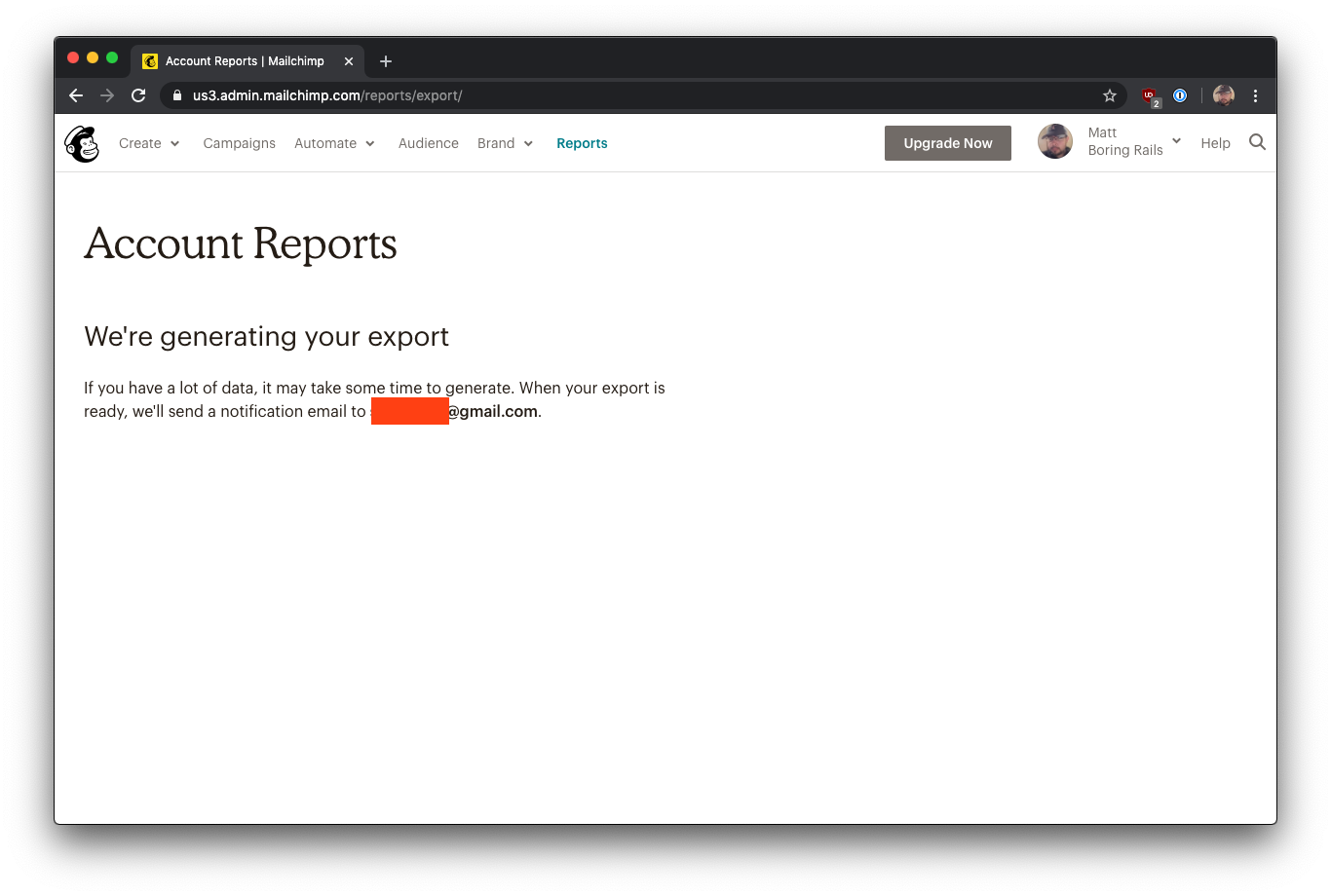
Mailchimp通知你,对于大型账户,可能需要几分钟的时间,并希望在数据导出完成后收到一封邮件:
一段时间后,你会收到一封来自Mailchimp的电子邮件,里面有下载报告的链接:
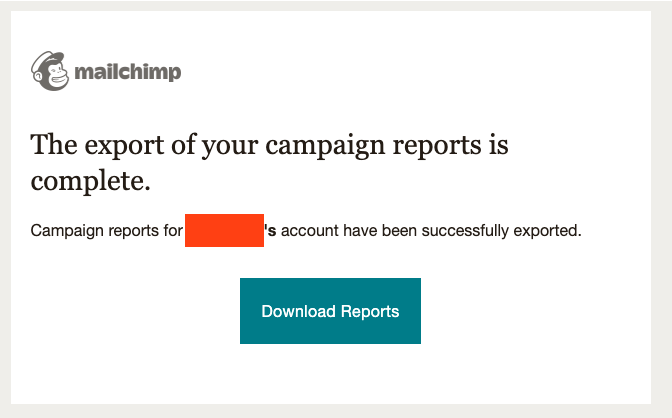
你会被带回Mailchimp应用程序,可以下载报告的压缩包:
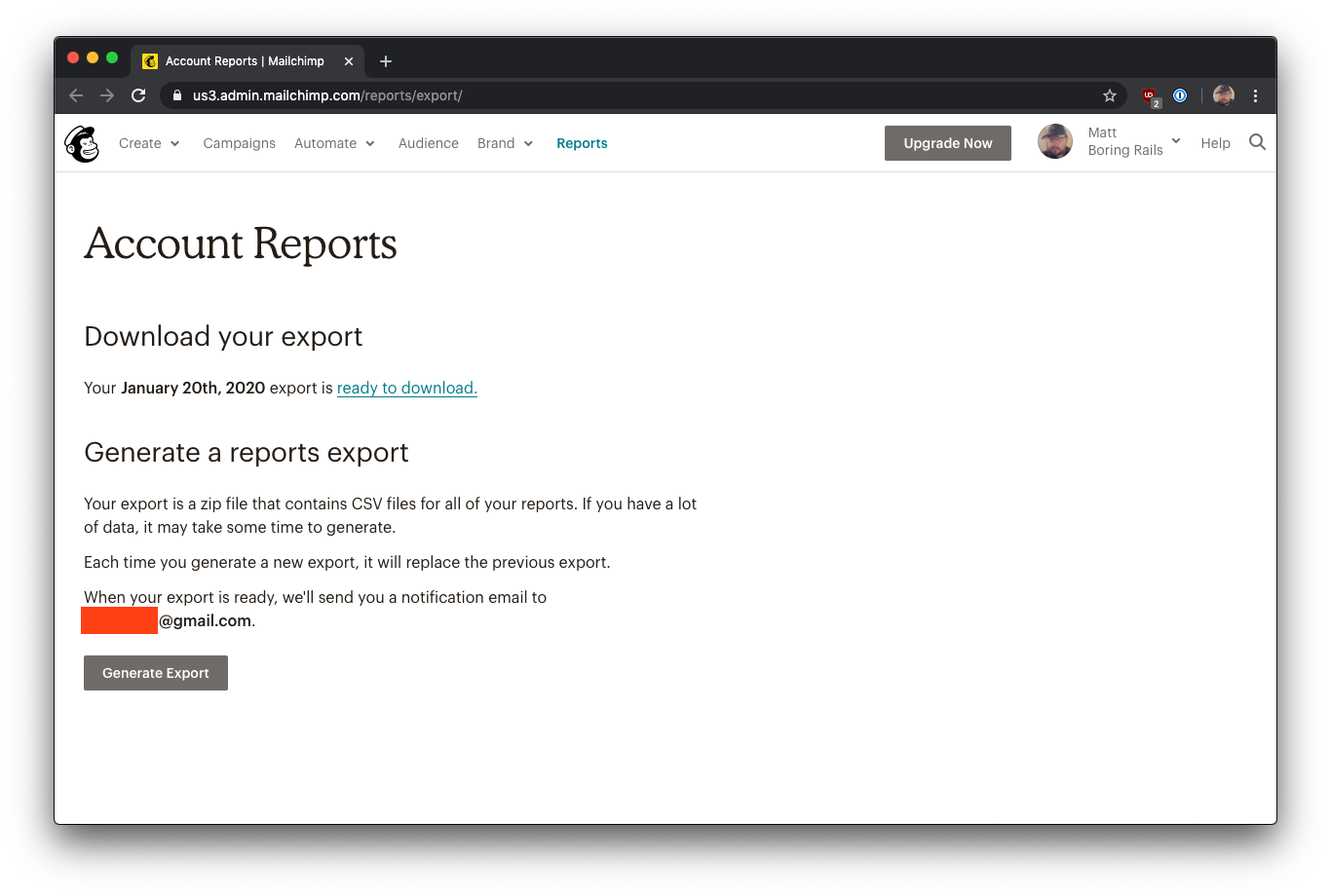
Mailchimp选择在你的账户中存储最近的文件导出,以备你以后再次下载相同的报告。如果你生成另一个大报告,它将覆盖该文件。
对于你自己的应用,你可以决定这种保存报告的方法是否有意义。你可以选择存储所有文件的完整历史记录,保留最近的三个文件,或者其他完全不同的方法。
下面是实现这个工作流程的一些示例代码(具体细节需要根据你自己的应用来调整):
class ReportsController < ApplicationController
def generate_campaign_export
# Enqueue the job
CampaignExportJob.perform_later(Current.user)
# Display a message telling user to await an email
render :check_inbox
end
end
class CampaignExportJob < ApplicationJob
def perform(user)
# Build the big, slow report into a zip file
zip = ZipFile.new
user.campaigns.each do |campaign|
zip.add_file(CsvReport.generate(campaign))
end
# Store the report on a file system for downloading
file_key = AwsService.upload_s3(zip, user)
# Record the location of the file
user.update(most_recent_report: file_key)
# Notify the user that the download is ready
ReportMailer.campaign_export(user).deliver_later
end
end
<!-- application/views/report_mailer/campaign_export.html.erb -->
Hi <%= @user.name %>,
The export of your campaign report is complete. You can download it now.
<%= link_to "Download Report", download_campaign_export_path %>
class ReportsController < ApplicationController
...
def download_campaign_export
# Create a 'safe link' to download (e.g. signed, expiring, etc)
download_url = AwsService.download_link(User.current.most_recent_report)
# Trigger a download in the browser
redirect_to(download_url)
end
end
轮询+进度
对于基本的报告,用电子邮件发送就足够了,但有时用户需要更频繁的状态更新,了解后台进程的情况。
另一种模式是将轮询(通过AJAX调用定期检查工作)与进度报告相结合。这种方法的一个好处是,它具有超强的扩展性。你可以用各种方式实现进度报告:数字进度条、单一的 "状态 "信息,甚至是详细的进度日志。
这种模式非常适用于用户生成的大型报告,以及用户可能想要监控的长期运行的 "系统任务"。
你可以在Netlify的构建仪表板中看到这种模式的例子:
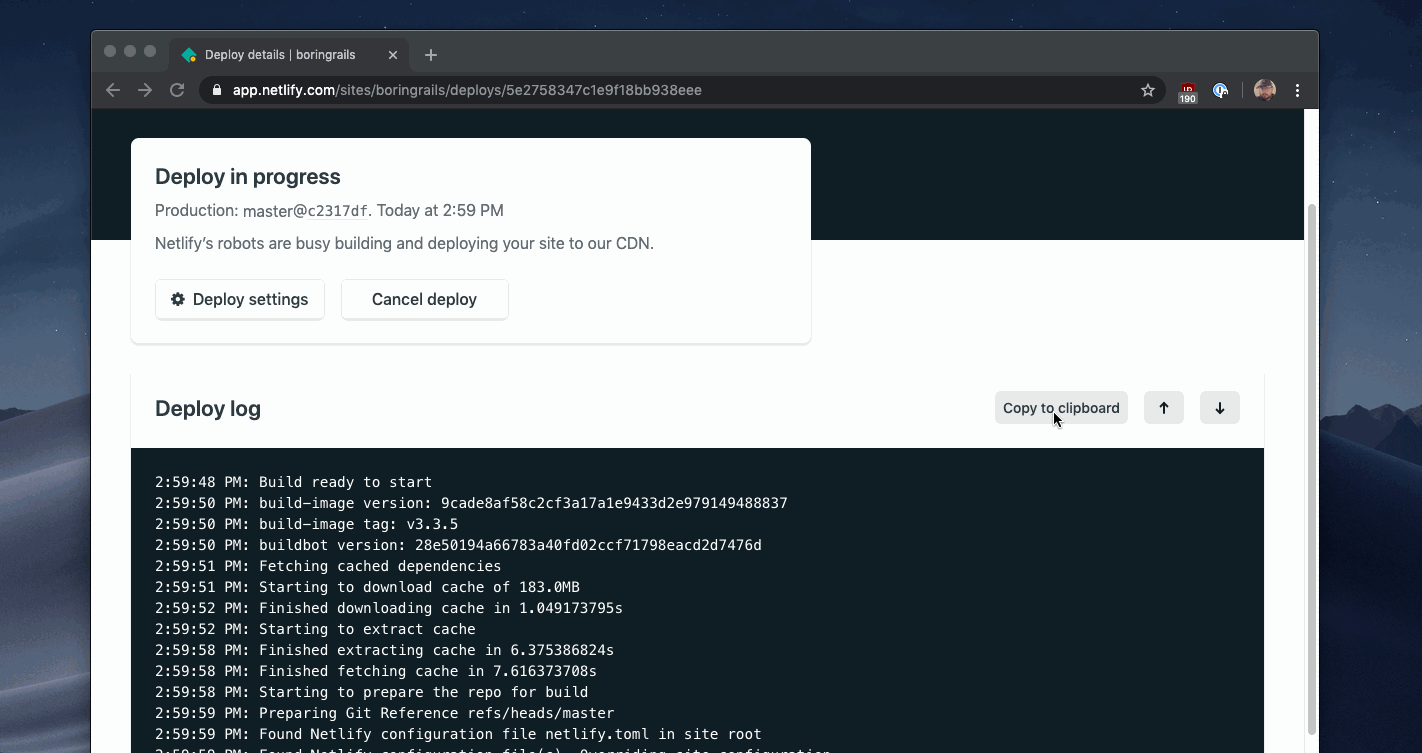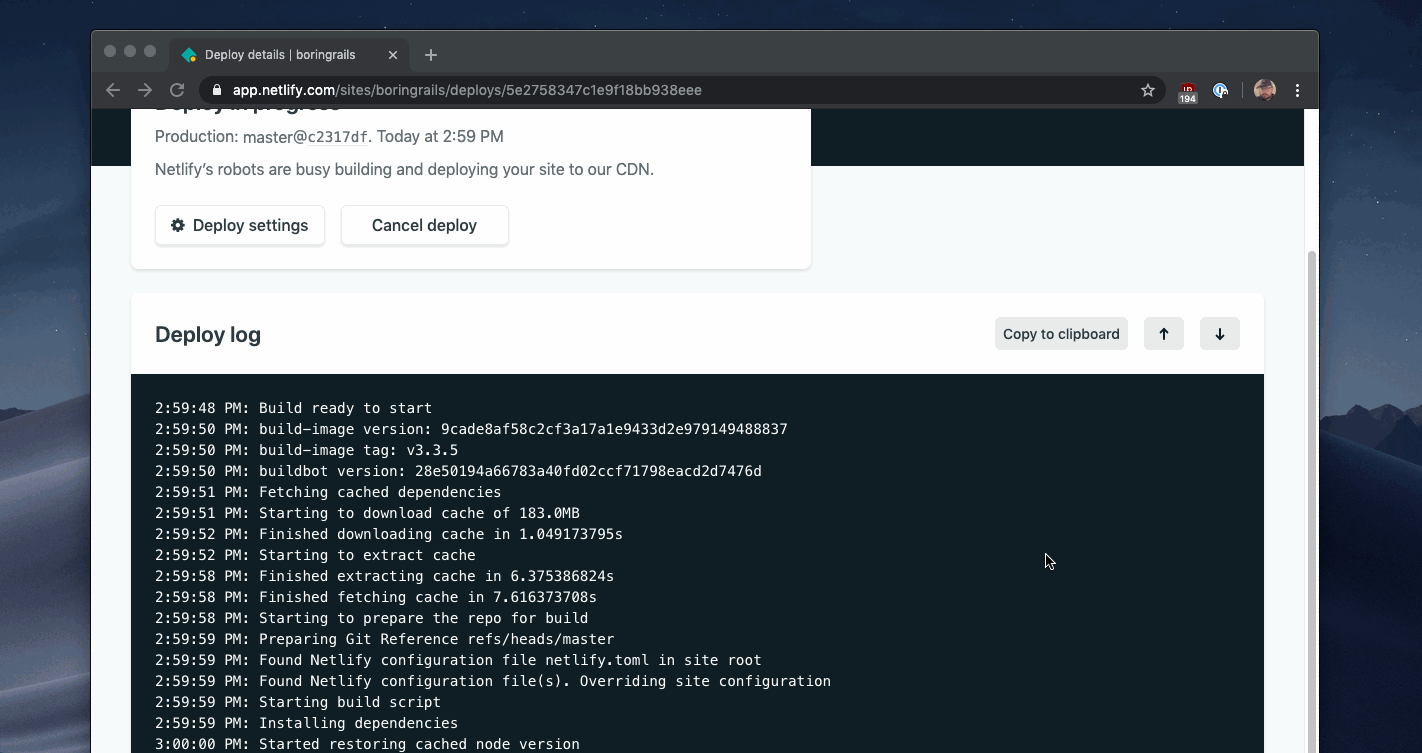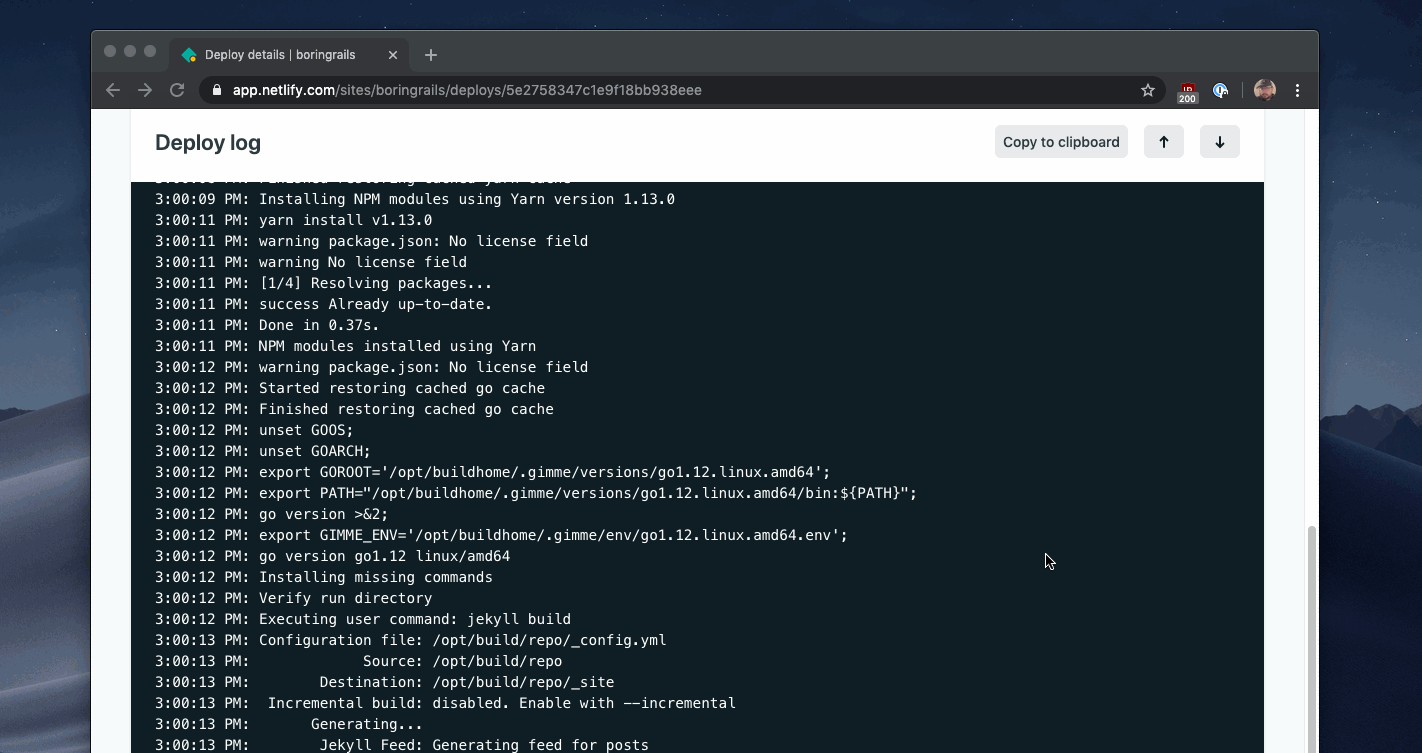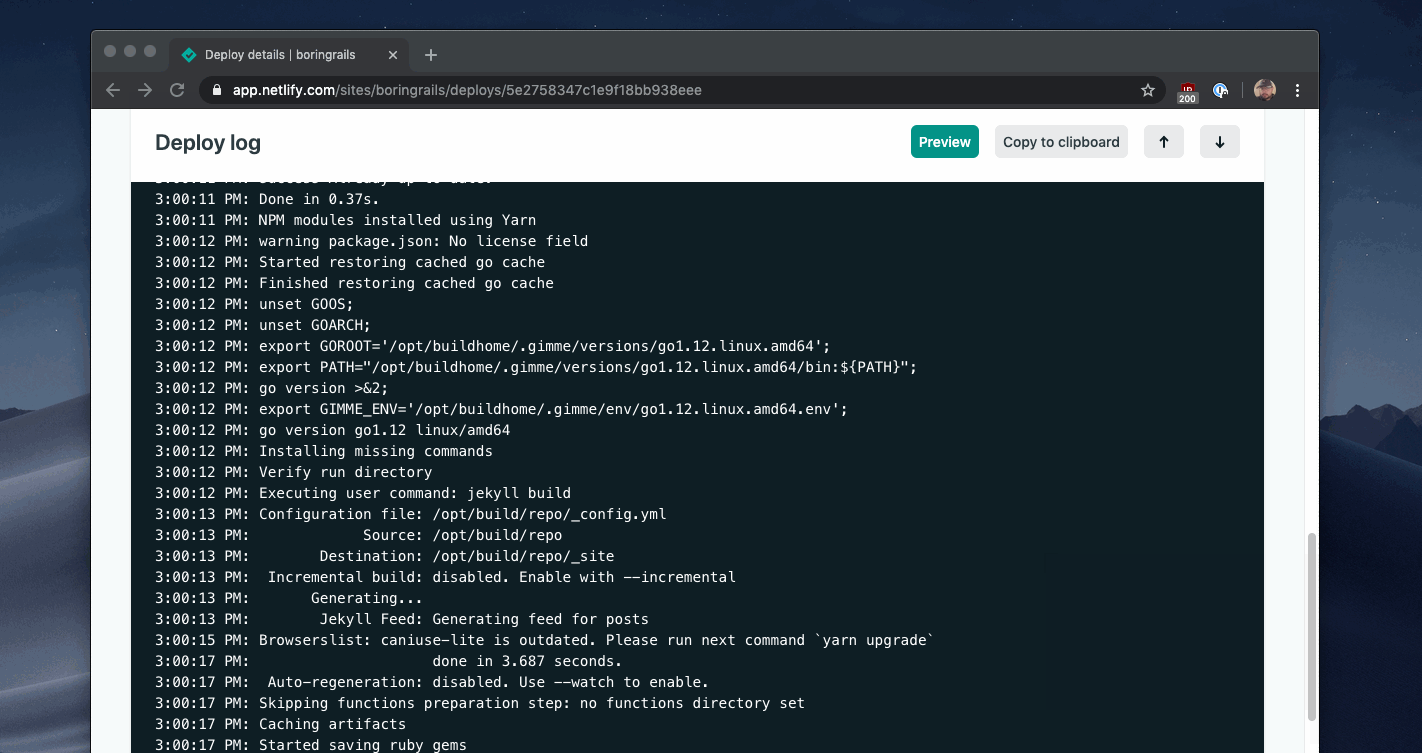
Heroku使用同样的模式来显示部署软件新版本的长达数分钟的过程的进度:
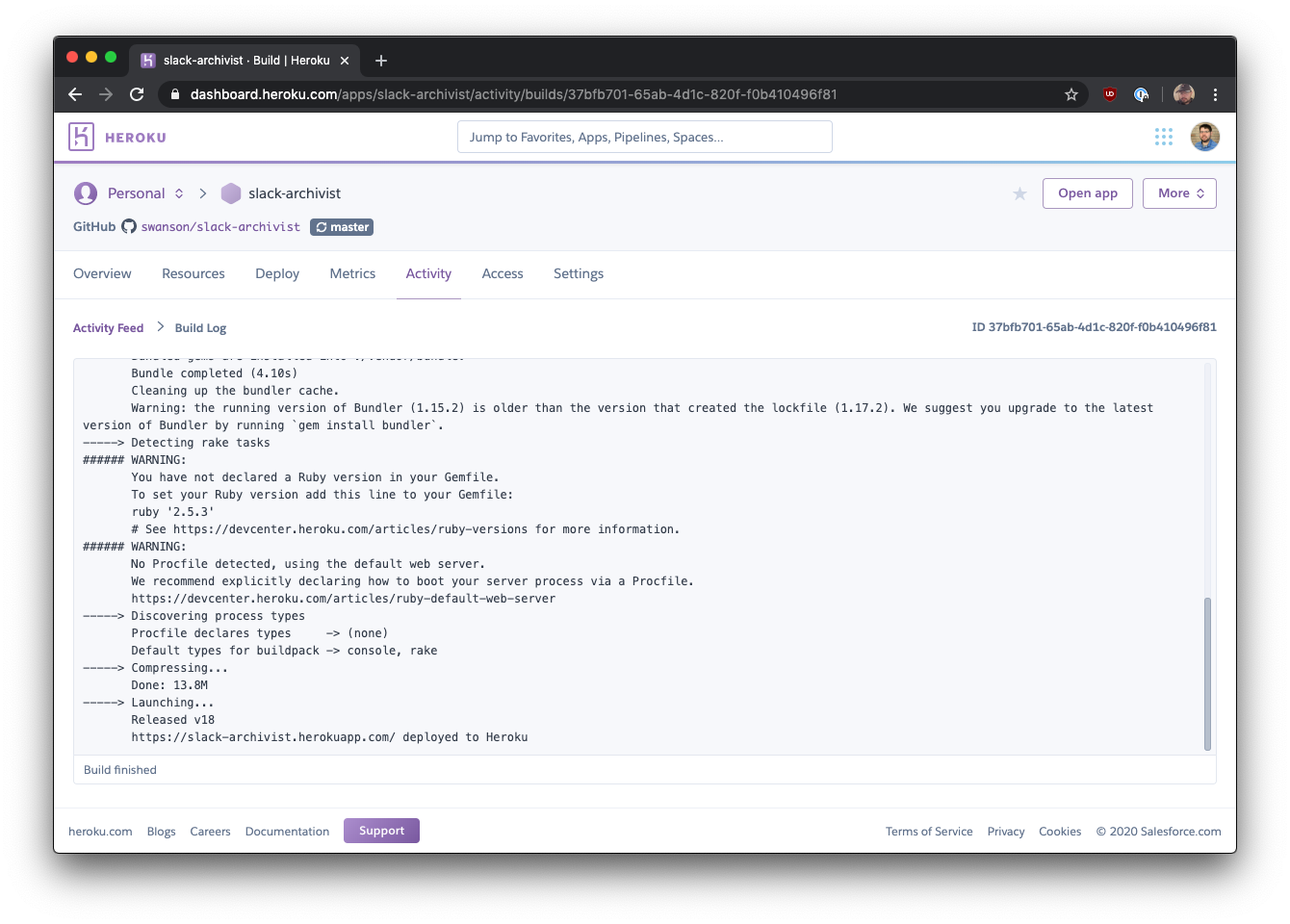
这些UI看起来很复杂,但其核心是一个重复的AJAX调用来检查工作状态和一个文本块。你可以在你的应用程序中为多个不同的报告重复使用这种模式,并根据你的需要使输出变得详细。
你可以把这种模式看作是在网页中建立一个CLI界面。因为主要的UI元素是文本,所以它真的很容易建立并根据需要改变。
这里有一些粗略的示例代码来实现这个工作流程。这个例子使用了一个单独的数据库模型来存储传递给工作的 "工作状态",以及一个Stimulus控制器来处理客户端的轮询/更新。
具体细节需要根据你自己的应用程序进行调整。
class MetricsController < ApplicationController
def export_company_stats
company = Company.find(params[:company_id])
status = JobStatus.create!(name: "Company Stats - #{company.name}")
CompanyStatsJob.perform_later(company, status)
redirect_to status, notice: "Generating statistics..."
end
end
# == Schema Information
#
# Table name: job_statuses
#
# id :bigint not null, primary key
# completed :boolean default(FALSE), not null
# download_key :string
# error :boolean default(FALSE), not null
# error_message :text
# log :text default("")
# name :string not null
# created_at :datetime not null
# updated_at :datetime not null
#
class JobStatus < ApplicationRecord
def add_progress!(message)
update!(
log: log << "\n==> " << message
)
end
def mark_completed!(key)
update!(
completed: true,
download_key: key,
log: log << "\n\n---\n\n" << "Report complete!"
)
end
def mark_failed!(error_message)
update!(error: true, error_message: error_message)
end
def log_error!(error)
update!(
log: log << "\n\n---\n\nERROR: " << error.to_s
)
end
end
class CompanyStatsJob < ApplicationJob
def perform(company, status)
status.add_progress!("Generating stats for #{company.name}...")
report = CompanyStatsReport.new(company)
# Do some complicated calculations
status.add_progress!("Computing financial data...")
report.compute_financial_data!
status.add_progress!("Computing employee data...")
report.compute_employee_data!
status.add_progress!("Computing product data...")
report.compute_product_data!
# Store the report on a file system for downloading
file_key = AwsService.upload_s3(report.as_xlsx)
status.add_progress!("Report completed.")
status.mark_completed!(file_key)
rescue StandardError => e
status.mark_failed!(e.to_s)
status.log_error!(e)
end
end
class JobStatusController < ApplicationController
def show
@status = JobStatus.find(params[:id])
# Return a basic HTML page and a JSON version for polling
respond_to do |format|
format.html
format.json { render json: @status }
end
end
end
<!-- application/views/job_status/show.html.erb -->
<h1>
<%= @status.name %>
</h1>
<div
data-controller="job-status"
data-job-status-url="<%= job_status_path(@status, format: :json) %>"
>
<div data-target="job-status.log">
<%= @status.log %>
</div>
<%= link_to "Download", "#", class: "btn hidden", data: { target: "job-status.download" } %>
</div>
// src/controllers/job_status_controller.js
import { Controller } from "stimulus";
export default class extends Controller {
static targets = ["log", "download"];
connect() {
// Start polling at 1 second interval
this.timer = setInterval(() => {
this.refresh();
}, 1000);
}
refresh() {
fetch(this.data.get("url"))
.then((blob) => blob.json())
.then((status) => {
// Update log and auto-scroll to the bottom
this.logTarget.innerText = status.log;
this.logTarget.scrollTop = this.logTarget.scrollHeight;
if (status.error) {
this.stopRefresh();
// Add additional error handling as needed
} else if (status.completed) {
this.stopRefresh();
// Show a download button, or take some other action
this.downloadTarget.href = `/download/${status.download_key}`;
this.downloadTarget.classList.remove("hidden");
}
});
}
stopRefresh() {
if (this.timer) {
clearInterval(this.timer);
}
}
disconnect() {
// Stop the timer when we teardown the component
this.stopRefresh();
}
}
另外:如果你想要更多的功能或不同的API,你可以使用sidekiq-status这样的工具来跟踪进度。你不应该做的一件事是尝试直接向底层的jobs 表添加额外的状态信息,因为大多数处理器会在作业被处理后清除记录(让你无法查询状态)。
混合、匹配和修改
这两种方法应该是解决这个问题的可靠方法,但请自由组合或修改它们以满足你自己的需要。
也许你想添加一个文件已被下载的标志,如果用户在等待文件完成时关闭了标签,那么以后再发送一封邮件。也许你想把用户重定向到应用程序中的一个新页面,而不是下载一个文件。也许你只是需要一个加载旋钮或基本的进度条。
提示:后台处理是一个与语言无关的概念,所以不要羞于从其他开发生态系统中学习。
把这些模式看作是很好的构件,然后根据需要增加额外的复杂性。你可能想在几天后清理job_statuses 表,或添加更强大的认证,或使用工作状态作为缓存结果的方式。这由你决定。
这段代码应该作为一个概念性的指导原则,并且随着你的需求的变化,应该很容易扩展和增长。
高级技术 小心谨慎地进行
涵盖更多的高级技术已经超出了本文的范围,但如果你发现自己需要更强大的东西,下一步将是实现某种ActionCable或Web-socket方法,也许与应用内或推送通知相结合。大多数应用程序将永远不需要走到这一步。
如果你有容易预先计算和存储的报告--例如,每月的账户报表--你可以从 "按需 "报告生成切换到cron/计划生成。如果报告的内容在某个日期之后不太可能改变,那么它就是预计算的好候选者。
收拾好它
你会到达一个点,你不能通过优化查询来解决每一个性能问题。长时间运行的报告或大文件输出应该被移到后台作业中,以便在单个HTTP请求的生命周期之外进行处理。
Rails中的Active Job框架为排队工作提供了一个坚实的、标准化的接口。有一些经过实战检验的、社区支持的工具--Sidekiq和Delayed Job--可以在一天内完成数以千计的工作而不出现任何问题。
遵循这些基本的(但强大的!)模式来显示进度,并在处理完后将数据送回给用户。要让你的第一个后台作业启动和运行,需要适度的前期投资,但随着你的应用程序的增长,它将立即得到回报。
