

cuDF - RAPIDS GPU数据框架
cuDF 是一个非常类似于 的数据框架库,它在GPU上运行,以便从其计算能力中获益。
在这个阶段,我们可以回顾一下,现在有很多数据框架库,比如。 pandas, vaex, modin, dask/cudf-dask。每一个都有其优势和劣势。例如,vaex 允许你在笔记本电脑上处理比内存(RAM)更大的数据集,dask 允许你在进程和集群节点之间分配计算,cudf-dask 是它的GPU对应项。
假设你的笔记本上有一个300GB的数据集,并想获得一些关于它的见解。一个典型的工作流程可以是。
import vaex
# run some exploratory data analysis (EDA)
import dask, cudf
# take a sample of 3 GB
# run some operations with Dask, then cuDF and compare performance.
在这一过程中,我们多次加载数据集。我们使用一对to_pandas/from_pandas ,从一个数据框架库转移到另一个。这种做法出现了挑战。
-
可能的内存开销
-
与
pandas的高度耦合,破坏了一个重要的软件设计模式。[依赖反转原则(DIP)]促进了抽象层(接口)的依赖,而不是实现层。
数据框架协议作为指定数据框架通用表示法的接口开始发挥作用,从而恢复了被打破的依赖反转设计模式。
现在,我们可以直接使用from_dataframe 方法从一个数据框架库移动到另一个。不需要再通过pandas 。请注意,这只有在支持该协议的数据框架库之间才有可能。另外,该协议尽可能地执行零拷贝,这使我们摆脱了可能的内存开销。
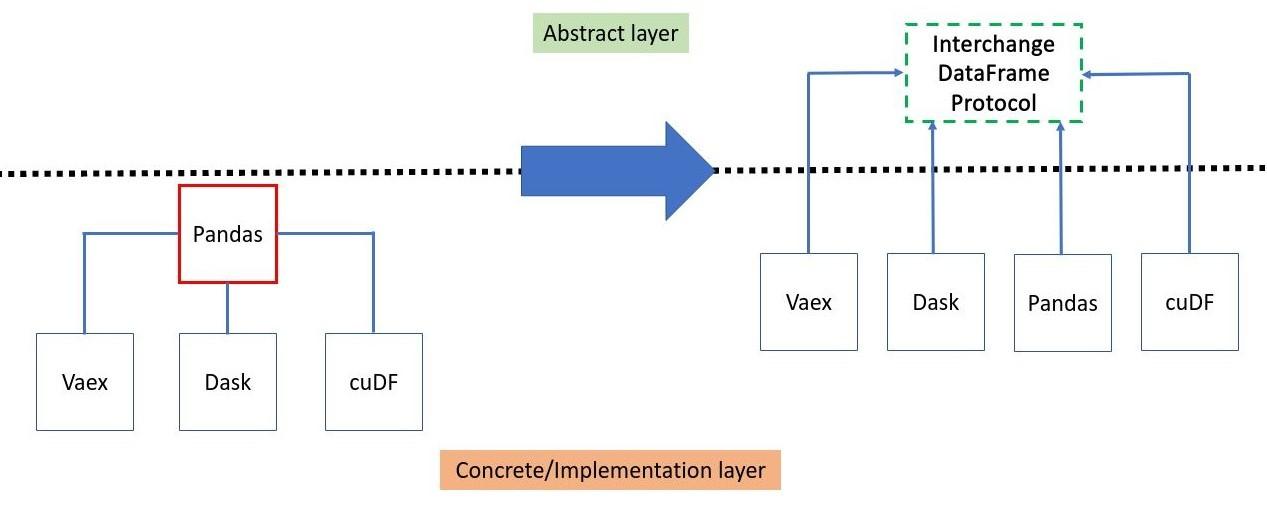 没有和有数据框架交换协议API的设计比较
没有和有数据框架交换协议API的设计比较
遵守数据框架交换协议的库的主要好处之一是,只要遵循接口合同规范,每个库都可以独立发展,我们可以像pandas那样摆脱对数据框架库的依赖。
数据框架交换协议的简要描述
数据框架交换协议实际上是一个接口的组合。
 数据框架交换协议接口的组成。链接上的cardinality意味着 "拥有1个或更多 "提到的接口。
数据框架交换协议接口的组成。链接上的cardinality意味着 "拥有1个或更多 "提到的接口。
所以每个支持该协议的库都应该实现这3个接口,可以描述如下。
-
DataFrame主要暴露了不同的方法来访问/选择列(通过名称、索引)和知道行的数量。
-
Column有方法来访问列的数据类型,描述有效/缺失的值,公开不同的缓冲区(数据、有效性和偏移量),Chunks,...等等。
-
缓冲区有描述列数据的连续内存块的方法,即设备(GPU,CPU,...),内存地址,大小等。
对cuDF 接口的实现有什么期望
让我们回顾一下要在cuDF 中实现的协议主要特征。
| 简单dtype | 复杂dtype | 设备 | 缺少的值 | 块 |
|---|---|---|---|---|
| int | 分类的 | GPU | 所有的dtypes(简单和复杂) | 单一 |
| uint8 | 字符串 | CPU | - | 倍数 |
| float | 数据时间 | - | - | - |
上表显示了应该支持的数据框架交换协议的不同特征。特别是,我们必须支持带有各种类型(简单和复杂)的列的cuDF数据帧,并处理它们的缺失值。同样,我们也必须支持来自不同设备的数据帧,如CPU。
cuDF 数据框架交换协议的进展
下表中被选中的元素代表了到目前为止已经实现的功能。
| 简单dtype | 复杂dtype | 设备 | 缺少的值 | 块 |
|---|---|---|---|---|
| int | 分类的 | GPU | 所有支持的dtypes(简单和复杂)。 | 单一 |
| uint8 | 字符串 | CPU | - | 倍数 |
| float | 数据时间 | - | - | - |
| bool | - | - | - | - |
请注意,我们支持像pandas一样的CPU数据帧,但由于该协议还没有被集成到pandas repo中,我们只能在本地进行测试。我们已经将这项工作作为一个仍在审查中的Pull Request提交到rapidsai/cudf github repo。
工作cuDF 代码示例
当我们在pandas 和cuDF 之间往返时,我们将通过一个代码实例来了解该协议的运行情况。我们首先创建一个cuDF数据框架对象,列以支持的dtypes命名。
import cudf
import cupy as cp
data = {'int': [1000, 2, 300, None],
'uint8': cp.array([0, 128, 255, 25], dtype=cp.uint8),
'float': [None, 2.5, None, 10],
'bool': [True, None, False, True],
'string': ['hello', '', None, 'always TDD.']}
df = cudf.DataFrame(data)
df['categorical'] = df['int'].astype('category')
让我们看看这个数据框架,确保列的dtypes在内部被正确识别。
print(f'{df} \n\n'); df.info()
输出
int uint8 float bool string categorical
0 1000 0 <NA> True hello 1000
1 2 128 2.5 <NA> 2
2 300 255 <NA> False <NA> 300
3 <NA> 25 10.0 True always TDD. <NA>
<class 'cudf.core.dataframe.DataFrame'>
RangeIndex: 4 entries, 0 to 3
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 int 3 non-null int64
1 uint8 4 non-null uint8
2 float 2 non-null float64
3 bool 3 non-null bool
4 string 3 non-null object
5 categorical 3 non-null category
dtypes: bool(1), category(1), float64(1), int64(1), object(1), uint8(1)
memory usage: 393.0+ bytes
现在,我们创建数据框架交换协议对象来检查基本信息,如行数、列名和dtypes是否准确。
dfo = df.__dataframe__()
print(f'{dfo}: {dfo.num_rows()} rows\n')
print('Column\t Non-Null Count\t\t\t\t\t Dtype\n')
for n, c in zip(dfo.column_names(), dfo.get_columns()):
print(f'{n}\t\t {int(c.size - c.null_count)}\t\t{c.dtype}')
输出
<cudf.core.df_protocol._CuDFDataFrame object at 0x7f3edee0d8e0>: 4 rows
Column Non-Null Count Dtype
int 3 (<_DtypeKind.INT: 0>, 64, '<i8', '=')
uint8 4 (<_DtypeKind.UINT: 1>, 8, '|u1', '|')
float 2 (<_DtypeKind.FLOAT: 2>, 64, '<f8', '=')
bool 3 (<_DtypeKind.BOOL: 20>, 8, '|b1', '|')
string 3 (<_DtypeKind.STRING: 21>, 8, 'u', '=')
categorical 3 (<_DtypeKind.CATEGORICAL: 23>, 8, '|u1', '=')
缓冲区情况如何?我们将检查那些 "float "列。
fcol = dfo.get_column_by_name('float')
buffers = fcol.get_buffers()
for k in buffers:
print(f'{k}: {buffers[k]}\n')
输出
data: (CuDFBuffer({'bufsize': 32, 'ptr': 140704936368128, 'dlpack': <capsule object "dltensor" at 0x7ff893505e40>, 'device': 'CUDA'}), (<_DtypeKind.FLOAT: 2>, 64, '<f8', '='))
validity: (CuDFBuffer({'bufsize': 512, 'ptr': 140704936365568, 'dlpack': <capsule object "dltensor" at 0x7ff893505e40>, 'device': 'CUDA'}), (<_DtypeKind.UINT: 1>, 8, 'C', '='))
offsets: None
我们可以注意到来自数据缓冲区的列dtype<_DtypeKind.FLOAT: 2> 和有效性掩码的dtype,这里总是<_DtypeKind.UINT: 1> 。最后没有offset 缓冲区,因为它被保留给可变长度的数据,如字符串。
让我们使用[DLPack协议]从缓冲区中检索数据和有效性数组,并与列本身进行比较。
data_buffer = fcol.get_buffers()['data'][0]
validity_buffer = fcol.get_buffers()['validity'][0]
data = cp.fromDlpack(data_buffer.__dlpack__())
validity = cp.fromDlpack(validity_buffer.__dlpack__())
print(f'column: {df.float}')
print(f'data: {data}')
print(f'validity: {validity}')
输出
float column
0 <NA>
1 2.5
2 <NA>
3 10.0
Name: float, dtype: float64
data: [ 0. 2.5 0. 10. ]
validity: [0 1 0 1]
比较float列和数据,我们看到除了列中的<NA> 与数据数组中的0 对应外,其他的值都很相似。事实上,在缓冲区层面,我们用一个 "哨兵值 "来编码缺失值,这里的哨兵值是0。这就是有效性数组发挥作用的地方。与数据数组一起,我们能够在缺失值的确切位置重建该列。怎么做到的?有效性数组中的0表示数据中缺失值的位置或索引,1表示有效/不缺失的值。所有这些工作都是由一个辅助函数_from_dataframe ,它从一个数据框架交换对象中建立起整个cuDF数据框架。
from cudf.core.df_protocol import _from_dataframe
df_rebuilt = _from_dataframe(dfo)
print(f'rebuilt df\n----------\n{df_rebuilt}\n')
print(f'df\n--\n{df}')
输出
rebuilt df
----------
int uint8 float bool string categorical
0 1000 0 <NA> True hello 1000
1 2 128 2.5 <NA> 2
2 300 255 <NA> False <NA> 300
3 <NA> 25 10.0 True always TDD. <NA>
df
--
int uint8 float bool string categorical
0 1000 0 <NA> True hello 1000
1 2 128 2.5 <NA> 2
2 300 255 <NA> False <NA> 300
3 <NA> 25 10.0 True always TDD. <NA>
我们刚刚经历了一个从cuDF数据框架到数据框架交换对象的往返演示。然后我们看到了如何从数据框架交换对象中建立一个cuDF数据框架对象。在这一过程中,我们检查了数据的完整性。
学到的经验
多样性优势
许多研究表明,多样化团队的好处和更好的性能。我在这个项目中的经验是 CONTRIBUTING.md(旧版本)的文件,对我这个新人来说非常不清楚。根据我的导师(Kshiteej Kalambarkar和Ralf Gommers)的建议,我开了一个问题,分享了我的想法,并不断要求澄清,最后形成了一个(合并的)PR,重组了 CONTRIBUTING.md(当前版本)文件,使其更加清晰。
因此,水平的多样性(专家、新人等......)确保了一个包容性的环境,每个人都能轻松找到自己的方向。
