

这是我参与「第四届青训营 」笔记创作活动的的第1天,本文主要摘录了课程一些重点知识,并对进行简单的个人总结
第一节:SQL Optimizer解析
关键字 :SQL查询优化器
01.大数据体系和SQL:
1.1 大数据体系和SQL
简单介绍了一下大数据体系以及SQL在其中的重要性,俺也不懂,俺也不敢说啥,直接上图
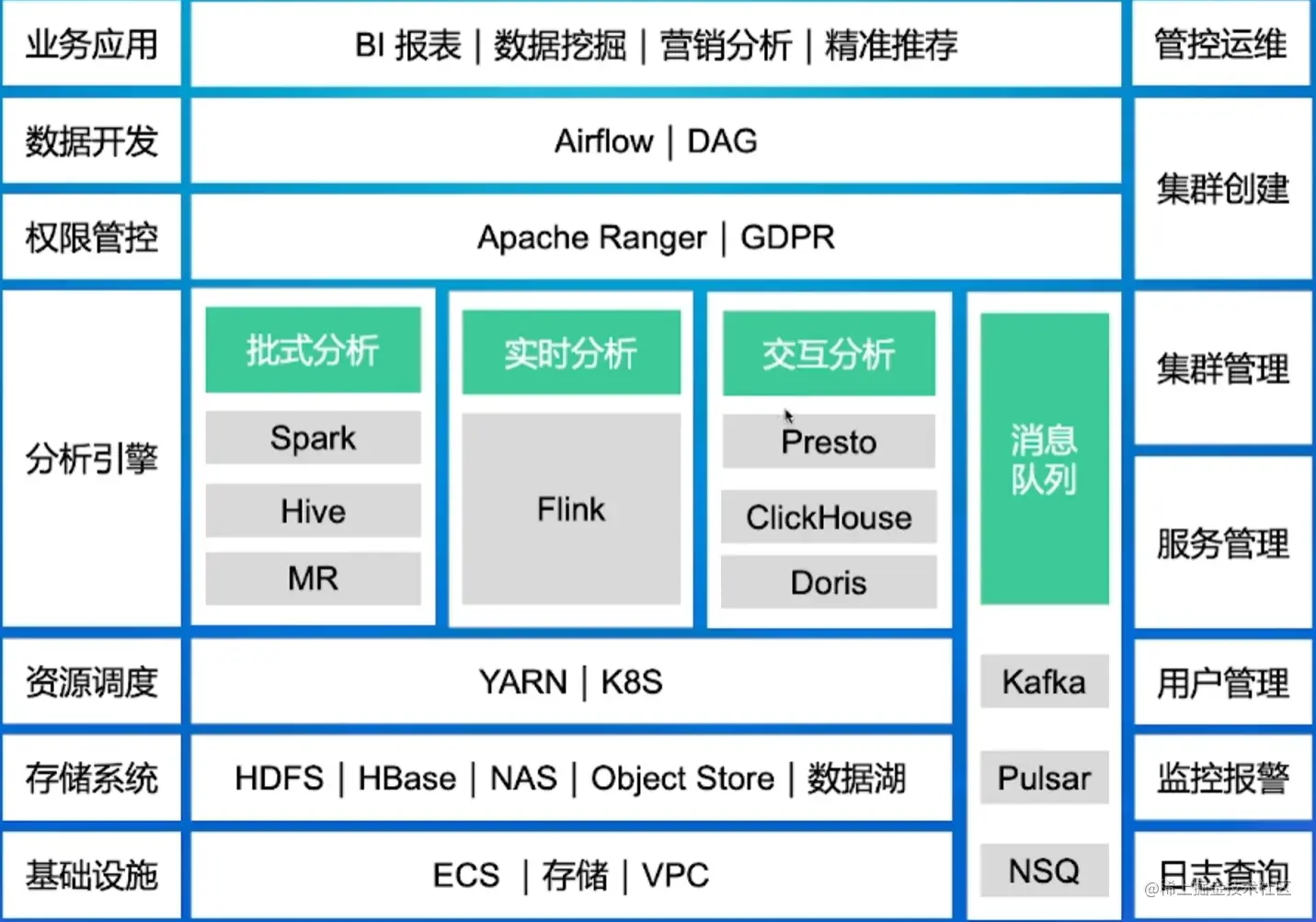 1.2 SQL的处理流程
1.2 SQL的处理流程
Parser: SQL→AST(词法/语法分析得到抽象语法树)
Analyzer:AST→Logical Plan 主要就是对输入的信息进行检查然后输出分析后的逻辑算子树
Optimizer:查询优化器 Logic Plan→Physical Plan
将一系列优化规则应用在逻辑算子树中,确保结果正确的前提下改进低效结构,生成优化后的逻辑算子树(找到一个正确且执行代价最小的物理执行计划)
Executor:执行输入的执行计划子树 有单机并行和多机并行
1.3 小结
简单记住sql的处理流程就好,其中本节重点分析查询优化器,知道查询优化器的重要性
02.常见的查询优化器
2.1 优化器的分类
有两种分类方式:按照计划树的遍历顺序分类(Top-down、Buttom-up)和按###分(俺也不懂,反正重点讲这个的两种)(基于规则的优化器(Rule-Based Optimizer,RBO) 和基于代价的优化器(Cost-Based Optimizer,CBO))
- 基于规则的优化器(Rule-Based Optimizer,RBO)
根据优化规则对关系表达式进行转换,这里的转换是说一个关系表达式经过优化规则后会变成另外一个关系表达式,同时原有表达式会被裁剪掉,经过一系列转换后生成最终的执行计划。
- 基于代价的优化器(Cost-Based Optimizer,CBO)
根据优化规则对关系表达式进行转换,这里的转换是说一个关系表达式经过优化规则后会生成另外一个关系表达式,同时原有表达式也会保留,经过一系列转换后会生成多个执行计划,然后CBO会根据统计信息和代价模型(Cost Model)计算每个执行计划的Cost,从中挑选Cost最小的执行计划。由上可知,CBO中有两个依赖:统计信息和代价模型。统计信息的准确与否、代价模型的合理与否都会影响CBO选择最优计划。
2.2 RBO
基于规则的优化器(Rule-Based Optimizer,RBO)
常见的优化方法(逐渐高级化)
列裁剪:根据已知的的一些条件可以初步裁剪掉一些数据(尽可能的减少数据)
谓词下推:将过滤条件尽早执行(提前执行减少后续数据量)
传递闭包:根据已有的表达式推导出新的过滤条件(这样就是找理由去对数据砍一刀)
Runtime:这个不是很理解,在运行是去找到一些数据过滤条件然后应用到其他要执行的数据上(min-max(要求数据范围紧密)、in-list(注意list大小)、bloom filter(固定大小 后面存储引擎那块详细介绍))
2.3 CBO
基于代价的优化器(Cost-Based Optimizer,CBO)
使用一个模型估算执行计划的代价,选择代价最小的执行计划
简单介绍统计信息的3种收集方式和简要概括了推导规则(具体问题具体分析)
通常使用贪心算法或者动态规划选出最优的执行计划
2.4 小结
个人理解:
RBO是想到是什么优化规则就加上去优化就好,所以就是实现简单想到啥就做,也因为太直男思考不全面而不能保证这一系列优化是最优执行计划;
CBO是个强迫症,他都是把n个系列的优化计划列出来,然后看哪个好,那个好选哪个,因此他往往带来的好处是能对性能的提升达到最大化,因此在大数据场景下CBO对查询性能非常重要
03.社区开源实践
本部分见到简单介绍了一些社区开源实践,描述了常见的数据库中查询优化器的应用,然后以Apache Calcite 为例分析其中的查询优化器是如何
小结
这里具体分析常见的优化器应用实例,对于具体例子不是很了解所以不敢bb,这里应该就是为了让我们知道主流的查询优化器应用实例告诉我们很重要,然后简单介绍Apache Calcite 中RBO的一些优化规则(Pattern:匹配表达式子树、等价变换:得到新的表达式等100+优化规则)然后强调一下RBO的优缺点(优化速度快,实现简单,但是不保证最优 )
04.前沿趋势
前景广阔,大家都快去学!
课程总结:
第一节课初步认识了大数据体系,了解SQL查询优化器的作用、分类、以及具体如何实现。
听了之后就是很好很牛逼,我是小垃圾。谢谢各位巨佬观看,也希望各巨佬不吝珠玉。
