

这是我参与「第四届青训营 」笔记创作活动的的第1天
本次笔记重点内容
-
- 大数据体系和 SQL
-
- 常见的查询优化器
大数据体系: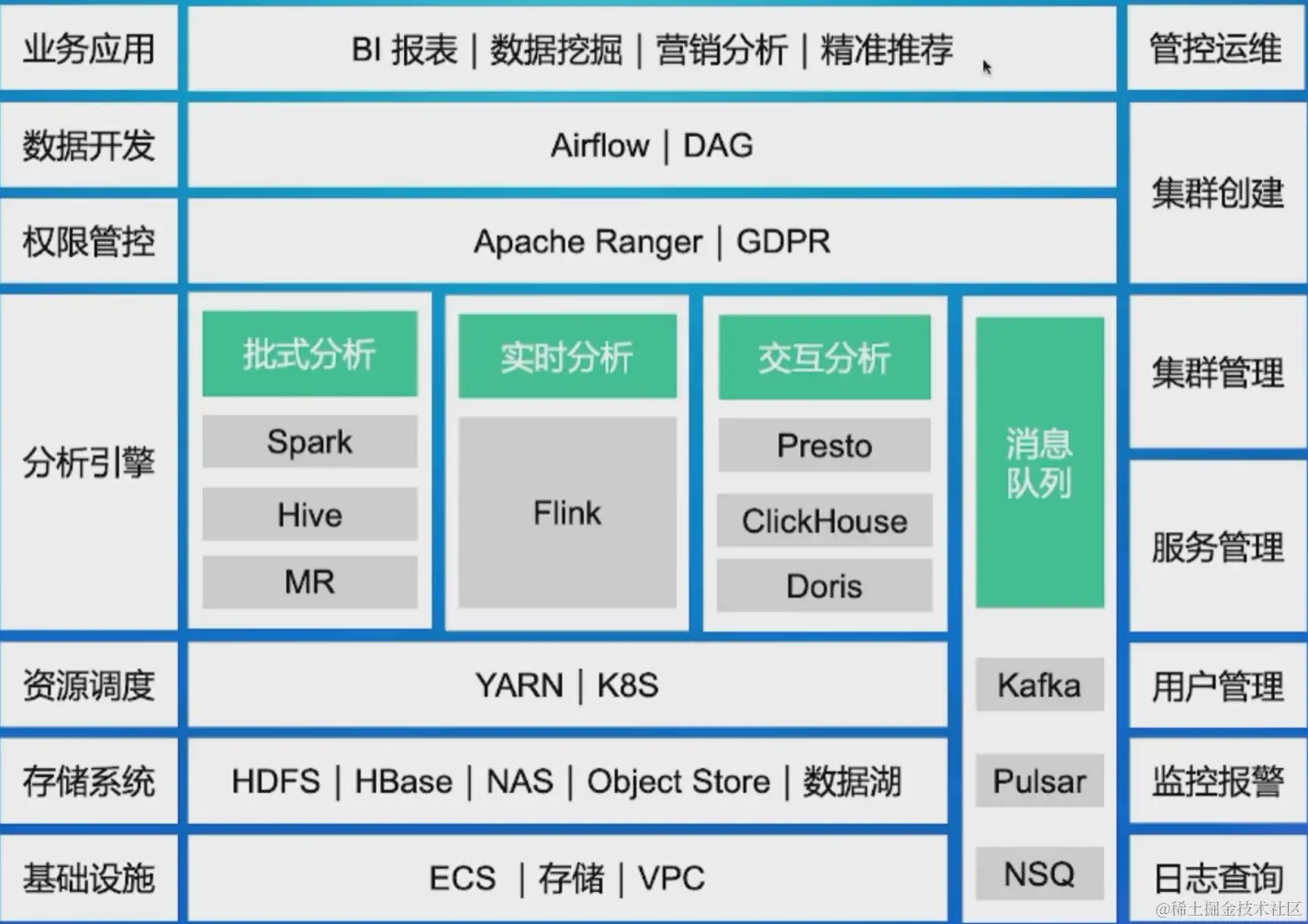
SQL 介绍
简而言之:SQL其实就是上图分析引擎那一整块,是一种具有数据操纵和数据定义等多种功能的数据库语言
SQL处理流程
Parser
将字符串变为AST(抽象语法树——树型结构能够“记住”源程序全部的“意思”,更容易对应到运行时结构。):词法分析+语法分析,所谓词法分析就是从连续的字符中识别出标识符、关键字、数字、运算符并存储为符号(token)流,语法分析就是从词法分析识别出的符号流中识别出符合C语言语法的语句,将token组成AST的节点。
Analyzer and Logical plan(Left-deep Tree)
- SQL合法性检查,将AST变为一个Logical plan
- 逻辑地描述SQL对应的分步骤计算操作(算子)
查询优化
- 优化原因:用户没有告诉数据库怎么做!
- 查询优化器是数据库的大脑,要找到一个正确且运行最快的物理执行计划
- 为什么说查询优化是最复杂的一步:要考虑SQL里面各种语法,各种边界情况,还有很多问题是NP的(没法求得最优解)
Physical plan and Executor
- 最小化网络数据传输
- 利用数据亲和性
- 增加Shuffle算子
查询优化器分类
按遍历计划树的顺序划分:
Top-down Optimizer
从目标输出开始,由上往下找到完整的最优执行计划
Bottom-up Optimizer
从零开始,由下往上找到完整的执行计划
按优化方法划分:
RBO
根据关系代数等价语义来估算执行计划代价,关系代数是定义了一个或多个的集合以及针对这些集合的一套运算规则,是sql语言的理论基础,本身为解决运算问题。
- 优化I/O:读更少的数据且更快
- 优化网络:传输数据更少更快
- 优化CPU & Memory:处理数据CPU指令和使用的内存更少
缺点:容易导致内存溢出,就是你要求分配的内存超出了系统能给你的。
CBO
使用一个模型来估算执行计划代价
统计信息
- 原始表统计信息:表/分区级别、列级别,直接给scan算子用
- 推导统计信息:选择率(查询从表中返回数据的比率)、基数(查询中算子要处理的行数),给scan之前过程中的算子用
统计信息收集方式
- DDL里指定
缺点:实时更新插入数据慢
- 手动执行 explain analyze statement
缺点:手动导致统计信息过时
- 动态采样
规则:
易错点:literal < min: 0 的意思是不存在比最小值还小的情况,literal > max: 1 的意思是取了所有情况。还要注意的是红色的那句,列不一定是均匀分布的,这种不是的情况下可用直方图处理。
执行计划
- 逻辑计划阶段(Optimizer)
——主要基于规则(RBO)
- 列裁剪
减少scan的数据量
project开始裁剪自己需要的列传到filter,filter把自己需要的列加入形成新的列集合,再往下...到scan就是一个全新的列集合,根据要求在这个列集合中继续选择扫描,所以需要扫描的数据会大大减少。
- 谓词下推
谓词就是where中的表达式
将过滤条件下推到离数据源更近的地方:
把filter变成join的子节点,做到提前过滤,但不是所有都可以下推。
- 传递闭包
- Runtime Filter
后面两种方法比较高级。
- 物理计划阶段(SparkPlanner)
——逻辑计划在 Spark 里面其实并不能被执行,为了能够执行这个 SQL,一定需要翻译成物理计划,到这个阶段 Spark 就知道如何执行这个 SQL 了。
