

这是我参与「第四届青训营 」笔记创作活动的第2天
本次笔记重点内容
-
- 查询优化器的社区开源实践
-
- SQL 相关的前沿趋势
社区开源实践概览: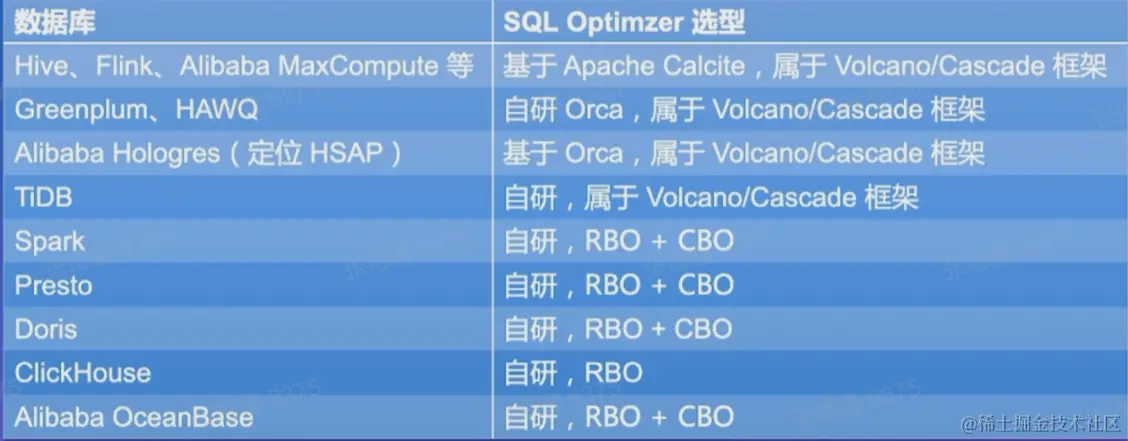
举例:Apache Calcite
——一种优化器,用来解析sql,具有模块化和插件化的优点,稳定可靠,可以对接不同的处理系统
JDBC Client是用来接受sql的一个客户端,Calcite作用主要是黑色框里的部分,sql进来后接受JDBC Server处理,到SQL Parser and Validator进行检验与解析,把抽象语法树转换成关系表达式,注意旁边的Expressions Builder可以不经过语法解析直接构建出关系表达式,接下来Query Optimizer要去Metadata Providers那拿信息,下方的Pluggable Rules同时定义了一个插件化RBO规则,各个系统通过它去实现更多适用于系统的优化规则。
Calcite RBO
HepPlanner
遍历表达式子树,匹配规则进行等价替换,得到新的表达式,循环到所有rule都匹配完,优化速度快,但是由于RBO都是基于经验的规则,所以没法保证最优。
Calcite CBO
VolcanoPlanner
基于Volcano/Cascade框架(没有具体代码,只是描述优化器如何实现),要求整个执行计划的最优假设,可以先求子问题的。有一个数据结构Memo(AND/OR graph),记录求解问题的最优解,其数据结构如下:Group为等价计划集合(相当于每一个树子节点),如Group4中的3&2表示Group3和Group2这两个子树。其好处是共享子树减少内存开销。
为什么说是AND/OR graph?G4->G3->G2->G1如这样一条线路中,它们之间就是AND的关系,再如G3这个Group里面Filter和New Project就是OR的关系。
我们会发现每一个Group还有一个best即目前的最优计划的记录,方便最后结算最优代价。
sql前沿趋势
- 存储计算分离,不要在一个节点同时进行存储和计算,各自分开进行,利于单独扩容,再者事务型和分析型数据合并,不需要两个系统来存储,成本降低
- 云原生,可以动态调整规模,流量少时缩减计算节点,流量大时扩充
- 数据仓库(预先定义模型处理原始数据,把关联好的数据存进来,但是源数据丢失,业务又不清楚你的模型),数据湖(原始数据的保存),把它们结合起来用同一个sql数据接口查询,达到井井有条
- AI跟数据库和查询优化器的结合:自动调参,预测高峰期扩容,自动诊断问题并恢复
小结
SQL其实是对用户更为友好的一种声明式语言,但其还有有待改进的地方,例如在某些特殊情况下,一段 SQL语句往往在成本和产出之间无法达到最优,往往需要在外界介入的指示下才能够提升数据库查询性能。而在现在的数据支配的世界中,数据量之变幻莫测谁都不能预测,大大加大了难度,希望在未来,对于程序处理的优化,每个系统都能不断自主的学习当前的数据特征,深刻了解程序的情况,进而有一个更完美的优化方案的实现!
