

简介
在FP Complete,我们为客户开发了许多工具,以帮助他们实现其目标。这些工具大多是用Haskell编写的(最近还有一些是用Rust编写的),这有助于我们更快速地编写这些工具,并在未来产生更多可维护的应用程序。
在这篇文章中,我想描述其中的一个工具,任何拥有SQL服务器的现有或遗留数据库的人或公司都应该感兴趣。
一个客户正在从SQL Server全面迁移到PostgreSQL,然而,像许多大公司一样,他们有许多数据库分布在全国各地的不同服务器上,并由不同部门的许多人使用。要简单地替换一个很多人都在直接使用的数据库并不那么容易。他们仍然希望为他们的各个部门提供一个SQL Server的查询界面,所以他们问我们是否可以开发一个独立的服务,可以假装是SQL Server,但实际上在幕后与任何JSON服务对话。我们做到了!本文将介绍它是如何完成的。
需求和架构
该系统的高层架构是这样的:
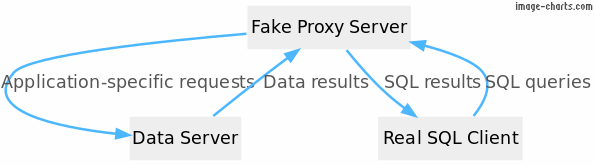
要求:
- 该服务应该接受并理解最小的SQL(即告诉我查询哪个 "表",也许还有一个微不足道的
WHERE子句)。 - 它应该查询一些提供真正数据库的后台JSON/网络服务。
- 它应该正确地返回表格式的结果。
- 服务器必须要有内存效率,因此必须是流式的。
- 它应该用Haskell编写,以便客户可以维护它。
因此,系统的用户会写一个普通的SQL服务器查询,比如SELECT * FROM "customer" ,然后被发送到一个假的SQL服务器,而这个服务器又会查询真正的后台服务,不管那是什么,并把结果返回给用户。
方法
为了实现一个假的SQL服务器,我们需要:
- 一个服务器程序,接受来自客户端的连接,并谈论他们的语言。
- 一个客户程序,它是一个真实的SQL Server客户,我们可以用它来测试我们的服务器。
我研究了SQL Server和它的客户端所使用的协议。它被称为TDS,意思是 "表格式数据流"。它最初是由Sybase公司在1984年为其Sybase SQL Server关系数据库引擎设计和开发的。后来,它被微软公司采用,用于Microsoft SQL Server。就二进制协议而言,它是一个相当直接的二进制协议。微软有TDS协议的文档,你可以在自己的时间里看一看。
关于客户端程序,今天在Linux或Mac OS X中访问微软的客户端库要容易得多,这要感谢他们发布的ODBC包。你现在可以在Linux和macOS上得到它了!我也很惊讶!这使得为我们的服务器写一个测试套件变得很容易。
TDS如何工作
TDS是一个二进制协议。通信是通过消息来完成的,每个消息都是一个所谓的数据包序列,每个数据包由一个头和(通常,但不总是)一个有效载荷组成。
数据包
头部有8个字节,由下表描述。我已经划掉了我们不使用的部分。
标头
| 字段 | 类型 | 描述 |
|---|---|---|
| 类型 | 字8 | 不被我们使用 |
| 状态 | 字8 | 0=正常信息,1=信息结束 |
| 长度 | 字16 | 数据包的长度,大殷商 |
| 识别码 | 字16 | 不被我们使用 |
| 数据包 | 字8 | 不被我们使用,被SQL服务器忽略 |
| 窗口 | 字8 | 不使用,应该被忽略 |
事实证明,我们只需要status 和length 字段!
Status告诉我们在这个请求中是否有更多的数据包,或者这是否是最后一个。Length告诉我们整个数据包的长度,包括头本身。
一个典型的场景:
- TDS协议以一个从客户端到服务器的称为预登录的消息开始。在预登录中,你可以指定你是否要启用联合认证或加密。在我们的案例中,我们不支持联合登录,因为反正没有一个客户在使用它。我们也不支持加密。
- 客户端可以请求或要求打开该功能,或者说它根本不支持加密。利用这些信息,服务器协商是否启用加密功能,在我们的案例中,加密功能被完全关闭。
- 如果服务器对预登录信息感到满意,服务器应该发回一个预登录响应。之后,服务器应该预计到登录请求,这将包括登录细节,如用户名和密码。
- 一旦进行了协商,我们就可以进入交互循环,在这个循环中,服务器接受请求,处理请求并返回结果。
比如说:
- 一个简单的批量查询,包括一个SQL查询,并返回一个结果列表。
- 另一种类型的消息可以是一个RPC调用,SQL服务器使用它来执行函数来准备语句等等。
我们处理过这两种类型的消息,但我们在这篇文章中只看简单的批处理查询。
堆栈-专栏-中心
服务器架构
我的第二步是启动一个Haskell项目,并计划我将用于这项任务的库。
我使用了这些Haskell包:
- conduit-extra来创建一个监听多线程的 TCP 服务。
- conduit本身用于在服务器和客户端之间进行数据交换。
- attoparsec来解析TDS协议。
- bytestringbuilder,为TDS协议生成消息。
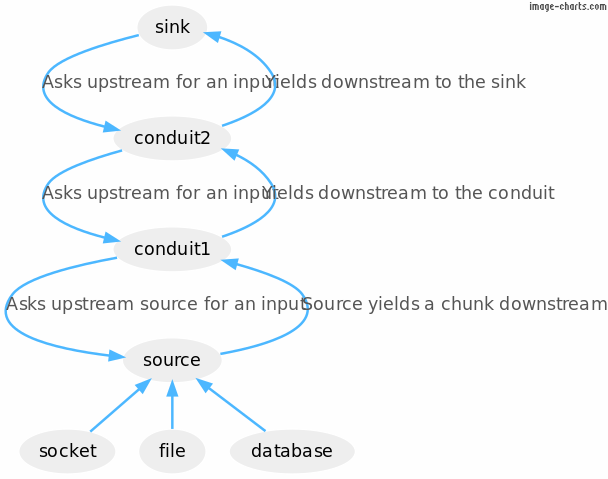
在图表中,该管道看起来像这样:

我们将详细看看每一个。
流处理:Conduit
Conduit是用来实现流处理的。其他语言如Rust称这些迭代器,或者在Python中它们被称为生成器(数据生产者)和coroutines(数据消费者)。在Haskell中,它被实现为一个普通的库。它是一个概念上简单的流媒体API,由两个真正的关键部分组成。
await- 停止你正在做的事情,等待流中的下一个数据块。yield- 向下游的await提供一个数据块。
我们在服务器中使用了这些东西,我用于这项任务的所有库也是如此。
考虑一下这个流水线的例子。
pipeline =
source .| conduit1 .| conduit2 .| sink
(注意:.| ,可以像UNIX管道一样阅读。)
源可能是一个套接字,一个文件或一个数据库。这三种I/O来源的块可以产生字节,或者例如来自数据库查询的行。在一个管道中,汇(管道中的最后一个东西)驱动计算,每次等待输入时都会在管道中产生多米诺骨牌效应,一直回到源头,源头咨询一些外部提供者(socket、文件或数据库)。
我使用了 conduit-extra,因为你可以用三行字就把一个监听服务组合起来。这看起来像这样:
#!/usr/bin/env stack
-- stack --resolver lts-12.12 script
{-# LANGUAGE OverloadedStrings #-}
import Data.Conduit.Network
import Conduit
main =
runTCPServer
(serverSettings 2019 "*")
(\app -> do
putStrLn "Someone connected!"
runConduit (appSource app .| mapMC print .| sinkNull)
putStrLn "They disconnected!"
pure ())
在这个例子中,来自套接字的源管道被输送到一个管道(mapMC print ),这个管道只是打印每个进来的块。最后,它被输送到sinkNull ,它消耗所有的输入并丢弃它。
运行它看起来像这样。
$ ./conduit-tcp-server.hs
Someone connected!
"hi\n"
They disconnected!
我们将逐步建立一个简单的服务器实例。
如果你想跟随并在你的电脑上运行这些Haskell例子,当你安装了stack ,它们可以方便地作为常规脚本运行。请查看我们的 "开始"页面,按照说明进行设置。
类型安全
Haskell中的大多数库都以类型安全为荣,像Conduit这样的流式库也不例外。让我们简单看看这个。这是一个导管的类型:
data ConduitT input output monad return
它意味着 "一个管道有一个input ,一个output ,运行在一些monad ,并且有一个最终的return "。
因此,例如,yield 有这种类型:
yield :: Monad m => input -> ConduitT input output monad ()
它产生一个下游的输入,并返回单位() 。
而await 则有这种类型:
await :: Monad m => ConduitT input output monad (Maybe output)
它等待来自上游的输出,并可能返回Just ,如果上游还有什么东西。否则,它返回Nothing 。
像map 和filter 这样的函数也有教育类型。
map :: Monad m => (input -> output) -> ConduitT input output monad ()
filter :: Monad m => (input -> Bool) -> ConduitT input input monad ()
最后,把它们插在一起必须要有正确的类型。
filter (> 5) .| map show .| filter (=/ "6") .| ...
这让我们可以像乐高积木一样把碎片插在一起,确信我们的组成是正确的。输入、输出和返回都必须匹配起来。
增量解析:attoparsec
我使用attoparsec来解析二进制协议。attoparsec是一个解析器组合库,支持对输入的不完全解析,即分块解析数据。
下面是一个简单的、封闭的例子。
#!/usr/bin/env stack
-- stack --resolver lts-12.12 script
{-# LANGUAGE OverloadedStrings #-}
import qualified Data.ByteString as S
import qualified Data.Attoparsec.ByteString as P
main =
case P.parseOnly myparser (S.pack [2, 97, 98]) of
Right result -> print result
Left err -> putStrLn err
where
myparser = do
len <- P.anyWord8
bytes <- P.take (fromIntegral len)
return bytes
其中输出的内容如下。
$ ./attoparsec-example.hs
"ab"
如果我创建一个流媒体程序,像这样把一个字节的块送入解析器。
#!/usr/bin/env stack
-- stack --resolver lts-12.12 script
{-# LANGUAGE OverloadedStrings #-}
import qualified Data.ByteString as S
import qualified Data.Attoparsec.ByteString as P
main = loop (P.parse myparser) (S.pack [2, 97, 98])
where
loop eater input =
do putStrLn ("Chunk " ++ show (S.unpack chunk))
case eater chunk of
P.Done _ value -> print value
P.Fail _ _ err -> putStrLn err
P.Partial next -> do
putStrLn "Waiting for more ..."
loop next remaining
where (chunk, remaining) = S.splitAt 1 input
myparser = do
len <- P.anyWord8
bytes <- P.take (fromIntegral len)
return bytes
我们创建一个带有 "食客 "的循环。这个吃货吃的是字节块。它要么产生一个完成/失败的结果,要么产生下一个准备吃下一个块的吃者。
输出是:
$ ./attoparsec-feeding.hs
Chunk [2]
Waiting for more ...
Chunk [97]
Waiting for more ...
Chunk [98]
"ab"
然而,请注意,myparser 并没有改变。它并不关心输入是如何分块的。它很有耐心。最终的结果是一样的。这在 conduit 中工作得非常好,自然, conduit 与来自 conduit-extra 包的 attoparsec 集成。
上面的代码可以在 conduit 中重写为:
#!/usr/bin/env stack
-- stack --resolver lts-12.12 script
{-# LANGUAGE OverloadedStrings #-}
import qualified Data.ByteString as S
import qualified Data.Attoparsec.ByteString as P
import Conduit
import Data.Conduit.List
import Data.Conduit.Attoparsec
main = do
result <- runConduit (sourceList chunks .| sinkParserEither myparser)
case result of
Left err -> print err
Right val -> print val
where
chunks = [S.pack [2], S.pack [97], S.pack [98]]
myparser = do
len <- P.anyWord8
bytes <- P.take (fromIntegral len)
return bytes
生产:
$ ./attoparsec-conduit.hs
"ab"
看看这个例子和上面的例子,很容易想象到sinkParserEither 是如何运作的。它从上游消耗块,并递增地将其送入myparser ,直到发生结果。
高效的二进制写作:字节串联
最后,为了生成TDS协议的消息,我可以使用bytestring Builder抽象有效地生成二进制流。从本质上讲,这个抽象让你在缓冲区中插入字节串,它们被有效地追加。此外,这些字符串可以以流的方式增量写入套接字或文件,因此也很节省内存。
具体到我们的用例,它使输出涉及word8、word16的二进制格式变得微不足道,并且很容易区分little-endian和big-endian编码。
例如,为了建立我们上面的例子,我们会使用<> ,将各块内容组合在一起。
#!/usr/bin/env stack
-- stack --resolver lts-12.12 script
{-# LANGUAGE OverloadedStrings #-}
import qualified Data.ByteString.Lazy as L
import qualified Data.ByteString.Builder as BB
main = L.putStr (BB.toLazyByteString (BB.word8 2 <> "ab"))
$ ./builder-example.hs
ab
或者可以把它写成一个管道:
#!/usr/bin/env stack
-- stack --resolver lts-12.12 script
{-# LANGUAGE OverloadedStrings #-}
import System.IO
import Data.Conduit
import qualified Data.Conduit.List as CL
import qualified Data.Conduit.Binary as CB
import qualified Data.ByteString.Lazy as L
import qualified Data.Conduit.ByteString.Builder as CB
import qualified Data.ByteString.Builder as BB
main =
runConduitRes
(CL.sourceList [BB.word8 2 <> "ab"] .| CB.builderToByteString .|
CB.sinkHandle stdout)
也就是说,产生一个构建器的来源。把它送入一个管道,该管道将构建器转换为字节字符串流,然后把它送入一个写入stdout的汇中。
实现:解析器
考虑到所有这些,消息分析器看起来像这样
messageParser :: Parser (Packet ClientMessage)
messageParser = do
header <- headerParser
let payloadLength = fromIntegral (headerLength header - headerSize)
message <-
case headerType header of
0x01 -> sqlbatchParser payloadLength
0x12 -> preloginParser payloadLength
0x0E -> transactionParser
0x03 -> rpcParser payloadLength
0x10 -> loginParser
0x06 -> attentionParser
_ -> do
payload <- Atto.take payloadLength
pure (UnknownMessage payload)
pure (Packet header message)
例如,sqlbatchParser 是
sqlbatchParser :: Int -> Parser ClientMessage
sqlbatchParser messageLen = do
start <- parserPosition
_headers <- allHeadersParser
end <- parserPosition
text <- Atto.take (messageLen - (end - start))
pure (SQLBatchMessage (T.decodeUtf16LE text))
我们实际上忽略了头文件,只对SQL查询感兴趣。我们从流中抓取,并将其解码为UTF16 little-endian,这是TDS的指定文本格式。
一个例子是这样的,以十六进制编辑器的格式。
01 01 00 5C 00 00 01 00 . . . \ . . . .
16 00 00 00 12 00 00 00 . . . . . . . .
02 00 00 00 00 00 00 00 . . . . . . . .
00 01 00 00 00 00 0A 00 . . . . . . . .
73 00 65 00 6C 00 65 00 s . e . l . e .
63 00 74 00 20 00 27 00 c . t . . ' .
66 00 6F 00 6F 00 27 00 f . o . o . ' .
20 00 61 00 73 00 20 00 . a . s . .
27 00 62 00 61 00 72 00 ' . b . a . r .
27 00 0A 00 20 00 20 00 ' . . . . .
20 00 20 00 20 00 20 00 . . . .
20 00 20 00 . .
或者用表格格式:
| 部分 | 内容 | 意义 |
|---|---|---|
| 类型 | 01 | SQL批处理请求 |
| 状态 | 01 | 最后一个数据包 |
| 长度 | 00 5C | 92 |
| SPID | 00 00 | 0 |
| 数据包 | 01 | 1 |
| 窗口 | 00 | 0 |
| 标题 | 16 00 00 00 12 00 00 00 02 00 00 00 00 00 00 00 00 01 00 00 00 00 | 不重要 |
| SQL | 0a 00 73 00 65 00 6c 00 65 00 63 00 74 00 20 00 27 00 66 00 6f 00 6f 00 27 00 20 00 61 00 73 00 20 00 27 00 62 00 61 00 72 00 27 00 0a 00 20 00 20 00 20 00 20 00 20 00 20 00 20 00 20 00 20 00 20 00 20 00 20 00 20 00 00 | "\nselect 'foo' as 'bar'\n " |
其他解析器也遵循同样的模式。请记住,attoparsec中的所有内容都是增量的,所以我们不必担心边界和数据包被分散到多个块中。解析器被喂食,直到它被满足。
实施:渲染
碰巧的是,对于渲染对服务器的回复,实际上有三个服务器消息值得关注。发送登录接受、登录前确认和所谓的 "一般响应",这就是我们对返回查询结果感兴趣的目的。GeneralResponse 包括一个响应令牌的向量Vector ResponseToken 。但在本文中,我们只关注Row 。
data ResponseToken = ... | Row !(Vector Value)
具体来说,渲染一个响应令牌的实现是:
renderResponseToken :: ResponseToken -> Builder
renderResponseToken =
\case
...
Row vs -> word8 0xD1 <> foldMap renderValue (V.toList vs)
对于返回查询的行,我们有Value 。
data Value
= TextValue !Text
| BoolValue !Bool
| DoubleValue !Double
| Int32Value !Int32
| Int16Value !Int16
这很容易呈现为一个构建器:
renderValue :: Value -> Builder
renderValue =
\case
TextValue t -> word16LE (fromIntegral (T.length t * 2)) <> byteString (T.encodeUtf16LE t)
DoubleValue d -> doubleLE d
BoolValue b -> word8 (if b then 1 else 0)
Int16Value i -> int16LE i
Int32Value i -> int32LE i
还记得Builder 的属性吗?它逐步建立数据结构。向它请求数据块的管道将请求下一个数据块,并将其写入套接字。我们稍后会看一下服务器的内存使用情况,并确认它在行数上的O(1) 。
实施:渡过消息
为了处理一个连接,我们有两个管道:
- 一个是提供传入的流,也称为源。
- 一个是提供流出的流,也称为汇。
我们只需要在一个循环中消耗传入的流并对消息进行调度。让我们用我们一直在使用的简单例子来展示一个更容易消化的版本。
#!/usr/bin/env stack
-- stack --resolver lts-12.12 script
{-# LANGUAGE OverloadedStrings #-}
import Data.Conduit.Network
import qualified Data.ByteString as S
import qualified Data.Attoparsec.ByteString as P
import Conduit
import Data.Conduit.Attoparsec
main =
runTCPServer
(serverSettings 2019 "*")
(\app -> do
putStrLn "Someone connected!"
runConduit (appSource app .| conduitParserEither parser .| handlerSink app))
where
handlerSink app = do
mnext <- await
case mnext of
Nothing -> liftIO (putStrLn "Connection closed.")
Just eithermessage ->
case eithermessage of
Left err -> liftIO (print err)
Right (position, message) -> do
liftIO (print message)
liftIO (runConduit (yield "Thanks!\n" .| appSink app))
handlerSink app
parser = do
len <- P.anyWord8
bytes <- P.take (fromIntegral len)
return bytes
下面是正在发生的事情:
- 我们运行一个服务器,然后立即开始一个管道,从套接字中消耗块状信息。
- 我们用管道将这些块送入attoparsec解析器,产生
(Either ParseError (PositionRange, ByteString)),其中ByteString是我们想要的解析的东西。 - 我们将其送入我们的
handlerSink,它一次消费这些解析结果。 - 如果
await产生了Nothing,这就是流的结束。 - 如果
eithermessage是Left,那么我们就有一个解析错误。我们可能想在这里结束并打印错误。所以这就是我们所做的。 - 如果是
Right,那么我们就打印出信息,送回"Thanks",然后继续我们的汇流循环。
下面是行为的样子:
$ cat > writer.hs
main = putStr "\5Hello\5World"
chris@precision:~$ stack ghc -- writer.hs -o writer -v0
chris@precision:~$ ./writer | nc localhost 2019
Thanks!
Thanks!
C-c
服务器报告:
$ ./conduit-atto.hs
Someone connected!
"Hello"
"World"
Connection closed.
就像我们所期望的那样!假的SQL服务器的行为与此相同,但是使用了我们简单看过的数据包的解析器,以及我们也看过的渲染器。
值得花点时间来消化一下能够如此琐碎地处理二进制协议的成就。这要归功于attoparsec和 conduit提供的抽象概念。
测试机会
测试很容易,因为我们使用的是高级别抽象。conduit的处理代码与attoparsec的解析代码和渲染代码是解耦的。
- 你可以在测试套件中提供一个字节流,这些字节应该来自客户端。我们在上面用我们的
myparser剖析器探讨了这个问题。 - 你也可以将这些字节以不同的块的排列方式发送,以检查边界是否被正确处理。我们也通过向导管和attoparsec提供逐个字节的数据块来研究这个问题。
- 你可以测试随机输入和输出。
为了测试随机输出,我们可以实现QuickCheck的Arbitrary的一个实例。
instance Test.QuickCheck.Arbitrary Value where
arbitrary = oneof [text, int32, int16, double, bool]
where
text = (TextValue . T.pack) <$> Test.QuickCheck.arbitrary
bool = (BoolValue) <$> Test.QuickCheck.arbitrary
double = DoubleValue <$> Test.QuickCheck.arbitrary
int32 = Int32Value <$> Test.QuickCheck.arbitrary
int16 = Int16Value <$> Test.QuickCheck.arbitrary
的实例,为行列生成一个随机的Value 。
> Test.QuickCheck.generate (Test.QuickCheck.arbitrary :: Test.QuickCheck.Gen Value)
BoolValue True
> Test.QuickCheck.generate (Test.QuickCheck.arbitrary :: Test.QuickCheck.Gen Value)
Int16Value 10485
> Test.QuickCheck.generate (Test.QuickCheck.arbitrary :: Test.QuickCheck.Gen Value)
TextValue "2\130Fc\f\SI:r*^\228\185R|\239yk\246D0~\204Z\255d\138^P"
有了这个,我们就可以建立一个测试套件,生成一个值的向量,Vector Value ,运行我们的服务器,连接到它,提出请求,让服务器返回这个值的向量,然后检查ODBC库返回的行是否与我们希望服务器返回的一致。很简单!
探索内存的使用
让我们看一下这个服务器的内存使用情况。这是一个简单的服务器,它接受要产生的行数,并从一个CSV文件中读取这么多行。
{-# LANGUAGE OverloadedStrings #-}
{-# LANGUAGE TypeApplications #-}
import qualified Data.Map.Strict as M
import Data.Map.Strict (Map)
import Data.ByteString (ByteString)
import qualified Data.Conduit.List as CL
import Data.CSV.Conduit
import qualified Data.Conduit.Binary as CB
import Data.Conduit.Network
import qualified Data.Attoparsec.ByteString as P
import Conduit
import Data.Conduit.Attoparsec
main =
runTCPServer
(serverSettings 2019 "*")
(\app -> do
putStrLn "Someone connected!"
runConduit
(appSource app .| conduitParserEither parser .| handlerSink app))
where
handlerSink app = do
mnext <- await
case mnext of
Nothing -> liftIO (putStrLn "Connection closed.")
Just eithermessage ->
case eithermessage of
Left err -> liftIO (print err)
Right (position, lineCount) -> do
liftIO (print lineCount)
liftIO
(runConduitRes
(CB.sourceFile "fake-db.csv" .| intoCSV defCSVSettings .|
CL.mapMaybe
(M.lookup "Name" :: Map ByteString ByteString -> Maybe ByteString) .|
CL.map (<> "\n") .|
CL.isolate lineCount .|
appSink app))
handlerSink app
parser = do
len <- P.anyWord8
return (fromIntegral len * 1000)
在这里,它只是从输入中读出一个word8的值为 "n thousand"。然后我们以流的方式加载fake-db.csv ,将字节转换为CSV行,为每一行查找"Name" 字段,如果有的话,给每个名字加一个换行,然后isolate ,获取lineCount 结果。
让我们在启用运行时选项的情况下编译它:
stack ghc ./sql-dummy.hs --resolver lts-12.12 -- -rtsopts
并用统计输出来运行它。下面是我们要求1000行时发生的情况。
$ ./sql-dummy +RTS -s
Someone connected!
1000
9,149,904 bytes allocated in the heap
36,848 bytes copied during GC
120,112 bytes maximum residency (2 sample(s))
35,680 bytes maximum slop
2 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 7 colls, 0 par 0.000s 0.000s 0.0001s 0.0001s
Gen 1 2 colls, 0 par 0.000s 0.001s 0.0004s 0.0006s
INIT time 0.000s ( 0.000s elapsed)
MUT time 0.022s ( 4.387s elapsed)
GC time 0.001s ( 0.001s elapsed)
EXIT time 0.000s ( 0.000s elapsed)
Total time 0.023s ( 4.388s elapsed)
%GC time 2.4% (0.0% elapsed)
Alloc rate 422,940,926 bytes per MUT second
Productivity 96.2% of total user, 100.0% of total elapsed
这是我们要求2,000行时的情况,通过:
$ printf '\x02' | nc 127.0.0.1 2019
我们得到:
$ ./sql-dummy +RTS -s
Someone connected!
2000
18,125,240 bytes allocated in the heap
43,656 bytes copied during GC
120,112 bytes maximum residency (2 sample(s))
35,680 bytes maximum slop
2 MB total memory in use (0 MB lost due to fragmentation)
Tot time (elapsed) Avg pause Max pause
Gen 0 16 colls, 0 par 0.000s 0.001s 0.0000s 0.0001s
Gen 1 2 colls, 0 par 0.000s 0.001s 0.0003s 0.0006s
INIT time 0.000s ( 0.000s elapsed)
MUT time 0.029s ( 6.247s elapsed)
GC time 0.001s ( 0.001s elapsed)
EXIT time 0.000s ( 0.000s elapsed)
Total time 0.030s ( 6.248s elapsed)
%GC time 2.5% (0.0% elapsed)
Alloc rate 628,824,590 bytes per MUT second
Productivity 96.6% of total user, 100.0% of total elapsed
以下是不同之处:
- 我们做了两倍的垃圾回收,正如你所期望的那样。
- 在整个程序运行过程中,后一个程序分配的总量是前者的两倍。
- 但是在这两种情况下,最大驻留量(120KB)保持不变。这就是在特定时间内所占用的内存的数量。
这意味着,我们的总驻留内存使用量从未超过CSV中最大行的大小。对于一个需要提高内存效率和洗刷大量数据的服务器来说,这是很完美的。
绕过来
让我们回头看看我们最初的目标:
- 制作一个假的SQL服务器。我们看了TDS协议和一些如何工作的例子。
- 要有干净、简单的代码库。我们看了一些很好的库,它们可以很好地连接在一起以实现这一目标。
- 要有一个流式结构,以便内存的使用是恒定的。我们看了一个真实的代码样本,它是如何工作的以及我们看到的结果。
开发经验很顺利,因为我们能够专注于重要的事情,比如手头的协议,而不是边界、缓冲区大小、规模问题或内存问题。
