

计算中位数有义务从数据中获得中间值。像其他许多函数一样,Postgresql在处理中位数函数方面提供了广泛的通用性。它关注的是如何从使用中位数的表的列中找到中位数的值。与Postgresql的聚合函数COUNT、SUM相比,没有一个特定的函数用于计算中值的聚合。中位数是一个用户定义的函数。
在简单的算术函数中,有不同的手段和公式来寻找任何提供的纯文本或表格形式的数据中的中值。而在数据库系统中,我们使用一些其他的内置函数组合来获得中位数的值。本文将详细介绍一些最有效的技术和我们创建的手动函数,以从Postgresql的数据中获取中位数。
使用percentile_count()和percentile_disc()
这两种方法都是以稍微不同的方式获得中位数。因为它们的结果值的不同是基于它们的方法论。Percentile指的是用百分之百的百分比来描绘数据值。但对于中位数,我们使用(0.5)值。两者的主要区别在于,percentile_count()插值,其工作是基于数值的连续分布,而percentile_disc()从给定的数据中返回数值,并依靠计算离散分布的百分位数来计算。
这两个百分位数的语法是:
SELECT percentile_count(0.5) within group (order by x) from values (a),(b),(c),(d)) v (x);
SELECT percentile_disc(0.5) within group (order by x) from values (a),(b),(c),(d)) v (x);
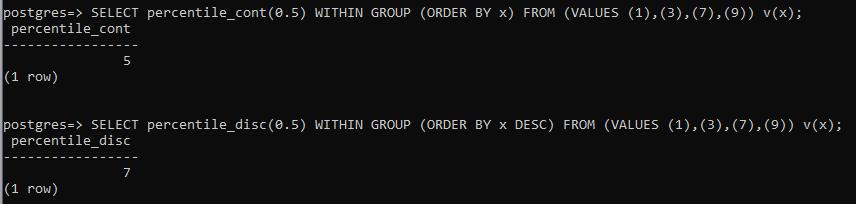
对于给定的值,percentile_disc将返回数据中唯一存在的值。Percentile_count计算出数值的中位数。例如,在偶数之间。在上面的例子中,percentile_count将给出3和7之间的数字 "5"。而percentile_disc显示的是7,从降序排列。由于这个函数的值总是来自于现有的数据。所以它提供的是计算后与中位数最接近的值。
由于postgresql中的数据存在于关系(表)中,百分位数被应用于数值列(工资)。我们创建了一个名为教授的表。下面的查询将帮助我们首先说明表的属性,然后对其应用percentile_disc()。
>> select * from professor ; select percentile_disc(0.5) within group (order by profession.pay) from professor;
查询的前半部分将显示表的内容,而后半部分将选择百分位数的值。这里应用了一个order by子句。这个子句将把相关列的项目按升序排列,然后对其应用函数。这个查询的列(pay)正在使用中,将被执行。
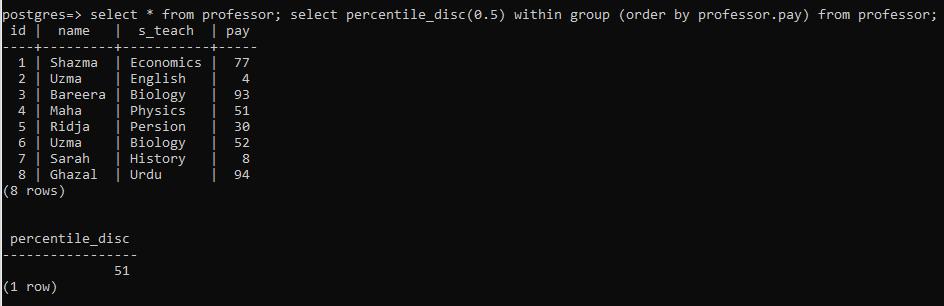
执行后,结果是51,这是一个由百分位数函数得到的独特数值。为了更清楚地说明问题,用一个简单的 "ntile "乘以100,将该列的每个元素按升序排列。
>> select professor. pay, ntile(100) over (order by professor. pay) from professor;
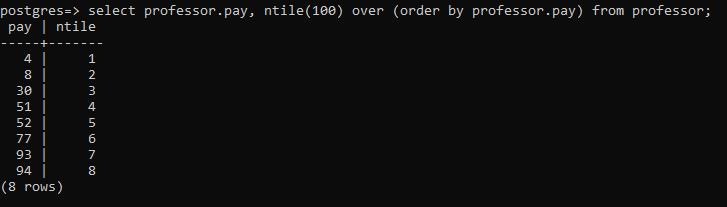
上述命令从表中传达了 "pay "列。它使我们更容易理解percentile_disc的操作方式。由于 "pay "列中的总数字有8行是偶数。所以很难得到数据的准确中点。Disc()会去找最接近的值。也就是按照升序排列的 "51"。
在percentile_count的情况下,命令的其余部分是相同的,但功能从disc改为CONT。正如其名称所表明的percentile_cont的工作原理一样,数值是以连续的形式出现的,这意味着至今没有结束。因此,结果总是以小数形式出现。这将赋予两个相邻数字的中间值。换句话说,在偶数的情况下,这个函数获取列中心的两个数字。
>> select percentile_count(0.5) within Group (order by profrssor.pay) from professor;

在51和52之间,它的 "51.5 "是 "pay "列中值的精确连续值。
你也可以在任何函数中改变百分位数的值。例如,我们用0.25、0.5和0.75作为percentile_disc()的参数。
Percentile_disc(0.25)
Percentile_disc(0.5)
Percentile_dic(0.75)

使用函数中的这种语法,所有的数值都被集体显示在一行中。考虑一下我们所附的快照,它显示了该列的ntile,所有的值都是按升序排序的。如果0.5导致的值是 "51",那么对于0.25,它是8,对于 "0.75",它是77。因为它是存在于id 4的数字,所以对于0.25,它是分别根据第四个id计算的。而0.75也是类似的情况。
使用函数计算中位数
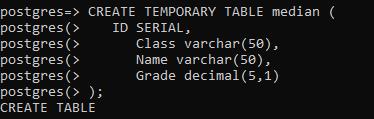
为了执行计算表的中位数的函数,我们需要有一个新的样本表。在创建之后,数值将被添加,使其处于功能状态。使用临时表是因为我们不需要这个数据在数据库中存在较长的时间。
>> create temporary table median ( id serisl, class varchar(50), name varchar(50), Grade decimal(5,1) );
>> insert into median (class, name, grade) values (‘x’, ‘y’, z);

在插入值之后,我们将对插入的数据进行观察。为了这个目的,使用SELECT语句。
>>select * from median,

在这个函数中,每个类别的中位数将被单独计算。这种划分是根据类列进行的。 数据以ASC和DESC两种顺序进行排序。这里初始化了一个新函数ROW NUMBER()。这将获取行号,然后根据它进行操作。让我们看一下代码。然后我们将把它分解,看看这里发生了什么,以获得中位数。
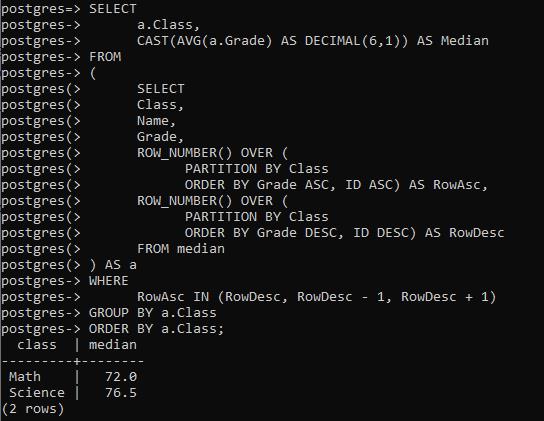
使用SELECT命令,引入子查询。这个子查询使用ROW NUMBER(),它将按升序和降序排列行。对于每一个类,命令都是用于行号。
每当你要在具有偶数值的列表中寻找中位数时,答案总是在于像PERCENTILE_CONT那样取中间两个数字的平均值。这就是在这个命令中得到中位数的情况。
RowAsc IN (RowDesc, RowDesc - 1, RowDesc + 1)
结果被从子查询中送回主查询。然后计算出一个平均数。对于数学来说,我们得到72.0,这是在一个奇数值列表的情况下的预期中间值。而对于科学来说,它是76.5。在科学科目中有一个偶数,所以我们得到的中间值是72和81。
结论
POSTGRESQL MEDIAN FUNCTION使得在普通数据或表格数据中寻找中点比手动计算更容易。尽管它是一个用户创建的函数,但它确实使用了一些内置函数来获取相关的记录。PERCENTILE_CONT和PERCENTILE_DISC被认为是所讨论主题的核心。因为它们在函数中提供中位数概念的默默支持是非常了不起的。然而,所有这些函数对于寻找中位数都是足够的。
