

本文旨在介绍哈希表(Hash table)的基本原理与内部机制,并使用Java实现它的增删改查。
什么是哈希表?
哈希表(Hash table,也叫散列表),是一种能够通过键值(Key)直接访问内存储存位置的数据结构,查找效率很高,在理想情况下,查找元素的复杂度为O(1)。
哈希表可以看做是数组+链表的结合体,理想情况下,哈希表拥有着数组的查找效率O(1)和链表的修改效率O(1)。
| 哈希表(最佳情况) | 哈希表(最差情况) | 数组 | 链表 | |
|---|---|---|---|---|
| 查找 | O(1) | O(N) | O(1) | O(N) |
| 修改 | O(1) | O(N) | O(N) | O(1) |
当然,如果哈希函数的设计非常糟糕,以至于所有元素都在一个位置,那它也同时拥有数组和链表的缺点。
哈希表的基本原理
简单来说,哈希表就是通过哈希函数来确定元素的下标,然后将元素存储到对应的索引位置。当你需要查一个元素的时候,你就可以直接通过哈希函数计算你要查找的key值所在的下标位置,从而实现快速的元素查找。
什么是哈希函数?
哈希函数是哈希表的核心,理解了什么是哈希函数,也就理解了哈希表。
简单来说,哈希函数的作用就是将任意的数据转化为一个int类型的整数。
对于Java来说,就是说无论你传入的是对象、数值、字符串甚至是null,哈希函数都会通过计算并返回一个int类型的值。
哈希表怎么存数据?
哈希表能过通过哈希函直接得到元素的下标值,这是一个随机访问过程,所以哈希表首先肯定是一个数组。
但是,一个数组肯定是不够的,因为哈希函数虽然会尽可能地保证不同元素会被分到不同地位置,可还是会出现两个不同的元素被分到相同下标的情况。
这时,我们就需要把两个元素放在数组的一个下标位置,面对这种需求,链表是最合适不过的了,我们只需要把数组上的元素当作链表头,把后来的元素链接在后面。
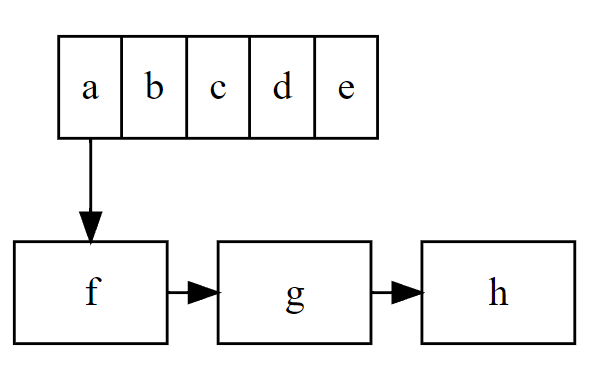
如果需要查找一个元素,只需要计算key得到对应下标,然后遍历这个下标位置的链表就可以完成查找,同样很快速。
哈希表的Java简单实现
这里我主要实现一下哈希表的增删改查操作,且不涉及红黑树,仅使用数组+链表的结构。
基本结构

这里有个问题需要注意,如果将Node声明为MyHashTabke的非静态内部类,Node应该是持有外围类MyHashTable的泛型类型,可以直接使用<K,V>,但是实际上,如果想要实例化一个Node类型的数组赋值给elements,就必须要给Node也声明泛型类型,然后再将Node类型的数组强转成MyHashTable的<K, V>。
// 能够正常编译运行
public class MyHashTable<K, V> {
elements = (Node<K, V>[]) new Node[capacity];
private class Node<K, V> {
...
}
}
//报错 Generic array creation
public class MyHashTable<K, V> {
elements = (Node<K, V>[]) new Node[capacity];
private class Node {
...
}
}
这是因为声明泛型数组时,编译器需要确定泛型类型,而Node如果不加上<K,V>,编译器就不能确定Node内部的泛型到底是什么,而加上<K,V>,直接声明new Node[capacity],会得到一个Node<Object,Object>类型的数组,再将其强转成MyHashTable中的<K,V>,就得到了一个Node<K,V>数组。
这里我也没有找到确定的解释,如果你知道如何解释这个问题,欢迎留言交流。
实际上,这里将Node声明为一个静态内部类是更好的做法,Java中的HashMap就是这样做的。
增:put方法
put方法的代码逻辑如下:
- 在放进元素时,首先要判断哈希表是否需要扩容,即 哈希表中的元素/数组的长度 > 装载因子
- 是,就扩容
- 根据元素key值的哈希值计算元素对应的下标
- 把元素放入对应的下标位置
- 如果该位置没有元素,那么直接放
- 如果该位置有元素,就放在链表尾
- 添加成功。
代码
/**
* 添加元素
*
* @param key
* @param value
*/
public void put(K key, V value) {
//判断数组是否需要扩容
if (size * 1.0 / elements.length > factor) {
//扩容
resize();
}
//把新元素放进数组中
Node<K, V> e = (Node<K, V>) new Node(key, value);
//根据hash计算下标值
int index = e.hash % elements.length;
//判断数组的这个位置是否有元素了
if (elements[index] == null) {
//没有元素,直接放
elements[index] = e;
} else {
//有元素,放到链表尾
Node<K, V> node = elements[index];
while (node.next != null) {
node = node.next;
}
node.next = e;
}
//更新size
size++;
}
删:remove方法
代码逻辑
- 根据传入的key计算下标
- 找到对应的下标位置,查找要删除的元素
- 找到,删除,删除成功 (这个删除操作需要注意,要分情况处理)
- 没找到,删除失败
代码
/**
* 删除元素
*
* @param key
*/
public void remove(K key) {
//先计算下标
int index = key.hashCode() % elements.length;
//去下标位置找
Node<K, V> node = elements[index];
//父结点
Node<K, V> f = null;
while (node != null) {
//判断key是否相等
if (Objects.equals(key, node.key)) {
//只有一个结点
if (f == null && node.next == null) {
elements[index] = null;
}
//有多个结点,要删的是头节点
if (f == null && node.next != null) {
elements[index] = node.next;
}
//多个结点,但删的是中间结点
if (f != null && node.next != null) {
f.next = node.next;
}
//有多个结点,要删的是尾节点
if (f != null && node.next == null) {
f.next = null;
}
//打印删除成功
System.out.println("删除成功");
size--;
return;
}
//不相等,就往链表后面找
f = node;
node = node.next;
}
//没找到就打印个没有这个元素
System.out.println("删除失败,没找到这个元素");
}
改:set方法
基本与remove逻辑类似,找到后修改即可。
代码
/**
* 改元素
*
* @param key
* @param value
*/
public void set(K key, V value) {
//先计算下标值
int index = key.hashCode() % elements.length;
//对应下标位置找元素
Node<K, V> node = elements[index];
while (node != null) {
if (Objects.equals(key, node.key)) {
//找到就改
node.value = value;
//打印修改成功
System.out.println("修改成功");
return;
}
//元素后移
node = node.next;
}
//找不到就打印没找到
System.out.println("没找到这个元素");
}
查:get方法
代码逻辑类似
/**
* 查
* @param key
* @return
*/
public V get(K key) {
//先计算下标值
int index = key.hashCode() % elements.length;
//对应下标位置找元素
Node<K, V> node = elements[index];
while (node != null) {
if (Objects.equals(key, node.key)) {
//找到就返回
return node.value;
}
//元素后移
node = node.next;
}
//找不到就返回null
return null;
}
附:完整代码
package com.structure.hashtable;
import java.util.Objects;
/**
* @Classname MyHashTable
* @Description hashtable的增删改查的简单实现
* @Date 2022/7/19 21:52
* @Created by Yang Yi-zhou
*/
public class MyHashTable<K, V> {
//数组
Node<K, V>[] elements;
//元素个数
int size;
//默认容量
int capacity = 4;
//填装因子
double factor = 0.7;
public MyHashTable() {
//初始化元素个数
size = 0;
//初始化数组 ★★★★★ 记住这个写法! Node声明为静态泛型内部类
elements = (Node<K, V>[]) new Node[capacity];
}
/**
* 查
* @param key
* @return
*/
public V get(K key) {
//先计算下标值
int index = key.hashCode() % elements.length;
//对应下标位置找元素
Node<K, V> node = elements[index];
while (node != null) {
if (Objects.equals(key, node.key)) {
//找到就返回
return node.value;
}
//元素后移
node = node.next;
}
//找不到就返回null
return null;
}
/**
* 改元素
*
* @param key
* @param value
*/
public void set(K key, V value) {
//先计算下标值
int index = key.hashCode() % elements.length;
//对应下标位置找元素
Node<K, V> node = elements[index];
while (node != null) {
if (Objects.equals(key, node.key)) {
//找到就改
node.value = value;
//打印修改成功
System.out.println("修改成功");
return;
}
//元素后移
node = node.next;
}
//找不到就打印没找到
System.out.println("没找到这个元素");
}
/**
* 删除元素
*
* @param key
*/
public void remove(K key) {
//先计算下标
int index = key.hashCode() % elements.length;
//去下标位置找
Node<K, V> node = elements[index];
//父结点
Node<K, V> f = null;
while (node != null) {
//判断key是否相等
if (Objects.equals(key, node.key)) {
//只有一个结点
if (f == null && node.next == null) {
elements[index] = null;
}
//有多个结点,要删的是头节点
if (f == null && node.next != null) {
elements[index] = node.next;
}
//多个结点,但删的是中间结点
if (f != null && node.next != null) {
f.next = node.next;
}
//有多个结点,要删的是尾节点
if (f != null && node.next == null) {
f.next = null;
}
//打印删除成功
System.out.println("删除成功");
size--;
return;
}
//不相等,就往链表后面找
f = node;
node = node.next;
}
//没找到就打印个没有这个元素
System.out.println("删除失败,没找到这个元素");
}
/**
* 添加元素
*
* @param key
* @param value
*/
public void put(K key, V value) {
//判断数组是否需要扩容
if (size * 1.0 / elements.length > factor) {
//扩容
resize();
}
//把新元素放进数组中
Node<K, V> e = (Node<K, V>) new Node(key, value);
//根据hash计算下标值
int index = e.hash % elements.length;
//判断数组的这个位置是否有元素了
if (elements[index] == null) {
//没有元素,直接放
elements[index] = e;
} else {
//有元素,放到链表尾
Node<K, V> node = elements[index];
while (node.next != null) {
node = node.next;
}
node.next = e;
}
//更新size
size++;
}
/**
* 扩容数组
*/
private void resize() {
//新的capacity为旧的两倍(这里我就不考虑最大限制这些复杂情况了,只是做一个简单的实现)
int newCapacity = capacity * 2;
//创建新数组
Node<K, V>[] newEle = (Node<K, V>[]) new Node[newCapacity];
//把旧数组中的元素放到新数组中
//遍历旧数组中的元素
for (Node e : elements) {
//如果数组为空,跳过
if (e == null) continue;
//根据hash计算下标值
int index = e.hash % newEle.length;
//判断数组的这个位置是否有元素了
if (newEle[index] == null) {
//没有元素,直接放
newEle[index] = e;
} else {
//有元素,放到链表尾
Node<K, V> node = newEle[index];
while (node.next != null) {
node = node.next;
}
node.next = e;
}
}
//把新数组赋给旧数组
capacity = newCapacity;
elements = newEle;
}
private static class Node<K, V> {
//key
K key;
//value
V value;
//哈希值
int hash;
//指向后一个结点
Node next;
public Node() {
//hash值只取决于key
this.hash = this.key == null ? 0 : this.key.hashCode();
this.next = null;
}
public Node(K key, V value) {
this.key = key;
this.value = value;
this.hash = this.key == null ? 0 : this.key.hashCode();
this.next = null;
}
}
}
