

Postgresql数据库,像其他数据库一样,可以存储数据,并在很长一段时间内保持不变。这可以通过保持存在的数据的并发性和准确性来消除模式中的数据冗余。在关系中添加数据时,你可能会遇到这样的情况,即在插入时没有注意到所插入数据的复制情况。为了清除垃圾值或类似的数据,我们需要一些特殊的函数来保持其余的值的唯一性和差异性。Count()是PostgreSQL的一个内置函数。通过使用这个函数,我们可以获得关于表中存在的数据的信息。Postgresql通过将数据显示在所提供的条件下,非常有效地处理计数()。为了获得不同的数据或与其他数据的区别值,我们需要一些不同的命令和count()。本文将强调应用在不同关系上的例子,以阐述PostgreSQL中计算唯一值的概念。
首先,你需要在已安装的PostgreSQL中创建一个数据库。否则,Postgres是在你启动数据库时默认创建的数据库。我们将使用psql来开始执行。你可以使用pgAdmin。
通过使用创建命令,创建一个名为 "items "的表。
>> create table items ( id integer, name varchar(10), category varchar(10), order_no integer, address varchar(10), expire_month varchar(10));

为了在表中输入数值,使用了一个插入语句。
>> insert into items values (7, ‘sweater’, ‘clothes’, 8, ‘Lahore’);

通过插入语句插入所有数据后,现在你可以通过选择语句获取所有记录。
>> select * from items;
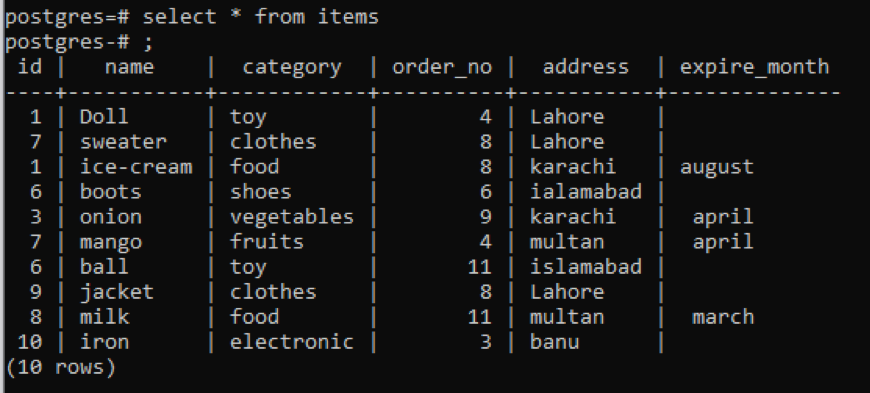
例1
这个表,你可以从快照中看到,每一列都有一些类似的数据。为了区分那些不常见的值,我们将应用 "distinct "命令。这个查询将以一个单列作为参数,该列的值将被提取出来。我们希望使用表的第一列作为查询的输入。
>> select distinct (id) from items order by id;

从输出结果来看,你可以看到总行数为7,而该表总共有10行,这意味着有些行被扣除了。所有在 "id "列中重复了两次或更多的数字都只显示一次,以区别于其他的结果表。通过使用 "order子句",所有的结果都按升序排列。
例2
这个例子与子查询有关,在子查询中使用了一个distinct关键字。主查询从子查询得到的内容中选择order_no是主查询的输入。
>> select order_no from (select distinct ( order_no) from items order by order_no) as foo;
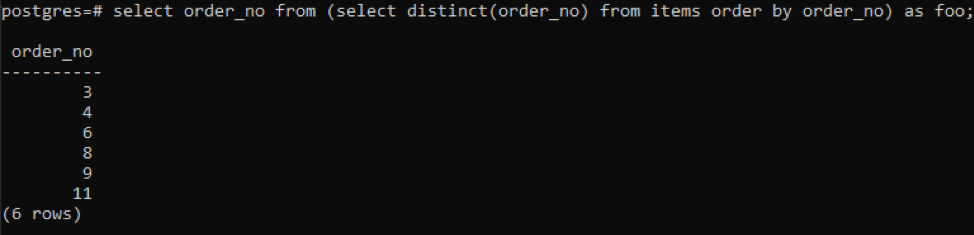
子查询将获取所有唯一的订单号;即使是重复的订单号也会显示一次。 同样的列order_no再次对结果进行排序。在查询的最后,你已经注意到使用了'foo'。这是个占位符,用来存储可以根据给定条件改变的值。你也可以尝试不使用它。但是为了保证正确性,我们使用了这个。
例3
为了得到不同的值,我们在这里使用了另一种方法。"distinct "关键字与函数count()和 "group by "子句一起使用。这里我们选择了一个名为 "地址 "的列。count函数对通过distinct函数获得的地址列中的值进行计数。除了查询结果外,如果我们随机想到要计算分明值,我们将得到每项的单一值。因为正如其名称所表明的,distinct将带来一个值,要么它们是以数字形式存在的。同样地,count函数将只显示一个单一的值。
>> select address, count ( distinct(address)) from items group by address;
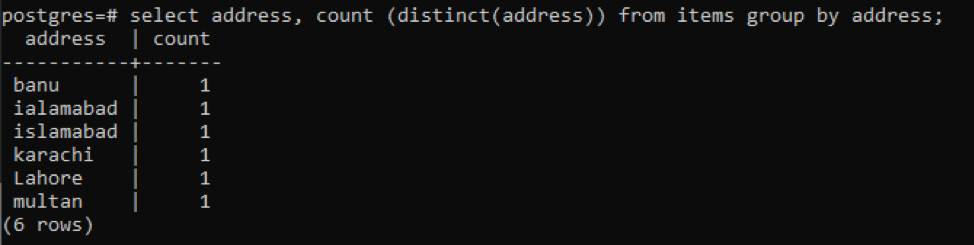
每个地址都被算作一个数字,因为有不同的值。
例4
一个简单的 "group by "函数决定了两列的不同值。条件是你为查询选择的显示内容的列必须在 "group by "子句中使用,因为没有这个条件,查询将不能正常工作。
>> select id, category from items group by category, id order by 1;
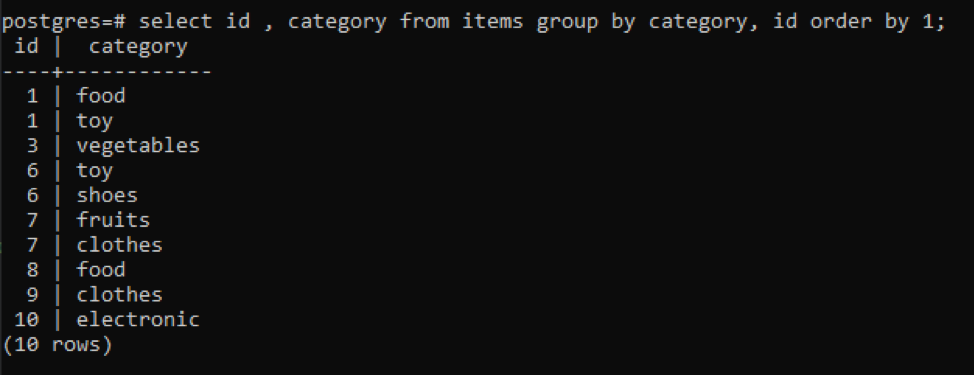
所有的结果值都是按升序排列的。
例5
再一次考虑同一个表,并对其进行一些改动。我们添加了一个新的层来应用一些约束。
>> select * from items;

在这个例子中,同样的group by和order by条款被应用于两列。Id和order_no被选中,并且都被group by和order by 1排序。
>> select id, order_no from items group by id, order_no order by 1;
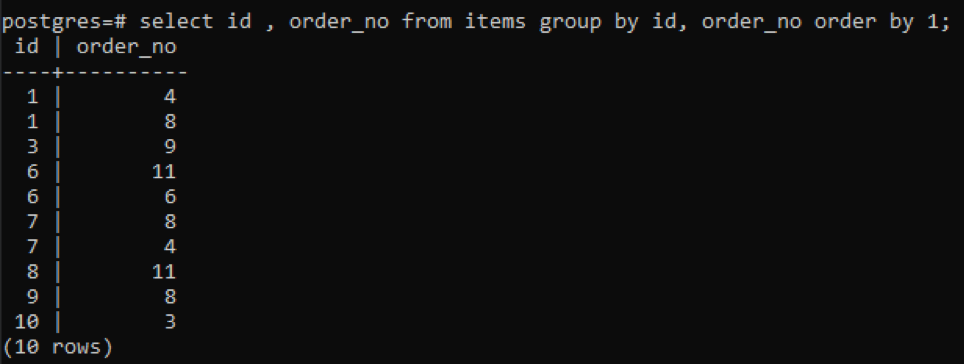
由于每个id都有不同的订单号,除了一个新增加的数字 "10",所有其他在表中有两次或更多存在的数字都同时显示。例如,"1 "的ID有订单号4和8,所以这两个数字被分别提及。但是在 "10 "的情况下,它被写了一次,因为它的id和order_no都是一样的。
例6 我们使用了上面提到的带有计数功能的查询。这将形成一个额外的列,用结果值来显示计数值。这个值是 "id "和 "order_no "相同的次数。
>> select id, order_no, count(*) from items group by id, order_no order by 1;
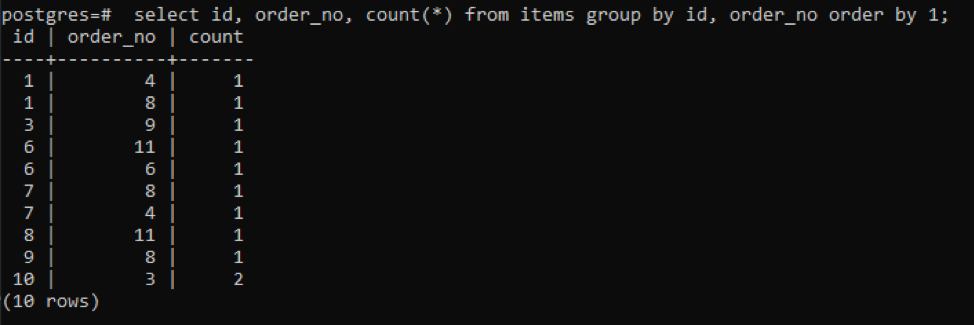
输出结果显示,每一行的计数值都是 "1",因为除了最后一行之外,这两行都有一个彼此不同的数值。
例7
这个例子几乎使用了所有的子句。例如,使用了select子句、group by子句、having子句、order by子句和一个计数函数。使用 "有 "子句,我们也可以得到重复的值,但是我们在这里用count函数应用了一个条件。
>> select order_no from items group by order_no having count (order_no) > 1 order by 1;

只有一列被选中。首先,与其他行不同的order_no的值被选中,然后对其应用计数函数。计数函数后得到的结果是按升序排列的。然后将所有的值与值 "1 "进行比较。那些大于1的列的值被显示出来。这就是为什么从11行中,我们只得到4行。
结论
"我如何在PostgreSQL中计算唯一值 "比简单的计数函数有单独的工作,因为它可以与不同的子句一起使用。为了获取具有唯一值的记录,我们使用了许多约束条件以及计数和唯一函数。这篇文章将引导你了解计算关系中唯一值的概念。
