

[
6月29日
-
6分钟阅读
[
拯救
在Python中使用模式优先的方法构建GraphQL服务器
轻松处理CRUD操作
模式优先的方法是什么呢?我们首先为我们的GraphQL服务定义模式,然后我们通过匹配我们定义的模式中的定义来实现代码。
我们将为此使用Ariadne 库。
Ariadne是一个Python库,用于使用模式优先的方法实现GraphQL服务器。-Ariadne
项目概述
我们将建立GraphQL服务器,处理图书商店中图书的CRUD操作。
简单地说,我们将把书的信息存储在我们的数据库中。为了使这个项目更简单,我没有使用任何类型的数据库,只是使用了一个内存存储,并将重点放在GraphQL部分。
服务器操作
- 添加书籍
- 通过ID获取书籍
- 按流派列出书籍
- 列出所有的书
- 更新图书
- 删除书籍
建立GraphQL服务器
库的安装
我们高度依赖Ariadne 库,所以我们必须安装它。
pip install ariadne
我们必须使我们的GraphQL服务器成为HTTP服务器,它将接收HTTP请求,执行GraphQL查询,并返回响应。
为此,我们可以使用一个ASGI*(Asynchronous Server Gateway Interface*)服务器,如uvicorn。
pip install uvicorn
定义我们的模式
我邀请你以你自己的方式和要求来定义模式和实现代码。这里我们将看到我定义模式的方式。
我计划有一些GraphQL对象类型,可以在我们的书籍store ,持有一些关于Books 的信息。
现在我有2个对象类型和1个枚举类型来描述一本书。
**Book** type有以下几个字段。
title- 字符串类型和不可归零的book_id- ID类型genre- 枚举类型author- 类型的数组和不可归零的Author
Author 类型。
- name - 字符串类型和不可置空的
- mail - 字符串类型
**BookGenre** 枚举类型。
- 有两个值 (
FICTION,NONFICTION)
上述类型是处理Books 信息的基本类型。
现在我们继续前进,为我们的GraphQL服务定义入口点。
查询类型
我有上面的查询类型,有3个字段。
book- 通过在参数中提供 ,获得书的详细信息book_idbooks- 获得可用书籍的列表getbooks- 获取所请求的流派的书籍列表。 参数是一个可选项,它的默认值是 。getgenreFICTION
type GetBookResult{ isexists: Boolean! book: Book}
该 **GetBookResult** 类型有2个字段。
isexists- 布尔类型,不可为空,告诉人们该书的信息是否存在于给定的book_id- 书籍- 书籍类型
变异类型
变异类型有3个字段
add_book- 通过提供输入,在我们的图书商店创建一个图书资源,响应是该请求的状态。update_book- 更新现有的图书信息,响应是该请求的状态。delete_book- 删除具有给定图书ID的图书,并返回该操作的状态。
上述类型被用在 **add_book** 突变类型的字段。
UpdateInput 和PutStatus 类型被用在 **update_book** Mutation 类型的字段。
type DeleteStatus{ iserror: Boolean! description: String}
DeleteStatus type被用于 类型的 字段中。Mutation delete_book
我们的模式定义到此结束。现在开始实施代码。
GraphQL服务器的实现
内存存储
正如我前面提到的,我将使用一个内存数据存储(简单地说就是一个变量)来存储书的信息。
BOOK_STORE = [ { "title": "Book 1", "book_id": 1, "genre": "FICTION", "authors": [{"name": "Logesh", "mail": "logesh@domain.com"}] },]
这里我有一个初始的模拟数据。
模板代码
我们可以通过两种方式加载我们的模式。
- 通过在一个变量中定义我们的模式
- 通过在一个单独的
.graphql文件中定义我们的模式
例如,在第一种情况下。
from ariadne import QueryType, gql, make_executable_schema, MutationType
对于第二种情况。
from ariadne import QueryType, make_executable_schema, MutationType, load_schema_from_path
在上面的代码中,我们可以看到,我已经从外部文件中加载了我们的模式。
辅助函数
我写了一些辅助函数,如从BOOK_STORE 中获取书籍信息。
上述函数用于从BOOK_STORE (我们的数据库)变量中获取给定ID的书。
这个函数用于检查给定ID的书是否存在。
这个简单的函数被用来创建一个唯一的ID,在创建新书时需要这个ID。
通过提供书的ID,从BOOK_STORE 变量中删除书。
这个函数用来获取具有给定体裁的书的列表。
解析器
现在我们准备实现我们的GraphQL服务器解析器。
对于 **book** 字段,我们有上述函数来解析查询,并返回我们在模式中的这个请求的响应类型中提到的带有键(字段)的字典。
上述解析器函数被用来解析查询字段--books 和getbooks 。
现在转到突变类型。
上述函数用于在我们的Book 商店中创建一个新书。
resolve_update_book 该函数用于更新现有的书。
这个函数用于通过提供书的ID来删除书。
现在我们已经完成了我们的解析器,现在开始为客户提供服务。
为客户提供服务
通过使用uvicorn ,我们将使我们的 GraphQL 服务器通过 HTTP 提供服务。
执行下面的命令来启动服务器。
uvicorn main:app# uvicorn <filename>:<GraphQL object>
在http://127.0.0.1:8000 上运行的Uvicorn
查询book
突变 add_book

查询书
Mutation update_book
查询书籍

查询getbooks

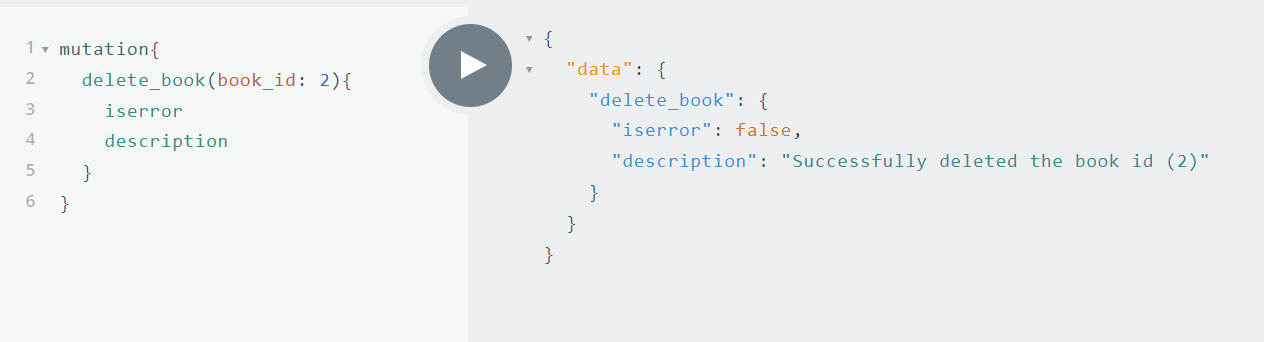
Mutation delete_book
查询书
我们也可以使用Postman作为GraphQL客户端。
在这篇文章中,我们已经看到了如何在Python中建立我们自己的GraphQL服务器(模式优先的方法)。
你可以在我的Github上找到这个项目。谢谢你的阅读。
