

要在安装后开始玩GE,我们需要创建数据上下文。这是GE的中央配置点,存储所有的验证规则和数据源。
Great Expectations提供了两种与它的API互动的方式:
- 代码--允许我们充分使用GE的功能。
- CLI-易于使用,对于大多数用例和需要一些代码的地方来说相当强大。例如,在创建Expectations套件时,CLI将重定向到Jupyter Notebook。
在大多数时候,我们会坚持使用CLI:
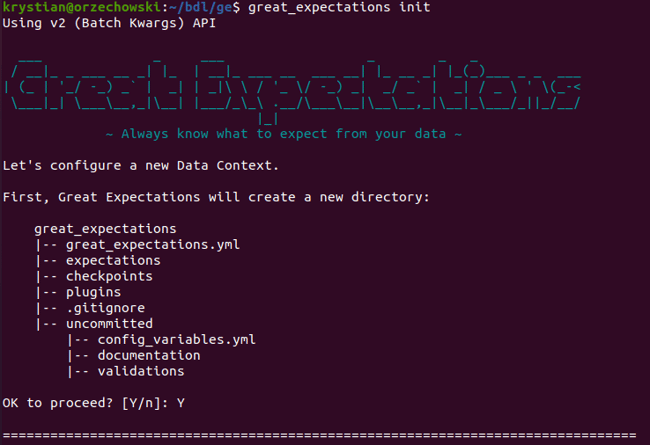
输入great_expectations init命令将初始化一个新的数据上下文。
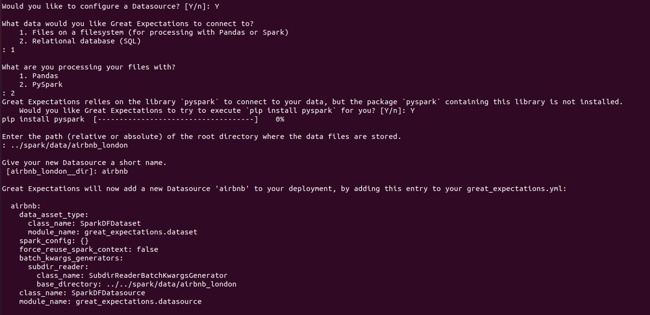
创建数据源配置,存储所有的数据源信息,可以在init阶段或通过运行great_expectations datasource new 命令来实现:
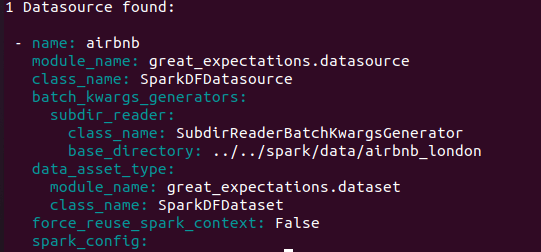
接下来,让我们运行great_expectations datasource list命令。我们可以列出我们的数据源,如下所示:
现在,我们可以通过使用命令脚手架来创建一些新的预期,如下图所示:
great_expectations suite scaffold airbnb
经过一些处理后,一个提示应该将我们重定向到一个新的Jupyter笔记本:

我们可以运行Expectations,它是根据GE的数据分析功能自动生成的。然而,它们并不打算在生产中运行,因为它们只是根据数据的统计属性生成的,可能不会实现任何有意义的目的。因此,它们应该作为定义一些更有意义的期望值的基础。
我们可以通过向批处理对象添加Expectations来实现,批处理对象是SparkDFDataset的一个实例,持有对spark dataFrame的一些引用。
运行每个单元后,GE应该在浏览器的新标签中启动Data Docs。
让我们以如下方式修改上述代码。
我替换了默认的batch_kwargs,删除了 "datasource "旁边的所有参数,并添加了带有模式的 DataFrame(我找不到直接将模式加载到 Great_Expectations 的方法)。这是通过将解析CSV直接移到spark.csv方法中来完成的,而不是让GE自己去解析它。这样一来,我们就可以获得正确标注的列:
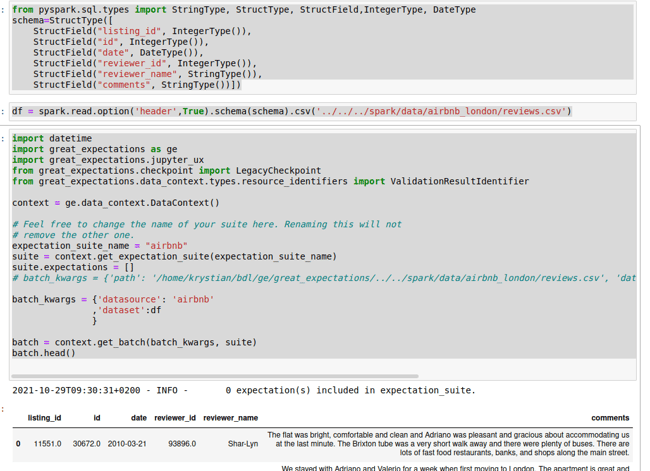
现在,我们可以定义一些 "期望"。
在运行最后一个单元格后,我们将被重定向到浏览器,并生成一个数据文件:
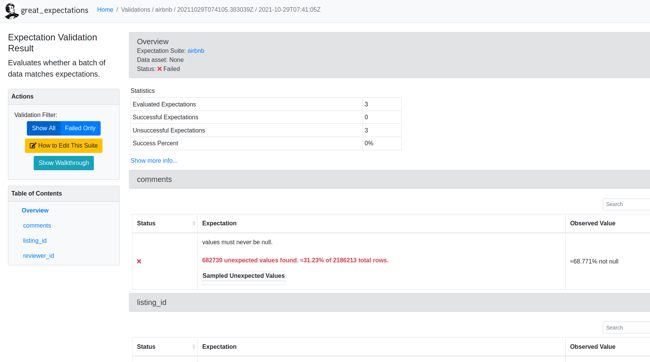
这里我们可以看到一些失败的期望值。事实上,所有这些都失败了,因为所有这些提到的列都包含一些空数据。现在,为了继续进行,我们需要删除这些空数据。
