

获得我所有的视频课程,每月2次问答电话,每月的编码挑战,一个志同道合的开发者社区,以及定期的专家会议。
每个持久化框架中最重要的一些功能是使我们能够查询数据并以我们喜欢的格式检索数据。在最好的情况下,你可以轻松地定义和执行标准查询,但你也可以定义非常复杂的查询。Spring Data JDBC为你提供了这一切,我将在本文中向你展示如何使用这些功能。
如其名所示,Spring Data JDBC是Spring Data的一个模块,它遵循你可能已经从其他Spring Data模块中了解到的相同概念。你定义了一组被映射到数据库表的实体,并将它们分组为聚合体。对于每个聚合,你可以定义一个资源库。最好的方法是扩展Spring Data JDBC的标准存储库接口之一。这些接口为你提供了读取和写入实体和聚合的标准操作。对于这篇文章,我希望你对Spring Data中的存储库有所了解。如果你不熟悉,请看看我对Spring Data JPA的介绍中关于资源库的部分。它们的工作方式与Spring Data JDBC中的存储库相同。
默认情况下,Spring Data JDBC的存储库只能获取特定类型的所有实体,或者通过主键获取一个实体。如果你需要一个不同的查询,你需要自己定义它。你可以使用Spring Data流行的派生查询功能进行简单查询。而如果它变得更加复杂,你可以用*@Query*注解来注解存储库方法,并提供你自己的语句。在我们仔细研究这两个选项并讨论非实体投影之前,让我们快速看一下本文中使用的领域模型。
内容
- 1领域模型示例
- 2Spring Data JDBC中的派生查询
- 3Spring Data JDBC中的自定义查询
- 4Spring Data JDBC中的非实体/非聚合预测
- 5结论
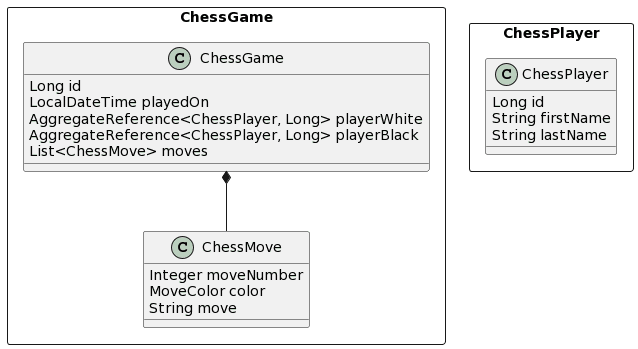
示例领域模型
在这篇文章的例子中,我们将使用的领域模型由两个聚合体组成。ChessPlayer 聚合体只由ChessPlayer 实体组成。ChessGame聚合体是独立于ChessPlayer 的,由ChessGame 和ChessMove实体类组成,它们之间有一对多的关联。ChessGame实体类还将2个外键引用映射到ChessPlayer集合。其中一个引用了下白棋的玩家,另一个引用了下黑棋的玩家。
Spring Data JDBC中的派生查询
与其他Spring Data模块类似,Spring Data JDBC可以根据存储库方法的名称生成一个查询语句。这被称为派生查询。派生查询是一种生成简单查询语句的好方法,它不需要JOIN子句,也不使用超过3个查询参数。
在这里你可以看到这种查询的几个典型例子。
public interface ChessGameRepository extends CrudRepository<ChessGame, Long> {
List<ChessGame> findByPlayedOn(LocalDateTime playedOn);
List<ChessGame> findByPlayedOnIsBefore(LocalDateTime playedOn);
int countByPlayedOn(LocalDateTime playedOn);
List<ChessGame> findByPlayerBlack(AggregateReference<ChessPlayer, Long> playerBlack);
List<ChessGame> findByPlayerBlack(ChessPlayer playerBlack);
}
Spring Data JDBC中的派生查询遵循与其他Spring Data模块中相同的原则。如果你的方法名称与以下模式之一相匹配,Spring Data JDBC会尝试生成一个查询语句。
- findBy(找到某个字符串)
- getBy(获取)。
- queryBy查询。
- existsBy(存在)。
- count<某个字符串>通过<where子句>。
Spring Data JDBC会解析*<where子句>*并将其映射到由存储库接口管理的实体类的属性。不支持与其他实体类的连接。
默认情况下,Spring Data JDBC为每个引用的属性生成一个相等的比较,并将其与具有相同名称的方法参数进行比较。你可以通过使用 "After"、"Greater Than"、"Like "和 "IsTrue "等关键字来定制比较结果。你可以在官方文档中找到所有支持的关键字的完整列表。你还可以使用关键字 "And "和 "Or "在你的WHERE子句声明中组合多个参数。
基于这些信息,Spring Data JDBC会生成一个SQL语句,并在你的业务代码中调用存储库方法时执行。
List<ChessGame> games = gameRepo.findByPlayedOnIsBefore(LocalDateTime.of(2022, 05, 19, 18, 00, 00));
games.forEach(g -> log.info(g.toString()));
2022-05-20 18:39:56.561 DEBUG 2024 - – [ main] o.s.jdbc.core.JdbcTemplate : Executing prepared SQL query
2022-05-20 18:39:56.562 DEBUG 2024 - – [ main] o.s.jdbc.core.JdbcTemplate : Executing prepared SQL statement [SELECT "chess_game"."id" AS "id", "chess_game"."played_on" AS "played_on", "chess_game"."player_black" AS "player_black", "chess_game"."player_white" AS "player_white" FROM "chess_game" WHERE "chess_game"."played_on" < ?]
请记住,这个功能是为简单查询设计的。作为一个经验法则,我建议只将其用于不需要超过2-3个查询参数的查询。
Spring Data JDBC中的自定义查询
如果你的查询对于派生查询来说过于复杂,你可以用*@Query注解来注解你的存储库方法,并提供一个数据库特定的SQL语句。如果你熟悉Spring Data JPA,这基本上与本地查询功能相同,但它不需要你设置本地查询* 标志,因为Spring Data JDBC不提供它自己的查询语言。
正如你在下面的代码片段中看到的,定义你自己的查询和它听起来一样简单,你可以使用数据库支持的所有功能。
public interface ChessGameRepository extends CrudRepository<ChessGame, Long> {
@Query("""
SELECT g.*
FROM chess_game g
JOIN chess_move m ON g.id = m.chess_game
WHERE m.move = :move
""")
List<ChessGame> findByMovesMove(String move);
}
在本例中,我使用了一条语句,选择了所提供的每一盘棋的chess_game表中的所有列。这些棋步被存储在chess_move 表中,它被映射到ChessMove实体类中。在SQL语句中,我使用一个简单的JOIN子句来连接这两个表,并提供一个WHERE子句来过滤结果。
WHERE子句使用了命名的绑定参数*:move*,并且存储库方法定义了一个具有相同名称的方法参数。当执行这个语句时,Spring Data JDBC自动将方法参数move 的值设置为名称为move的绑定参数。
正如你所看到的,查询本身并没有提供任何关于我想检索所选信息的格式的信息。这是由资源库方法的返回类型定义的。在这种情况下,SQL语句选择了chess_game 表的所有列,Spring Data JDBC将把结果映射到ChessGame实体对象。
List<ChessGame> games = gameRepo.findByMove("e4");
games.forEach(g -> log.info(g.toString()));
正如你在日志输出中看到的,Spring Data JDBC使用了提供的SQL语句,将所有方法参数设置为绑定参数值,并执行了查询。而当它将查询结果映射到ChessGame 对象时,它不得不执行一个额外的查询来获得游戏中的所有棋步,并初始化List moves关联。这被称为n+1选择问题,会导致性能问题。减少性能影响的最好方法是保持你的聚合体小而简洁,或者使用非实体投影,我将在下一节展示。
2022-05-20 19:06:16.903 DEBUG 16976 - – [ main] o.s.jdbc.core.JdbcTemplate : Executing prepared SQL query
2022-05-20 19:06:16.905 DEBUG 16976 - – [ main] o.s.jdbc.core.JdbcTemplate : Executing prepared SQL statement [SELECT g.*
FROM chess_game g
JOIN chess_move m ON g.id = m.chess_game
WHERE m.move = ?
]
2022-05-20 19:06:17.018 DEBUG 16976 - – [ main] o.s.jdbc.core.JdbcTemplate : Executing prepared SQL query
2022-05-20 19:06:17.018 DEBUG 16976 - – [ main] o.s.jdbc.core.JdbcTemplate : Executing prepared SQL statement [SELECT "chess_move"."move" AS "move", "chess_move"."color" AS "color", "chess_move"."move_number" AS "move_number", "chess_move"."chess_game_key" AS "chess_game_key" FROM "chess_move" WHERE "chess_move"."chess_game" = ? ORDER BY "chess_game_key"]
2022-05-20 19:06:17.037 INFO 16976 - – [ main] com.thorben.janssen.TestQueryMethod : ChessGame [id=16, playerBlack=IdOnlyAggregateReference{id=10}, playerWhite=IdOnlyAggregateReference{id=9}, moves=[ChessMove [moveNumber=1, color=WHITE, move=e4], ChessMove [moveNumber=1, color=BLACK, move=e5]]]
Spring Data JDBC中的非实体/非聚合投射
实体对象并不是Spring Data JDBC支持的唯一投影。你也可以将你的查询结果作为Object[]来检索,或者将每条记录映射到一个DTO对象。使用Object[]的工作是非常不舒服的,只得到很少使用。我建议在所有不需要整个集合的用例中使用DTO投影。这可以确保你不会执行任何不必要的语句来初始化你不使用的关联,并提高你的应用程序的性能。
要使用DTO投影,你需要定义一个DTO类。这是一个简单的Java类,为你要选择的每个数据库列都有一个属性。不幸的是,Spring Data JDBC不支持基于接口的投影,你可能从Spring Data JPA中知道这一点。
public class ChessGamePlayerNames {
private Long gameId;
private LocalDateTime playedOn;
private String playerWhiteFirstName;
private String playerWhiteLastName;
private String playerBlackFirstName;
private String playerBlackLastName;
// omitted getter and setter methods for readability
@Override
public String toString() {
return "ChessGamePlayerNames [gameId=" + gameId + ", playedOn=" + playedOn + ", playerBlackFirstName="
+ playerBlackFirstName + ", playerBlackLastName=" + playerBlackLastName + ", playerWhiteFirstName="
+ playerWhiteFirstName + ", playerWhiteLastName=" + playerWhiteLastName + "]";
}
}
只要所选数据库列的别名与你的DTO类的属性名称相匹配,Spring Data JDBC就可以自动映射你的查询结果集的每条记录。你唯一需要做的是将你的资源库方法的返回类型设置为你的DTO类或你的DTO类的List 。
public interface ChessGameRepository extends CrudRepository<ChessGame, Long> {
@Query("""
SELECT g.id as game_id,
g.played_on as played_on,
w.first_name as player_white_first_name,
w.last_name as player_white_last_name,
b.first_name as player_black_first_name,
b.last_name as player_black_last_name
FROM chess_game g
JOIN chess_player w ON g.player_white = w.id
JOIN chess_player b ON g.player_black = b.id
""")
List<ChessGamePlayerNames> findGamePlayerNamesBy();
}
正如你所看到的,查询语句和投影是独立于你的聚合体及其边界的。这就是非实体投影的另一个好处。它给了你自由和灵活性,以最适合你业务逻辑的形式获取数据。
当你在业务代码中使用该存储库方法时,Spring Data JDBC会执行提供的SQL语句。而当它检索到结果时,它将结果集的每条记录映射到ChessGamePlayerNames对象。
List<ChessGamePlayerNames> games = gameRepo.findGamePlayerNamesBy();
games.forEach(g -> log.info(g.toString()));
2022-05-20 19:09:16.592 DEBUG 12120 - – [ main] o.s.jdbc.core.JdbcTemplate : Executing prepared SQL query
2022-05-20 19:09:16.593 DEBUG 12120 - – [ main] o.s.jdbc.core.JdbcTemplate : Executing prepared SQL statement [SELECT g.id as game_id,
g.played_on as played_on,
w.first_name as player_white_first_name,
w.last_name as player_white_last_name,
b.first_name as player_black_first_name,
b.last_name as player_black_last_name
FROM chess_game g
JOIN chess_player w ON g.player_white = w.id
JOIN chess_player b ON g.player_black = b.id
]
2022-05-20 19:09:16.675 INFO 12120 - – [ main] com.thorben.janssen.TestQueryMethod : ChessGamePlayerNames [gameId=16, playedOn=2022-05-19T18:00, playerBlackFirstName=A better, playerBlackLastName=player, playerWhiteFirstName=Thorben, playerWhiteLastName=Janssen]
在日志输出中,你可以看到Spring Data JDBC只执行了为资源库方法定义的查询。在前面的例子中,它不得不执行一个额外的查询来初始化从ChessGame 到ChessMove 实体的映射关联。DTOs不支持映射的关联,因此不会触发任何额外的查询语句。
结论
Spring Data JDBC提供了两个选项来定义自定义查询。
- 衍生查询非常适用于所有不需要任何JOIN子句和不使用超过3个查询参数的简单查询。它们不要求你提供任何自定义的SQL语句。你只需要在你的存储库接口中定义一个遵循Spring Data JDBC命名规则的方法。然后Spring为你生成查询语句。
- 如果你的查询变得更加复杂,你应该用*@Query* 注解来注解你的资源库方法,并提供一个自定义的SQL语句。你必须确保你的SQL语句是有效的,并且与你的数据库的SQL方言相匹配。当你调用存储库方法时,Spring Data JDBC会接收该语句,设置提供的绑定参数值,并执行它。
你可以为这两种类型的查询使用不同的投射。
-
最简单的是实体投射。然后,Spring Data JDBC将为你的实体类定义的映射应用于结果集中的每条记录。如果你的实体类包含与其他实体类的映射关联,Spring Data JDBC会执行额外的查询来初始化这些关联。
如果你想改变数据,或者你的业务逻辑需要整个集合,那么实体投射是一个很好的选择。 -
Object[]s是一种很少使用的投影,它可以很好地适用于只读操作。它们使你能够只选择你需要的列。
-
DTO投影提供了与*Object[]*投影相同的好处,但使用它们要舒服得多。这就是为什么它们是更常用的,也是我对只读操作的首选投影。
正如你在例子中看到的,DTO投影是独立于你的聚合体及其边界的。这使你能够以适合你业务逻辑的格式查询数据。
