

卷积神经网络在机器学习中非常重要。如果你想做计算机视觉或图像识别任务,你根本离不开它们。但要了解它们的工作原理可能很难。
在这篇文章中,我们将谈论卷积神经网络背后的机制,它们的好处和商业用例。
什么是神经网络?
首先,让我们了解一下神经网络的一般工作原理。
任何神经网络,从简单的感知器到巨大的企业人工智能系统,都由模仿人脑中的神经元的节点组成。这些细胞是紧密相连的。节点也是如此。
.png)
神经元通常被组织成独立的层。神经网络的一个例子是前馈网络。数据从输入层通过一组隐藏层,只在一个方向移动,就像水通过过滤器一样。
_(1).png)
系统中的每个节点都与上一层和下一层的一些节点相连。节点从它下面的层接收信息,对它做一些事情,并将信息发送到下一层。
每个传入的连接都被分配一个权重。这是一个数字,当节点收到来自不同节点的数据时,它将输入乘以这个数字。
_(1).png)
通常有几个传入的值是节点正在处理的。然后,它把所有的东西加起来。
.png)
有几种可能的方法来决定输入是否应该被传递到下一层。例如,如果你使用单位步长函数,如果其数值低于阈值,节点就不把数据传给下一层。如果数字超过阈值,节点就将数字向前发送。然而,在其他情况下,神经元可以简单地将输入投射到某个固定值段。
当一个神经网第一次被训练时,其所有的权重和阈值都是随机分配的。一旦训练数据被送入输入层,它就会经过所有层,最后到达输出。在训练过程中,权重和阈值被调整,直到具有相同标签的训练数据持续提供类似的输出。这就是所谓的反向传播。你可以在TensorFlow Playground中看到它是如何工作的。
简单的NN有什么问题?
常规的人工神经网络不能很好地扩展。例如,在CIFAR(一个通常用于训练计算机视觉模型的数据集)中,图像的大小只有32x32 px,有3个颜色通道。这意味着在这个神经网络的第一隐藏层中,一个全连接的神经元将有32x32x3=3072个权重。这仍然是可控的。但现在想象一个更大的图像,例如,300x300x3。它将有27万个权重(训练这些权重需要大量的计算能力)!
像这样一个巨大的神经网络需要大量的资源,但即使如此,仍然容易出现过度拟合,因为大量的参数使它能够记住数据集。
CNN使用参数共享。一个特定特征图中的所有神经元共享权重,这使得整个系统的计算强度降低。
CNN是如何工作的?
卷积神经网络,或ConvNet,只是一个使用卷积的神经网络。为了理解这个原理,我们先用一个二维卷积来工作。
什么是卷积?
卷积是一种数学运算,它允许两组信息的合并。在CNN的案例中,卷积被应用于输入数据以过滤信息并产生一个特征图。
_(1).png)
这个过滤器也被称为内核,或特征检测器,其尺寸可以是,例如,3x3。为了进行卷积,内核在输入图像上做矩阵乘法,一个元素接着一个元素。每个感受区(发生卷积的区域)的结果都写在特征图上。
.png)
我们继续滑动过滤器,直到特征图完成。
填充和滑动
在我们进一步讨论之前,谈谈填充和滑动也是有用的。这些技术在CNN中经常被使用。
- 填充。 填充是通过在矩阵的边界上添加假的像素来扩大输入矩阵。这样做是因为卷积减少了矩阵的大小。例如,一个5x5的矩阵在滤波后会变成3x3的矩阵。
- 漫步。 在使用卷积层工作时,经常会发生这样的情况,你需要得到一个比输入小的输出。实现这一目的的方法之一是使用池化层。另一种实现的方法是使用striding。stride背后的想法是在内核滑过时跳过一些区域:例如,每2或3个像素跳过一次。 它降低了空间分辨率,使网络的计算效率更高。
填充和跨步可以帮助更准确地处理图像。
关于CNN如何工作的更详细解释,请观看Brandon Rohrer的机器学习课程的这一部分。
对于现实生活中的任务,卷积通常是在三维中进行的。大多数图像有3个维度:高度、宽度和深度,其中深度对应的是颜色通道(RGB)。所以卷积过滤器也需要是3维的。下面是同样的操作在三维中的样子。
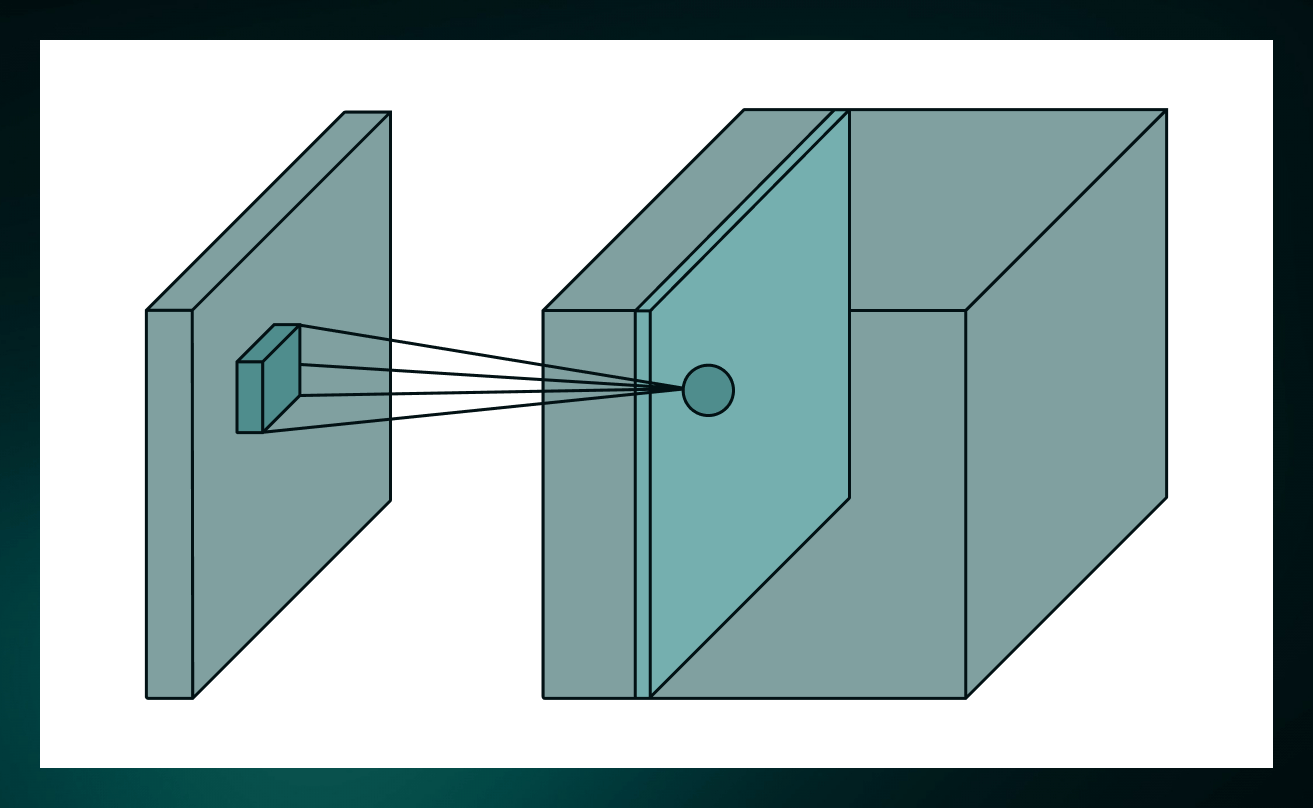
卷积层中有多个过滤器,每个过滤器都会生成一个过滤图。因此,一个层的输出将是一组滤波图,相互堆叠在一起。
例如,将一个30x30x3的矩阵填充并通过10个滤波器,将产生一组30x30x1的矩阵。在我们将这些图叠加在一起后,我们将得到一个30x30x10的矩阵。
这就是我们卷积层的输出。
这个过程可以重复进行。CNN通常有一个以上的卷积层。
3层的CNN
CNN的目标是减少图像,使其更容易处理,同时不失去对准确预测有价值的特征。
ConvNet架构有三种层:卷积层、池化层和全连接层。
- 卷积层负责识别像素中的特征。
- 池化层负责使这些特征更加抽象。
- 全连接层负责使用获得的特征进行预测。
.png)
卷积层
我们已经在上面描述了卷积层的工作原理。它们是CNN的中心,使它们能够自主地识别图像中的特征。
但经历卷积过程会产生大量的数据,这使得神经网络难以训练。为了压缩数据,我们需要通过池化。
池化层
池化层接收卷积层的结果并进行压缩。池化层的过滤器总是比特征图小。通常,它取一个2x2的正方形(补丁)并将其压缩成一个值。
一个2x2的过滤器会将每个特征图的像素数减少到四分之一的大小。如果你有一个大小为10×10的特征图,输出的图将是5×5。
多个不同的函数可用于汇集。这些是最常见的。
- 最大集合(Maximum Pooling)。它为特征图的每个补丁计算最大值。
- 平均池化。它计算特征图上每个斑块的平均值。
使用池化层后,你会得到池化的特征图,它是输入中检测到的特征的一个总结版本。池化层提高了CNN的稳定性:如果以前像素的轻微波动都会导致模型分类错误,那么现在卷积层检测到的输入中的特征位置的微小变化将导致池化特征图中的特征在同一位置。
现在我们需要对输入进行扁平化处理(将其变成一个列向量),并将其传递给普通神经网络进行分类。
全连接层
扁平化的输出被送入一个前馈神经网络,并在每次训练迭代时应用反向传播法。这一层为模型提供了最终理解图像的能力:每个输入像素和每个输出类别之间都有信息流。
卷积神经网络的优势
卷积神经网络有几个优点,使它们对许多不同的应用都很有用。如果你想在实践中看到它们,请看StatQuest的这个详尽解释。
特征学习
CNN不需要手动的特征工程:它们可以在训练中掌握相关的特征。即使你正在处理一个全新的任务,你也可以使用预先训练好的CNN,并通过向它输入数据,调整权重。CNN会根据新的任务进行自我调整。
计算效率
由于卷积的程序,CNN的计算效率比普通的神经网络高得多。CNN使用参数共享和降维,这使得模型易于快速部署。它们可以被优化以在任何设备上运行,甚至在智能手机上。
高精确度
目前在图像分类中最先进的NN不是卷积网,例如,在图像变换器中。然而,CNN现在已经在关于图像和视频识别以及类似任务的大多数情况和任务中占据了很长时间的优势。它们通常比非卷积网络显示出更高的准确性,特别是在涉及大量数据的时候。
ConvNet的缺点
然而,ConvNet并不完美。即使它看起来是一个非常智能的工具,它仍然容易受到对抗性攻击。
对抗性攻击
对抗性攻击是指向网络提供 "坏 "的例子(又称以特定方式稍作修改的图像),以造成错误分类的情况。即使是像素的轻微移动也能使CNN发疯。例如,犯罪分子可以骗过基于CNN的人脸识别系统,在摄像头前通过而不被识别。
.png)
数据密集型训练
为使CNN展示其神奇的力量,它们需要大量的训练数据。这种数据不容易收集和预处理,这可能是该技术广泛采用的一个障碍。这就是为什么即使在今天,也只有几个好的预训练模型,如GoogleNet、VGG、Inception、AlexNet。大多数都是由全球企业拥有的。
卷积神经网络的用途是什么?
卷积神经网络在许多行业都有应用。以下是它们在现实生活中应用的一些常见例子。
图像分类
卷积神经网络经常被用于图像分类。通过识别有价值的特征,CNN可以识别图像上的不同物体。这种能力使它们在医学上很有用,例如,用于核磁共振诊断。CNN也可用于农业。这些网络接收来自LSAT等卫星的图像,并可以利用这些信息根据土地的耕作水平进行分类。因此,这些数据可用于预测土地的肥沃程度或制定优化使用农田的策略。手写数字识别也是CNN在计算机视觉方面最早的用途之一。
.png)
物体检测
自动驾驶汽车、人工智能驱动的监控系统和智能家居经常使用CNN,能够识别和标记物体。CNN可以识别照片上的物体,并实时对其进行分类和标记。这就是自动驾驶汽车如何绕过其他汽车和行人,以及智能家居如何在所有其他人中识别主人的脸。
.png)
音频视觉匹配
YouTube、Netflix和其他视频流媒体服务使用音频视觉匹配来改善他们的平台。有时,用户的要求可能非常具体,例如,"关于太空中的僵尸的电影",但搜索引擎甚至应该满足这种奇特的要求。
物体重建
你可以使用CNN对数字空间中的真实物体进行3D建模。今天,有一些CNN模型,只需基于一张图片就能创建3D脸部模型。类似的技术可用于创建数字双胞胎,这在建筑、生物技术和制造业中很有用。
语音识别
尽管CNN经常被用来处理图像,但这并不是它们唯一可能的用途。ConvNet可以帮助进行语音识别和自然语言处理。例如,Facebook的语音识别技术是基于卷积神经网络的。
总结
总而言之,卷积神经网络是计算机视觉和类似领域的一个了不起的工具,因为它们能够识别原始数据的特征。
它们可以识别训练数据中不同像素之间的联系,并利用这些信息自行设计特征,从低层次(边缘、圆圈)到高层次(脸、手、汽车)。
问题是这些特征对人类来说可能变得相当难以理解。此外,图像中的一个野生像素有时会导致新的令人惊讶的结果。
