

青训营Flink引擎
2022の夏天,半壶水响叮当的我决定充实一下自我
一、内容介绍
青训营
二、Flink简介
简介:流数据框架,流批一体,分布式处理引擎,支持无界数据(实时更新,流式)与有界数据(批式)状态运算stateful
2.1大数据框架(旧批式)
为什么有大数据框架后需要流数据框架?
大数据特点:
大数据(Big Data):指无法在一定时间内用常规软件工具对其进行获取、存储、管理和处理的数据集合。
价值化,价值密度小,但总体大
海量化
多样化,数据半结构化,结构化,格式化
快速化
大数据发展史:
流数据框架产生:
行业对流数据需求增加
大数据实时性需求
如:
1.监控场景
2.金融风险控制
3.短视频等平台对实时推荐需求
2.2大数据发展框架(现在流式)
计算框架发展史:
流式计算引擎对比:
Streaming Model:1. Naitve:数据进入立即处理(单条数据);2. Micro-Batch:数据流入后,先划分成Micro-Batch,再处理(批处理);
consistent一致:下游处理次数,后续业务操作量随一致性增强而减少
容错:能否恢复(撤回,调数据)
StateFul:状态管理,1. 基于操作的状态管理:每次操作有一个状态;2. 基于数据的状态管理:每个数据有相应的处理状态;
SQL支持:内嵌SQL简单语言,减少维护成本,业务迭代速度降低,减少代码code
2.3Flink框架脱颖而出
Flink 简介:
流数据框架;流批一体;分布式处理引擎;支持无界数据(实时更新,流式)与有界数据(批式)状态运算statefu;,Dataflow窗口交互式命令
Apache Flink is a framework and distributed processing engine for stateful computations over unboundedand bounded data streams. Flink has been designed to run in all common cluster environments, performcomputations at in-memory speed and at any scale.---来自Apache Flink社区官方介绍
ApacheFlink是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态计算。Flink被设计为在所有常见的集群环境中运行,以内存中的速度和任何规模进行性能计算.--来自apache flink社区官方介绍
开源生态:
1.ApacheFlink无存储,但支持数据存储引擎继承:
MQ(消息队列):Kafka,RockrtMQ,RabbiitMQ
KV数据型数据库:Redis
离线数据源:Hive,Clicjhouse
(OLAP数据,联机数据):Clickhouse
2.Resource Manager部署模式,虚拟机,物理机上部署(三类)
3.其他可支持框架:Gelly(Graph)图计算;Flink ML(AI,机械学习);Stateeful Function状态储存
三、Flink整体架构
3.1. Flink 分层架构
Flink各个模块的用途
1.(外部接口)STK层:SQL/Table、DataStream(JAVA)、Python(AI,ML下) ;
DAG API:数据接口,流式或批式
2.执行引擎层(Runtime层):执行引擎层提供了统一的 DAG,用来描述数据处理的Pipeline,不管是流还是批,都会转化为DAG图,
2. DAG Scheduler调度层再把DAG转化成分布式环境下的Task ,Task之间通过Shuffle 传输数据;
DAG Scheduler/Service:数据转DAG图,并分布式任务传递,Service指数据交互
3.状态存储层∶负责存储算子的状态信息;
State Backend状态存储层,方便回溯,RocksDB性能更好
4.资源调度层∶目前Flink 可以支持部署在多种环境。
Resource Manager部署模式,虚拟机,物理机上部署(三类)
3.2.Flink总体架构
Master/Slave 架构、JobManager/TaskManager
数据API接口 -> 转DAG图 -> JM协调 <--> TM执行(TM自我数据交互Data Steam)
一个Flink集群,主要包含以下两个核心组件:
1.JobManager (JM):负责整个任务的协调工作,包括:调度task、触发协调Task做 Checkpoint、协调容错恢复等;
2.TaskManager (TM):负责执行一个DataFlowGraph 的各个task以及 data streams的 buffer和数据交换。
JM与TM交互示意图
Dispatcher:接收作业(DAG图),拉起JobManager来执行作业,并在JobMaster挂掉之后恢复作业;
JobMaster:管理一个job(作业)的整个生命周期,会向ResourceManager申请slot,并将task调度到对应TM上;
ResourceManager:负责slot资源的管理和调度,Task manager(对接资源插哨slot)拉起之后会向RM注册;
3.3.Flink 作业示例
一个Flink 作业在 Flink 中的处理流程、DataFlow Model设计思想
3.3.1流式的WordCount示例,从 kafka 中读取一个实时数据流,每10s统计一次单词出现次数,DataStream实现代码如
// Source源
//FlinkKafkaconsumer<>(地址,Topeka)
DataStream<String> lines = env.addSource (
new FlinkKafkaconsumer<>(...) );
//Transformation 转
//map一对一处理,parse取消空格
DataStream<Event> events = lines.map((line)->parse(line));
//Transformation
//keyBy分发,timewindow时间窗口,apply聚合函数,函数:见+1
//statistics类型
DataStream<statistics> stats = events
.keyBy (event -> event.id)
.timewindow (Time.seconds ( 10 ) )
.apply (new MywindowAggregationFunction ( ) ) ;
//sink保存,打印,输出
stats.addsink (new BucketingSink(path) ) ;
业务逻辑转换为一个 Streaming DataFlow Graph(流数据流程图)
3.3.2分布式运行,并行
假设作业的sink 算子的并发配置为1,其余算子并发为2
紧接着会将上面的Streaming DataFlow Graph转化Parallel Dataflow(内部叫Execution Graph) :
为了更高效地分布式执行(减少哈希,多线程切换,线程数据交换带来的序列化与反序列化等问题),Flink 会尽可能地将不同的operator链接(chain)在一起形成Task,这样每个Task 可以在一个线程中执行,内部叫做OperatorChain,如下图的source和map算子可以Chain在一起。
最后将上面的Task调度到具体的TaskManager(自定义Slot量)中的slot中执行,一个Slot只能运行同一个task的subTask
一个进程(Processes)由多线程(Threads)运行
3.4.Flink如何做到流批一体
流批一体的业务场景及挑战、Flink 如何做到流批一体
Shuffle Service预习
流批一体原因:
1.人力成本比较高:批、流两套系统,相同逻辑需要开发两遍;
2.数据链路冗余:本身计算内容是一致的,由于是两套链路,相同逻辑需要运行两遍,产生一定的资源浪费;
3.数据口径不一致:两套系统、两套算子、两套UDF,通常会产生不同程度的误差,这些误差会给业务方带来非常大的困扰。
特点
区别
3.4.1.Flink如何实现流批一体
1(理论).批式计算是流式计算的特例,Everything is Streams,有界数据集(批式数据)也是一种数据流、一种特殊的数据流;
不同场景支持相应的扩展性,不同的优化策略
站在Flink的角度,Everything is Streams(流),无边界数据集是一种数据流,一个无边界的数据流可以按时间切段成一个个有边界的数据集,所以有界数据集(批式数据)也是一种数据流
因此,不管是有边界的数据集(批式数据)还是无边界数据集,Flink都可以天然地支持,这是Flink支持流批一体的基础。并且Flink在流批一体上,从上面的API到底层的处理机制都是统一的,是真正意义上的流批一体。
2(实现).Apache Flink主要从以下几个模块来做流批—体:
- SQL层;
- DataStream API层统一,批和流都可以使用DataStream API来开发;
- Scheduler层架构统一,支持流批场景;
- Failover Recovery(故障转移恢复)层架构统一,支持流批场景;
- Shuffle Service层架构统一,流批场景选择不同的 Shuffle Service;
2.4.4.流批一体的Scheduler层(多线程执行) Scheduler主要负责将作业的 DAG转化为在分布式环境中可以执行的Task
在1.12之前的Flink版本中,Flink支持以下两种调度模式:
流数据:stream---EAGER
批数据:Batch---LAZY

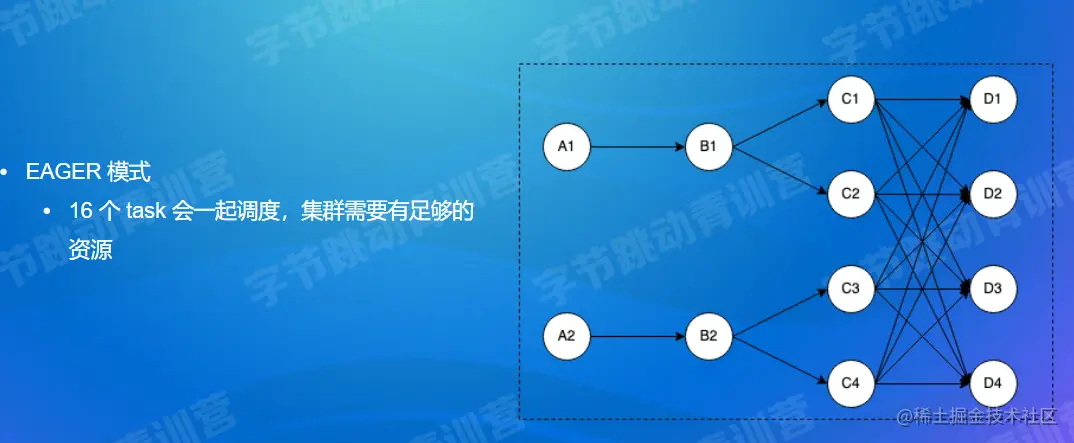
最新的Flink版本中,调度模式:
由Pipeline的数据交换方式连接的Task构成为一个Pipeline Region(流水线区);
本质上,不管是流作业还是批作业,都是按照 Pipeline Region粒度来申请资源和调度任务。
Reaource资源,Peformance性能
3.流批一体的Scheduler层
(1)(流) ALL_EDGES_BLOCKING:
所有Task之间的数据交换都是BLOCKING模式(保留数据);
分为12个pipeline region;
(2)(批) ALL EDGES PIPELINED:
所有Task之间的数据交换都是PIPELINE模式(不保留,直接传数据);
分为1个pipeline region;
4.Shuffle Service定义: Shuffle:在分布式计算中,用来连接上下游数据交互的过程叫做 Shuffle。
实际上,分布式计算中所有涉及到上下游衔接的过程,都可以理解为Shuffle。
(两种实现)针对不同的分布式计算框架,Shuffle不同的实现:
1.(批)基于文件的Pull Based Shufile,比如Spark 或MR,它的特点是具有较高的容错性,适合较大规模的批处理作业由于是基于文件的,它的容错性和稳定性会更好一些;
2.(流)基于Pipeline 的Push Based Shufle,比如Flink、Storm、Presto等,它的特点是低延迟和高性能,但是因为shuffle(批)数据没有存储下来,如果是批式任务的话,就需要进行重跑恢复;
流和批 Shuffle之间的差异:
- Shuffle数据的生命周期:
流作业的 Shuffle数据(task数据交换)与Task是绑定的,
批作业(不滞留数据)的 Shuffile数据与Task是解耦的;- Shuffle数据存储介质:
流作业的生命周期比较短、为了实时性,Shuffie通常存储在内存中,
批作业因为数据量比较大以及容错的需求,一般会存储在磁盘里(备份);- Shuffle的部署方式(stateful):
流作业 Shuffle服务和计算节点部署在一起,可以减少网络开销,从而减少latency
批作业则不同。
Flink实现:
Flink对于流和批提供两种类型的Shuffile,虽然 Streaming和Batch Shuffle在具体的策略上存在一定的差异,但本质上都是为了对数据进行Re-Partition,因此不同的Shufle之间是存在一定的共性的。
所以Flink的目标是提供一套统一的Shufile架构,既可以满足不同Shufile在策略上的定制,同时还能避免在共性需求上进行重复开发。
Flink支持Shuffle Service:
- Netty Shuffile Service:既支持pipeline又支持blocking,Flink默认的shuffle Service策略;
- Remote Shuffle Service:既支持pipeline又支持 blocking,不过对于pipeline模式,走remote反而会性能下降,主要是有用在batch 的blocking场景,字节内部是基于CSS来实现的RSS。
四、Flink架构优化
4.1.流/批/OLAP业务场景概述
在实际生产环境中,针对不同的应用场景,我们对数据处理的要求是不同的:
1.有些场景下,只需离线处理数据,对实时性要求不高,但要求系统吞吐率高,典型的应用是搜索引擎构建索引;
2.有些场景下,需对数据进行实时分析,要求每条数据处理延迟尽可能低,典型的应用是广告推荐、金融风控场景.
4.2.为什么三种场景可以用一套引擎来解决
1.批式计算是流式计算的特例,Everything is Streams(流),有界数据集(批式数据)也是一种数据流、一种特殊的数据流;
2.而OLAP计算是一种特殊的批式计算,它对并发和实时性要求更高,其他情况与普通批式作业没有特别大区别。
3.OLAP是特殊批式,批式是特殊流式
4.3.Flink 如何支持OLAP场景
- Flink做OLAP的优势
2.Flink OLAP场景的挑战
3.Flink OLAP架构现状
- Flink在OLAP 架构的问题与设想
架构与功能模块:
- JobManager 与ResourceManager在一个进程内启动,无法对JobManager进行水平扩展;
- Gateway 与Flink Session Cluster 互相独立,无法进行统一管理。
作业管理及部署模块:
- JobManager处理和调度作业时,负责的功能比较多,导致单作业处理时间长、并占用了过多的内存;
2.TaskManager部署计算任务时,任务初始化部分耗时严重,消耗大量CPU
资源管理及计算任务调度:
1.资源申请及资源释放流程链路过长
2.Slot作为资源管理单元,JM管理slot资源,导致JM无法感知到TM维度的资源分布,使得资源管理完全依赖于ResourceManager
其他:
1.作业心跳与Failover机制,并不合适AP这种秒级或毫秒级计算场景;
2.AP目前使用Batch(批)算子进行计算,这些算子初始化比较耗时;
五、社区
5.1电商流批一体实践
案例
社区

5.2字节Flink OLAP 实践
字节
传统
晚安玛卡巴卡
快乐暑假
