SQL Optimizer | 青训营笔记
这是我参与「第四届青训营 」笔记创作活动的的第1天
1. Big Data and SQL
- Big Data System - One SQL rules big data all
- SQL processing flow
-

- Parser (Content of Compiler, details can see Compiler)
- String → AST (abstract syntax tree)
- Lexical Analysis
- verify that the input character sequence is lexically valid.
- group characters into sequence of lexical symbols, i.e., tokens.
- discard white space and comments (typically).
- Syntactic Analysis
- verify that the input program is syntactically valid, i.e., conforms to the Context Free Grammer of the language.
- determine the program structure.
- construct a representation of the program reflecting that structure without unnecessary details, usually an Abstract Syntax Tree (AST).
- Implementation: Recursion (ClickHouse), Flex and Bison (PostgreSQL), JavaCC (Flink), Antlr (Presto, Spark)
- Analyzer and Logical Plan
- Analyzer
- Check and bind metadata of Database, Table, Column, etc.
- Check SQL Legality, e.g., the input of min/max/avg is numerical value
- AST → Logical Plan
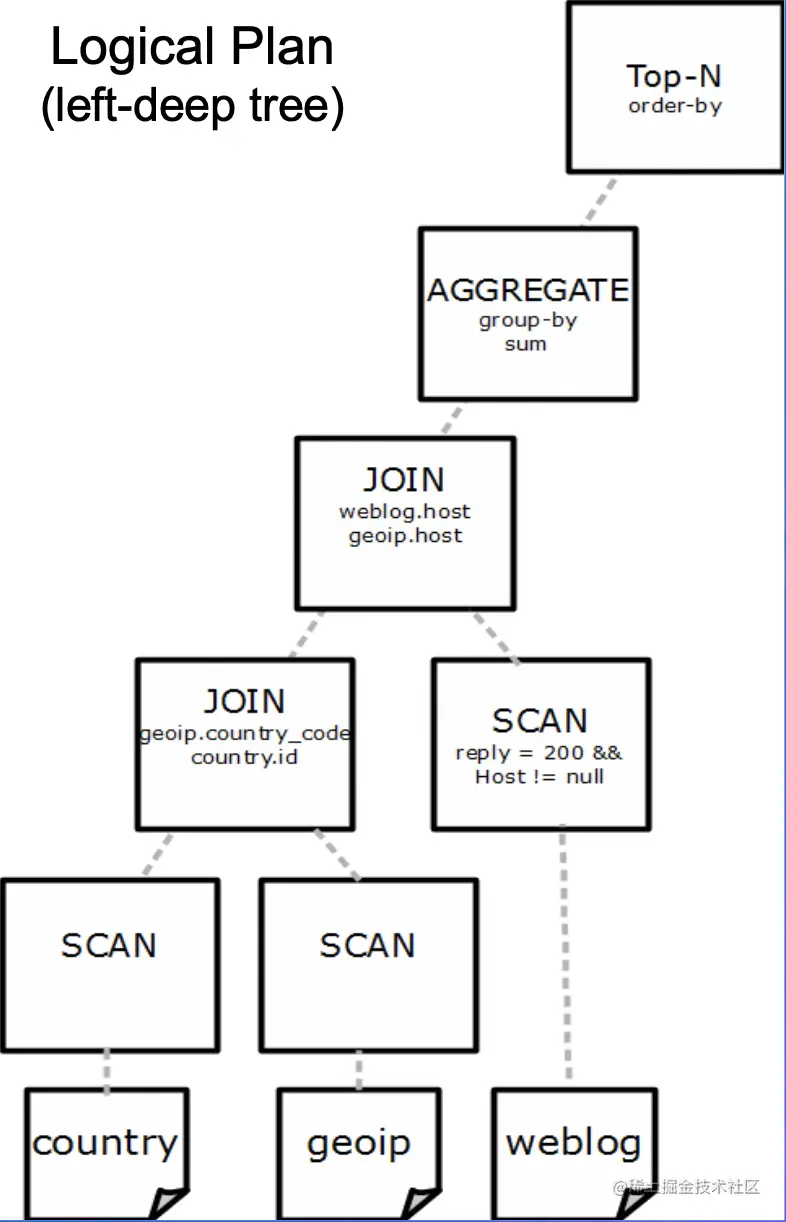
- Logical Plan
- Logically describe SQL corresponding to the step-by-step calculation operation
- Operator
- e.g.
 →
→ 
- Query Optimizer
- SQL is a declarative language, where the user only describes what to do, and does not tell the database how to do it
- Objective: To find a correct physical execution plan with minimal execution cost
- The query optimizer is the brain of the database, the most complex module, and many of the related problems are NP
- Generally the more complex the SQL, the more tables in the join and the larger the data volume, the more significant the query optimisation will be, as the performance difference between the different execution methods can be hundreds of times greater
- Physical Plan and Executor
- Plan Fragment: Execution plan subtree
- Objective: Minimising network data transfer
- Exploiting the physical distribution of data (data affinity)
- Increase shuffle operater
- Executor
- Single machine parallelism: cache, pipeline, SIMD
- Multi-machine parallelism: one fragment for multiple instances
2. Common Optimizers
- Optimizer classification
- Criteria 1
- Top-down Optimizer
- Starting from the target output, traverse the plan tree from top to bottom to find the complete optimal execution plan
- Example: Volcano/Cascade, SQLServer
- Bottom-up Optimizer
- Traverse the plan tree from bottom to top to find the complete execution plan
- Example: System R, PostgreSQL, IBM DB2
- Criteria 2
- Rule-based Optimizer (RBO)
- Rewriting queries based on relational algebraic equivalence semantics
- Based on heuristic rules
- Will access the table metadata (catalog), will not involve specific table data
- Cost-based Optimizer (CBO)
- Use a model to estimate the cost of the execution plan and select the least costly execution plan
- RBO
- Relational algebra
- Pinciple of closure
- Relations are closed under the algebra
- Relations after (nested) relational algebra operations are still relations.
- Five fundamental operations
- Selection (σ, 'sigma', unary)
- Projection (π, 'pi', unary)
- Union (⋃, binary)
- Cartesion Product, (×, binary)
- Set Difference, (−, binary)
- Others can be expressed as combination of the five.
- Theta Join (⋈F, R⋈FS=σF(R×S))
- Intersection (⋂, R⋂S=R−(R−S))
- division (÷)
- aggregation (AL(R))
- grouping (GA AL(R))
- Rename Operator (ρ, rho)
- Equivalent transformation: Associative law, Transitivity......
- Optimization principles
- Read data less and faster (I/O)
- Transfer data and less and faster (Network)
- Process data less and faster (CPU & Memory)
- ColumnPruning
- For columns that are not actually used in the operator, it is not necessary for the optimizer to keep them during the optimization process
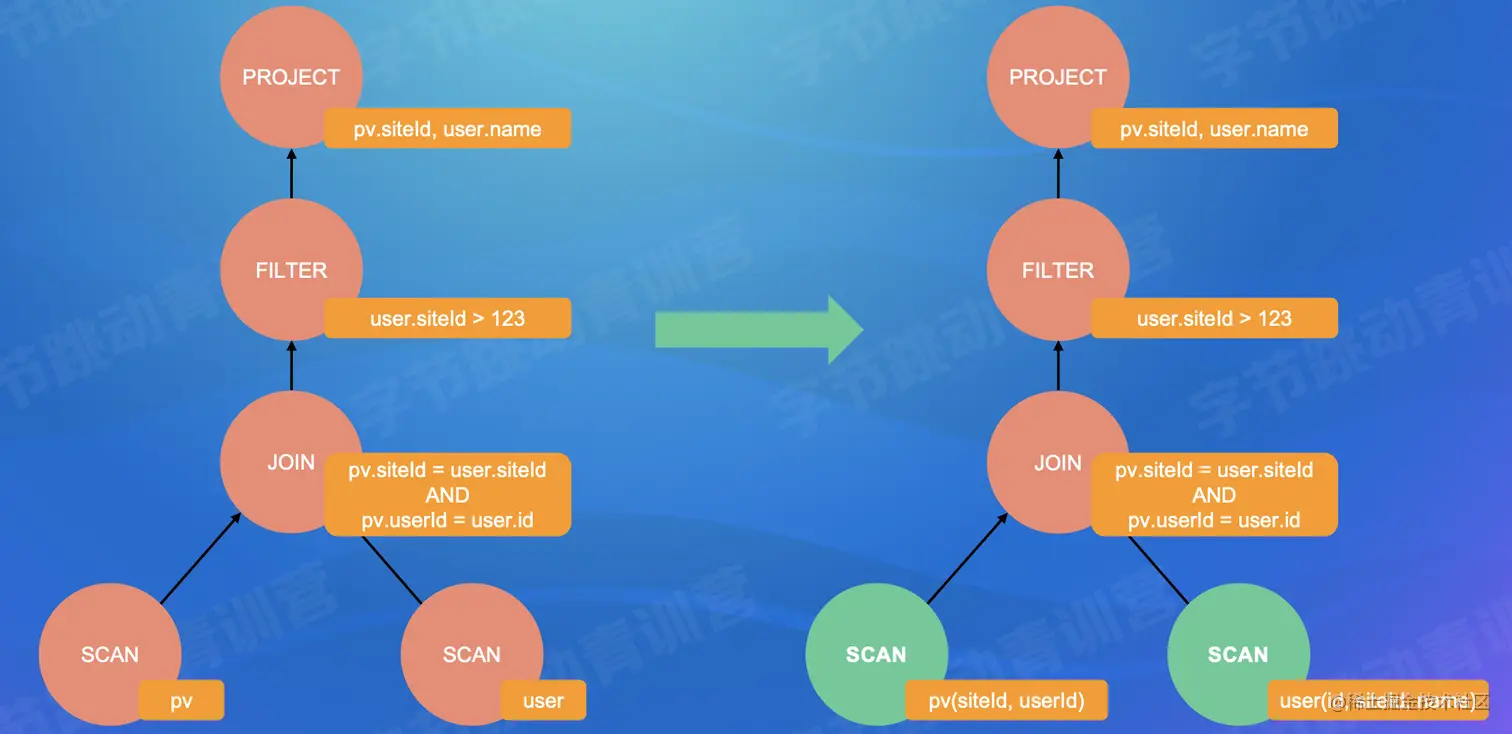
- Predicate Pushdown(PPD)
- Move the filter expression as close to the data source as possible so that extraneous data can be skipped directly when it is actually executed.
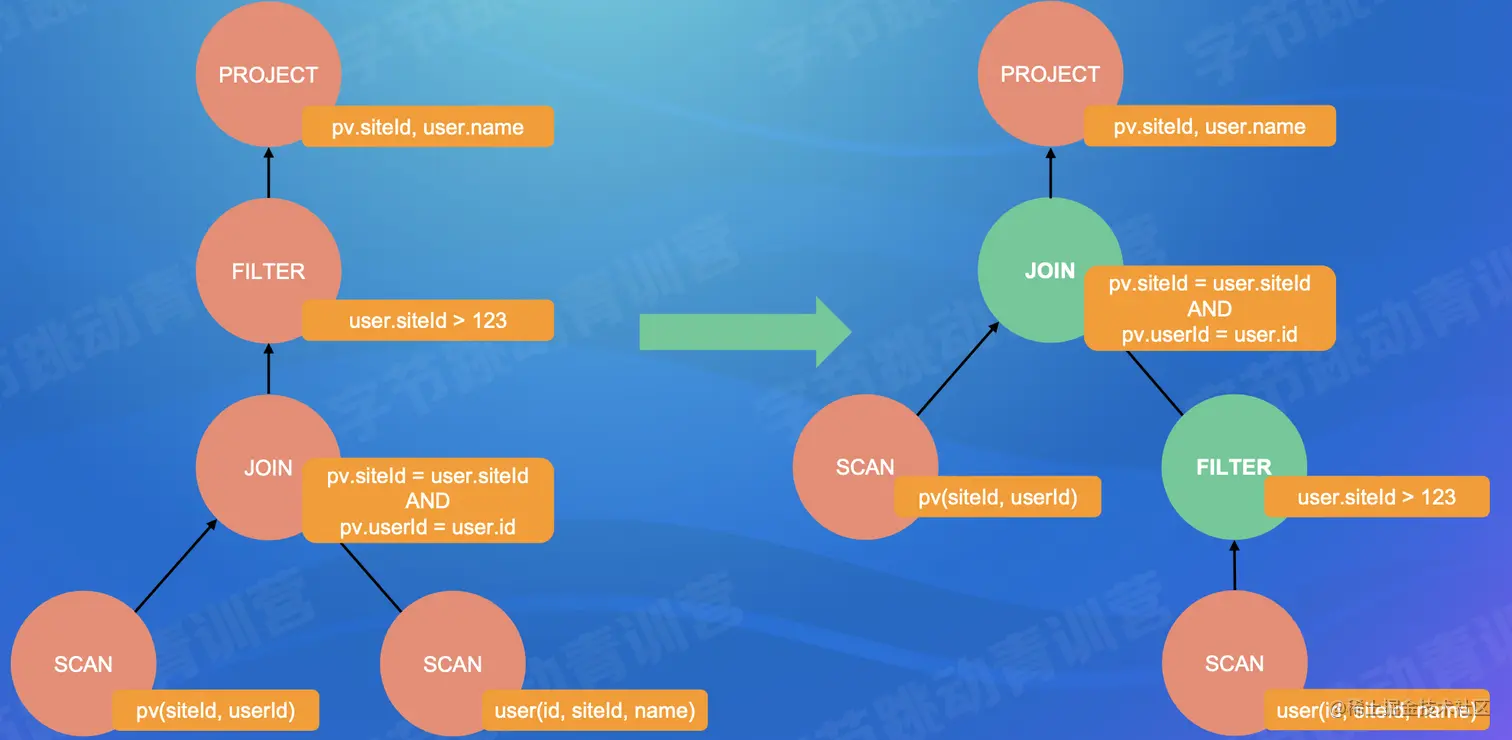
- Transitive closure
- Runtime Filter
- Dramatically reduce the data transfer and computation in joins by filtering out the input data that will not hit the join in advance on the join's probe side, thus reducing the overall execution time
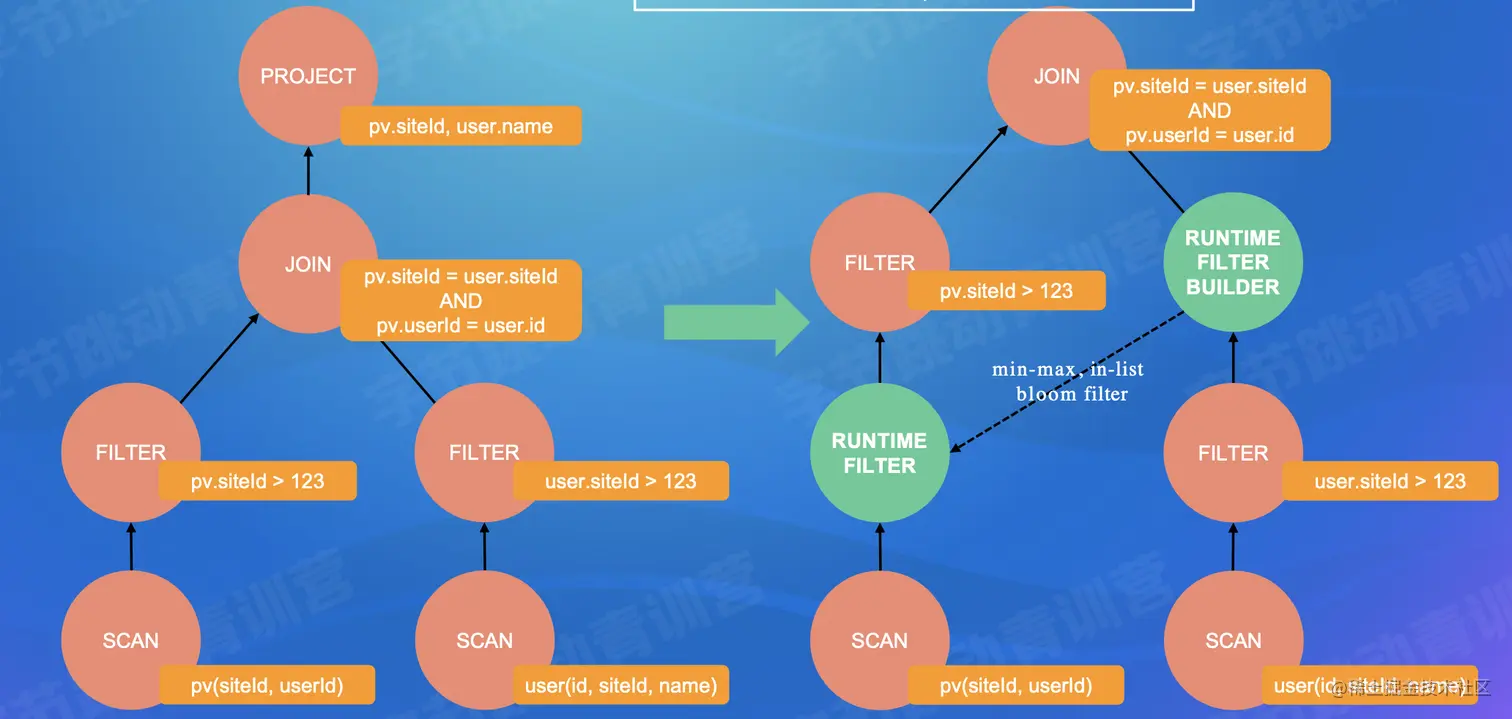
- Summary
- Mainstream RBO implementations generally have hundreds of optimization rules based on empirical induction
- Pros: Easy to implement, fast to optimize
- Cons: No guarantee of an optimal execution plan
- CBO
- Concept:
- Use a model to estimate the cost of the execution plan and select the least costly execution plan
- The cost of executing the plan is equal to the sum of the operator costs of all operators
- Get (all) possible equivalent execution plans via RBO
- Operator cost: CPU, Memory, Disk I/O, Network I/O, etc.
- Related to the statistics of the operator input data: Number of rows of input and output results, size per row
- Leaf Operator Scan: the raw statistics gives
- Middle Operator: According to certain derivation rules, the statistics from the lower level operator is obtained
- Related to the specific type of operator, and the physical implementation of the operator
- E.g., Spark Join operator cost = weight * (row_count) + (1.0 - weight) * size

- Statistics
- Raw table statistics
- Table or partition level: number of rows, average row size, how many bytes the table uses on disk, etc.
- Column level: min, max, num nulls, num not nulls, num distinct value (NDV), histogram, etc.
- Derived statistics
- Selectivity: What percentage of data will be returned from the table by the query for a particular filter condition
- Cardinality: In the query plan it often refers to the number of rows the operator needs to process
- Collection Methods
- Specify the statistics to be collected in the DDL (Data Definition Language), and the database will collect or update to when the data is written

- Manually execute explain analyse statement to trigger the database to collect or update statistics

- Dynamic sampling

- Rules for derivation of statistics (Assume that the columns are independent from each other and that the values of the columns are uniformly distributed)
- Filter Selectivity
- AND: fs(a AND b) = fs(a) * fs(b)
- OR: fs(a OR B) = fs(a) + fs(b) - fs(a) * fs(b)
- NOT: fs(NOT a) = 1.0 - fs(a)
- x = literal
- literal < min && literal > max: 0
- 1/NDV
- x < literal
- literal < min: 0
- literal > max: 1
- (literal - min) / (max - min)
- Execution Plan Enumeration
- Single Table Scan: Index Scan (Stochastic I/O) vs. Full Table Scan (Sequential I/O)
- If the query has a very uneven data distribution, an index scan may not be as good as a full table scan
- Implementation of Join: Hash join vs. SortMerge join
- Two tables Hash join: Building hash tables with small table - how to find smaller table
- Multi-table join:
- Which join order is optimal?
- The optimal execution plan is usually selected using a greedy algorithm or dynamic programming


