

流/批/OLAP 一体的 Flink 引擎介绍-复习笔记
这是我参与「第四届青训营 」笔记创作活动的的第3天!
1. Flink概述
1.1 Apache Flink 的诞生背景
1.1.1 什么是大数据
大数据(Big Data):指无法在一定时间内用常规软件工具对其进行获取、存储、管理和处理的数据集合。
大数据的特点:
- 海量化(Volumes)
- 多样化(Variety)
- 快速化(Velocity)
- 价值化(Value)
1.1.2 大数据计算框架发展历史
(1)史前阶段~2006年
传统数据仓库,Oracle,单机,黑箱使用
(2)Hadoop
分布式,Map-Reduce,离线计算
(3)Spark
批处理,流处理,SQL 高阶 API,内存迭代计算
(4)Flink
流计算,实时、更快,流批一体,Streaming/Batch SQL
1.1.3 为什么需要流式计算
(1)大数据的实时性带来更大价值,比如:
- 监控场景
- 金融风险
- 实时推荐等
(2)大数据实时性的需求,带来了大数据计算架构模式的变化
①批式计算特点:
- 离线计算,非实时;
- 静态数据集;
- 小时/天等周期计算
②流式计算特点:
- 实时计算,快速、低延迟;
- 无限流、动态、无边界;
- 7*24小时持续运行;
- 流批一体
1.2 为什么 Apache Flink 会脱颖而出
1.2.1 流式计算引擎发展历史
1.2.2 流式计算引擎对比
| Storm | Spark Streaming | Flink | |
|---|---|---|---|
| Streaming Model | Native | mini-batch | Native |
| 一致性保持 | At Least/Most once | Exactly-Once | Exactly-Once |
| 延迟 | 低延迟(毫秒级) | 延迟较高(秒级) | 低延迟(毫秒级) |
| 吞吐 | Low | High | High |
| 容错 | ACK | RDD Based Checkpoint | Checkpoint(Chandy-Lamport) |
| StateFul | No | Yes(DStream) | Yes(Operator) |
| SQL支持 | No | Yes | Yes |
1.2.3 Why Flink
- Exactly-Once 精确一次计算的语义
- Checkpoint 状态容错
- Dataflow 编程模型,Window 等高阶需求支持友好
- 流批一体
1.3 Apache Flink 开源生态
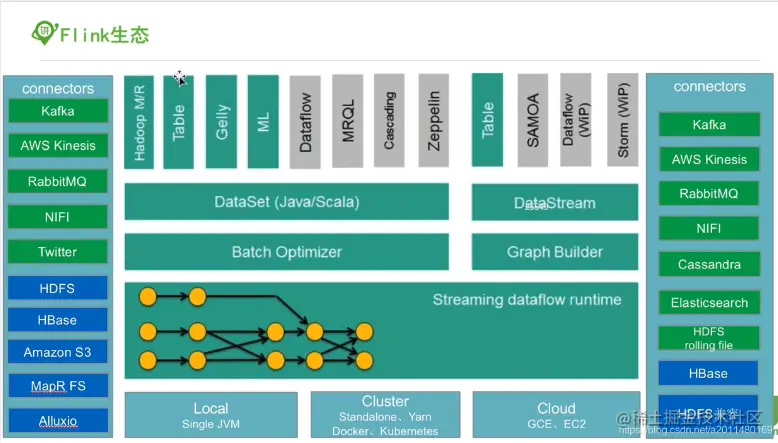 (图片来源)
(图片来源)
2. Flink 整体架构
2.1 Flink 分层架构
1、SDK 层
Flink 的 SDK 目前主要有三类,SQL/Table,DataStream,PyFlink
2、执行引擎层(Runtime 层)
执行引擎层提供了统一的 DAG,用来描述数据处理的 Pipeline,不管是流还是批,都会转化为 DAG 图,调度层再把 DAG 转化成分布式环境下的 Task,Task 之间通过 Shuffle 传输数据
3、状态存储层
状态存储层负责存储算子的状态信息
4、资源调度层
目前 Flink 支持部署在多种环境。
2.2 Flink 总体架构
一个 Flink 集群,主要包含以下两个核心部件:
1、JobManager(JM)
负责整个任务的协调工作,包括:调度 Task 、触发协调 Task 做Checkpoint、协调容错恢复等。
JobManager(JM) 主要职责:
(1)Dispatcher:
接收作业,拉起 JobManager 来执行作业,并在 JobMaster 挂掉之后恢复作业;
(2)JobMaster:
管理一个 Job 的整个生命周期,会向 ResourceManager 申请 Slot ,并将 Task 调度到对应 TM 上;
(3)ResourceManager:
负责 Slot 资源的管理与调度, TaskManager 拉起之后会向 RM 注册。
2、TaskManager(TM)
负责执行一个 DataFlow Group 的各个 task 以及 Data Streams 的 buffer 和数据交换。
2.3 Flink 作业示例
流式 WordCount 示例,从 Kafka 中读取一个实时数据流,每 10s 统计一次单词出现次数, DataStream 实现代码如下:
//Sourse
DataStream<String> lines = env.addSourse(new FlinkKafkaConsumer<>(...));
//Transformation
DataStream<String> events = lines.map((line) -> parse(line));
DataStream<Statistics> stats = events.keyBy(event -> event.id)
.timeWindow(Time.seconds(10)).apply(new myWindowAggregationFunction());
//Sink
stats.addSink(new BucketingSink(path));
2.4 Flink 如何做到流批一体
2.4.1 为什么需要流批一体
原有架构下流批分离,数据从数据源分别流向实时数仓(Flink)和离线数仓(Spark/Hive)存在一些痛点
(1)人力成本较高:批、流两套系统,相同逻辑需要开发两遍;
(2)数据链路冗余:本身设计内容是一致的,由于是两套链路,相同逻辑需要运行两遍,产生一定的资源浪费;
(3)数据口径不一致:两套系统、两套算子、两套 UDF ,通常会产生不同程度的误差,这些误差会给业务方带来非常大的困扰
2.4.2 流批一体的挑战
流和批业务场景的特点如下表:
| 流式计算 | 批式计算 |
|---|---|
| 实时计算 | 离线计算 |
| 延迟在秒级以内 | 处理时间在分钟到小时级别甚至天级别 |
| 0~1 s | 10 s ~ 1 h+ |
| 广告推荐、金融风控 | 搜索引擎构建索引、批式数据分析 |
批式计算相比于流式计算核心区别如下表:
| 维度 | 流式计算 | 批式计算 |
|---|---|---|
| 数据流 | 无限数据集 | 有限数据集 |
| 时延 | 低延迟、业务会感知运行中的情况 | 实时性要求低,只关注最终结果产出时间 |
2.4.3 Flink 如何做到流批一体
- 批式计算是流式计算的特例, Everything is Streams ,有界数据集(批式数据)也是一种数据流、一种特殊的数据流。
- 因此,理论上我们可以用一套引擎架构来解决上述两种场景,只不过需要对不同场景支持相应拓展性、并允许做不同的优化策略。
- 因此不管是有边界数据集(批式数据)还是无边界数据集, Flink 都可以天然支持,这是 Flink 支持流批一体的基础。并且 Flink 在流批一体上,从上层 API 到底层的处理机制都是统一的,是真正意义上的流批一体。
Apache Flink 主要从以下几个模块来做流批一体:
(1)SQL层;
(2)DataStream API 层统一,批和流都可以使用 DataStream API 来开发;
(3)Scheduler 层架构统一,支持流批场景;
(4)Failover Recovery 层架构统一,支持流批场景;
(5)Shuffle Service 层架构统一,流批场景选择不同的 Shuffle Service。
2.4.4 流批一体的 Scheduler 层
- Scheduler 层主要负责将作业的 DAG 转化成在分布式环境中可以执行的 Task。
- 在1.12之前的 Flink 版本中,Flink 支持以下两种调度模式:
(1)EAGER 模式,常用于 Stream 作业场景,特点是申请一个作业所需要的全部资源,然后同时调度这个作业的全部 Task ,所有的 Task 之间采取 Pipeline 方式进行通信;
(2)LAZY 模式,常用于 Batch 作业场景,特点是先调度上游,等待上游产生数据或结束后再调度下游,类似 Spark 的 Stage 执行模式。 - 在最新的 Flink 版本中,由 Pipeline 的数据交换方式连接的 Task 构成为一个 Pipeline Region ;本质上不管是流作业还是批作业,都是按照 Pipeline Region 粒度来申请资源和调度任务。
2.4.5 流批一体的 Shuffle Service 层
-
Shuffle:在分布式计算中,用来连接上下游数据交互的过程叫做 Shuffle。
-
实际上,分布式计算中所有涉及到上下游衔接的过程,都可以理解为 Shuffle。
-
针对不同的计算框架,Shuffle 通常有几种不同的实现:
(1)基于文件的 Pull Based Shuffle ,比如 Spark 或 MR,其特点是具有较高的容错性,适合较大规模的批处理作业,由于是基于文件的,它的容错性和稳定性会更好一些
(2)基于 Pipeline 的Push Based Shuffle ,比如 Flink、 Storm、 Presto 等,其特点是低延迟和高性能,但是因为 Shuffle数据没有存储下来,如果是 Batch 任务的话,就需要进行重跑恢复。 -
流和批 Shuffle 之间的差异:
(1)Shuffle 数据的生命周期:流作业的 Shuffle 数据与 Task 是绑定的,而批作业的 Shuffle 数据与 Task 是解耦的;
(2)Shuffle 数据的存储介质:流作业的生命周期比较短,而且流作业为了实时性,Shuffle 通常存储在内存中,批作业因为数据量比较大以及容错的需求,一般会存储在磁盘里;
(3)Shuffle 的部署方式:流作业 Shuffle 服务和计算节点部署在一起,可以减少网络开销,从而减少 latency,而批作业不同。 -
Flink 对于流和批提供两种类型 Shuffle,虽然 Streaming 和 Batch Shuffle 在具体的策略上存在一定的差异,但本质上都是为了对数据进行 Re-Partition ,因此不同的 Shuffle 之间是存在一定共性的。
-
所以 Flink 的目标是提供一套统一的 Shuffle 架构,既可以满足不同 Shuffle 在策略上的定制,同时还能避免在共性需求上进行重复开发。
3. Flink 架构优化
3.1 流/批/OLAP 业务场景概述
- 三种业务场景的特点对比: | 流式计算 | 批式计算 | 交互式分析 | |---|---|---| |实时计算|离线计算|OLAP| 延迟在秒级以内|处理时间在分钟到小时级别甚至天级别|处理时间秒级 0 ~ 1 s|10 s ~ 1 h+|1 ~ 10 s 广告推荐、金融风控|搜索引擎构建索引、批式数据分析|数据分析BI报表
- 三种业务场景解决方案的要求及带来的挑战: | 模块 | 流式计算 | 批式计算 | 交互式分析(OLAP) | |---|---|---|---| SQL|Yes|Yes|Yes 实时性|高、处理延迟毫秒级别|低|高、查询延迟秒级别,但要求高并发查询 容错能力|高|中,大作业失败重跑代价高|No ,失败重试即可 状态|Yes|No|No 准确性|Exactly Once,要求高,重跑需要恢复之前的状态|Exactly Once,失败重跑即可|Exactly Once,失败重跑即可 可扩展性|Yes|Yes|Yes
3.2 为什么三种场景可以用一套引擎来解决
- 通过前述对比分析,可以发现:
(1)批式计算是流式计算的特例, Everything is Streams ,有界数据集(批式数据)也是一种数据流、一种特殊的数据流;
(2)而 OLAP 计算是一种特殊的批式计算,它对并发性和实时性要求更高,其他情况与普通批式作业没有特别大区别。 - 因此,理论上我们是可以用一套引擎架构来解决上述三种场景,只不过需要对不同场景支持相应的扩展性、并运行做不同的优化策略。
3.3 Flink 如何支持 OLAP 场景
- Apache Flink 从流式计算出发,需要想支持 Batch 和 OLAP 场景,就需要解决下面的问题:
(1)Batch 场景需求
①流批一体支持;
②Unify DataStream API;
③Scheduler;
④Shuffle Service;
⑤Failover Recovery。
(2)OLAP 场景需求
①短查询作业场景
②高并发支持;
③极致处理性能。
3.3.1 Flink 做 OLAP 的优势
- 引擎统一:降低学习成本、提高开发效率、提高维护效率;
- 既有优势:内存计算、Code-gen、Pipeline Shuffle、Session 模式的MPP架构;
- 生态支持:跨数据源查询支持、TCP-DS 基准测试性能强。
3.3.2.Flink OLAP 场景的挑战
- 秒级和毫秒级的小作业;
- 作业频繁启停,资源碎片;
- Latency + QPS的要求。
3.3.3.Flink OLAP 架构现状
- Client:提交 SQL Query;
- Gateway
- 接收 Client 提交的 SQLQuery,对 SQL 进行语法解析和查询优化,生成 Flink 作业执行计划,提交给 Session 集群;
- Session Cluster
- 执行作业调度及计算,并返回结果。
3.3.4.Flink 在 OLAP 架构的问题与设想
- 架构与功能模块:
- JobManager 与 ResourceManager 在一个进程内启动,无法对 JobManager 进行水平扩展;
- Gateway 与 Flink Session Cluster 互相独立,无法进行统一管理。
- 作业管理及部署模块:
- JobManager 处理和调度作业时,负责的功能比较多,导致单作业处理时间长、并占用了过多的内存;
- TaskManager 部署计算任务时,任务初始化部分耗时严重,消耗大量CPU。
- 资源管理及计算任务调度:
- 资源申请及资源释放流程链路过长;
- Slot 作为资源管理单元,JM 管理 slot 资源,导致 JM 无法感知到 TM 维度的资源分布,使得资源管理完全依赖于 ResourceManager。
- 其他:
- 作业心跳与 Failover 机制,并不合适 AP 这种秒级或毫秒级计算场景;
- AP 目前使用 Batch 算子进行计算,这些算子初始化比较耗时。
4. 精选案例讲解
4.1 电商流批一体实践
- 目前电商业务数据分为离线数仓和实时数仓建设,离线和实时数据源,计算引擎和业务代码没有统一,在开发相同需求的时候经常需要离线和实时对齐口径,同时,由于需要维护两套计算路径,对运维也带来压力。
- 从数据源,业务逻辑,计算引擎完成统一,提高开发和运维效率。
4.2 Flink OLAP 场景实践
- Flink的OLAP在字节内部的场景主要是HTAP场景。
